淘宝OceanBase设计
OceanBase有什么特点
OceanBase设计和实现的时候暂时摒弃了许多不需要的DBMS的功能,例如临时表,视图(view),SQL语言支持等,这使得研发团队能够把有限的资源集中到关键的功能上,例如数据一致性、高性能的跨表事务、范围查询、join等(更多的信息以及其开源的软件:http://oceanbase.taobao.org/)。
虽然数据总量比较大,但跟许多行业一样,淘宝业务一段时间(例如小时或天)内数据的增删改是有限的(通常一天不超过几千万次到几亿次),根据这个特点,OceanBase把一段时间内的增删改等修改操作以增量形式记录下来(称之为动态数据,通常保存在内存中),这样也使得了主体数据在一段时间内保持了相对稳定(称之为基准数据)。
由于动态数据相对较小,通常情况下,OceanBase把它保存在独立的服务器UpdateServer的内存中。以内存保存增删改记录极大地提高了系统写事务的性能。此外,假如每条修改平均消耗100 Bytes,那么10GB内存可以记录100M(即1亿)条修改,且扩充UpdateServer内存即增加了内存中容纳的修改量。不仅如此,由于冻结后的内存表不再修改,它也可以转换成sstable格式并保存到SSD固态盘或磁盘上。转储到SSD固态盘后所占内存即可释放,并仍然可以提供较高性能的读服务,这也缓解了极端情况下UpdateServer的内存需求。为了应对机器故障,动态数据服务器UpdateServer写commit log并采取双机(甚至多机)热备。由于UpdateServer的主备机是同步的,因此备机也可同时提供读服务。
因为基准数据相对稳定,OceanBase把它按照主键(primary key,也称为row key)分段(即tablet)后保存多个副本(一般是3个)到多台机器(ChunkServer)上,避免了单台机器故障导致的服务中断,多个副本也提升了系统服务能力。单个tablet的尺寸可以根据应用数据特点进行配置,相对配置过小的tablet会合并,过大的tablet则会分裂。
由于tablet按主键分块连续存放,因此OceanBase按主键的范围查询对应着连续的磁盘读,十分高效。
对于已经冻结/转储的动态数据,OceanBase的ChunkServer会在自己不是太繁忙的时候启动基准数据与冻结/转储内存表的合并,并生成新的基准数据。这种合并过程其实是一种范围查询,是一串连续的磁盘读和连续的磁盘写,也是很高效的。
传统DBMS提供了强大的事务性、良好的一致性和很短的查询修改响应时间,但数据规模受到严重制约,缺乏扩展性;现代云计算提供了极大的数据规模、良好的扩展性,但缺乏跨行跨表事务、数据一致性也较弱、查询修改响应时间通常也较长,OceanBase的设计和实现融合了二者的优势:
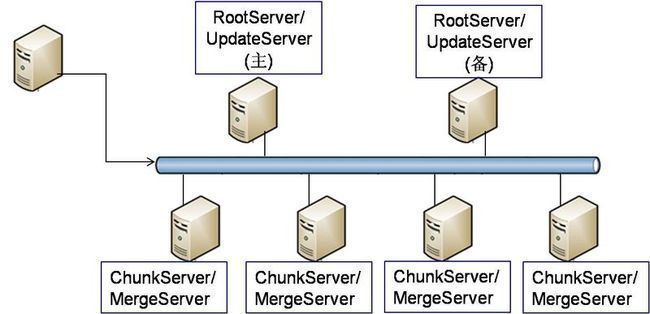
- UpdateServer:类似于DBMS中的DB角色,提供跨行跨表事务和很短的查询修改的响应时间以及良好的一致性
- ChunkServer:类似于云计算中的工作机(如GFS的chunk server),具有数据多副本(通常是3)、中等规模数据粒度(tablet大小约256MB)、自动负载平衡、宕机恢复、机器plug and play等特点,系统容量及性能可随时扩展
- MergeServer:结合ChunkServer和UpdateServer,获得最新数据,实现数据一致性
- RootServer:类似于云计算中的主控机(如GFS master),进行机器故障检测、负载平衡计算、负载迁移调度等
上述的DBMS和云计算技术的优势互补使得OceanBase既具有传统DBMS的跨行跨表事务、数据的强一致性以及很短的查询修改响应时间,还有云计算的海量数据管理能力、自动故障恢复、自动负载平衡以及良好的扩展性。
OceanBase逻辑架构简图
主键
row key,也称为primary key,类似于DBMS的主键,与DBMS不同的是,OceanBase的主键总是二进制字符串(binary string),但可以有某种结构。OceanBase以主键为顺序存放表格数据
sstable
一种数据存储格式,OceanBase用来存储一个或几个表的一段按主键连续的数据
tablet
一个表按主键划分的一个(前开后闭的)范围,通常包含一个或几个sstable,一个tablet的数据量通常在256MB左右
基准数据和动态数据
OceanBase以增量方式记录一段时间内的表格数据的增删改,从而保持着表格主体数据在一段时间内相对稳定,其中增删改的数据称为动态数据(通常在内存,也称为内存表),而一段时间内相对稳定的主体数据称为基准数据,基准数据和转储后(保存到SSD固态盘或磁盘)的动态数据以sstable格式存储
ChunkServer
保存基准数据的服务器,通常是多台,为了避免软件硬件故障导致的服务中断,同一份基准数据通常保存了3份并存储在不同ChunkServer上
UpdateServer
保存动态数据的服务器,一般是单台服务器。为了避免软件硬件故障导致的服务中断,UpdateServer记录commit log并通常使用双机热备
MergeServer
进行静态动态数据合并的服务器,常常与ChunkServer共用一台物理服务器。MergeServer使得用户能够访问到完整的最新的数据
RootServer
配置服务器,一般是单台服务器。为了避免软件硬件故障导致的服务中断,RootServer记录commit log并通常采用双机热备。由于RootServer负载一般都很轻,所以它常常与UpdateServer共用物理机器
冻结
指动态数据(也称为内存表)的更新到一定时间或者数据量达到一定规模后,OceanBase停止该块动态数据的修改,后续的更新写入新的动态数据块(即新的内存表),旧的动态数据块不再修改,这个过程称为冻结
转储
出于节省内存或者持久化等原因将一个冻结的动态数据块(内存表)持久化(转化为sstable并保存到SSD固态盘货磁盘上)的过程
数据合并(merge)
查询时,查询项的基准数据与其动态数据(即增删改操作)合并以得到该数据项的最新结果的过程。此外,把旧的基准数据与冻结的动态数据进行合并生成新的基准数据的过程也称为数据合并
联表(join)
一张表与另一张或几表连接的关系,类似于DBMS的自然连接
COW
Copy on Write的缩写,在OceanBase中特指BTree在更新时复制数据备份写入,避免系统锁的技术手段
OceanBase解决什么问题
许多公司的核心资产是各种各样的商业数据,例如淘宝的商品、交易、订单、购物爱好等等,这些数据通常是结构化的,并且数据之间存在各种各样的关联,传统的关系数据库曾经是这些数据的最佳载体。然而,随着业务的快速发展,这些数据急剧膨胀,记录数从几千万条增加到数十亿条,数据量从百GB增加到数TB,未来还可能增加到数千亿条和数百TB,传统的关系型数据库已经无法承担如此海量的数据。许多公司,尤其是互联网公司,正在探索各自的解决之路。
一个思路是通过类似map-reduce模型进行处理,例如Google的 GFS+MapReduce以及Hadoop的HDFS+MapReduce。这类方式为离线数据处理及挖掘提供了一个不错的选择,但难以满足在线实时服务系统的需求。
另一个思路降低一致性来换取数据规模,例如BigTable和HBase实现了单行事务的海量数据的存储访问,Amazon的Dynamo以及由Facebook开源的Cassandra实现了最终一致性,这类系统常常被称为NoSQL数据库,它们在一些网站(例如Google,Facebook和Twitter等)得到了应用。
一个新近出现的系统是Google的Percolator,它在GFS/BigTable基础上实现了海量数据(PB级)的分布式事务。由于Google并没有把Percolator开源,其他公司无法使用它,此外事务响应时间偏长(平均2s-5s)以及单机效率低(Google声称Percolator的效率大致为DBMS的1/30)也限制了Percolator的使用(更多信息,请参见Daniel Peng和Frank Dabek的“Large-scale Incremental Processing Using Distributed Transactions and Notifications”一文)。
从Eric Brewer教授的CAP(一致性C: Consistency, 可用性A: Availability,分区容错性P: Tolerance of network Partition)理论来看,第一种思路重点在于支持CP特性,第二种思路重点在于支持AP特性。作为电子商务企业,淘宝和其他公司的业务对一致性和可用性的要求高于分区容错性,数据总量庞大且逐步增加,单位时间内的数据更新量并不大,但实时性要求很高。这些需求建议我们提供一套更加偏重于支持CA特性的系统,同时兼顾可分区性,并且在实时性、成本、性能等方面表现良好。