如果你不熟悉这个术语,那么“正则表达式”(Regular Expression)就是一个字符构成的串,它定义了一个用来搜索匹配字符串的模式。
| 许多语言,包括Perl、PHP、Python、JavaScript和JScript,都支持用正则表达式处理文本,一些文本编辑器用正则表达式实现高级“搜索-替换”功能。那么Java又怎样呢?本文写作时,一个包含了用正则表达式进行文本处理的Java规范需求(Specification Request)已经得到认可,你可以期待在JDK的下一版本中看到它。 |
| 然而,如果现在就需要使用正则表达式,又该怎么办呢?你可以从Apache.org下载源代码开放的Jakarta-ORO库。本文接下来的内容先简要地介绍正则表达式的入门知识,然后以Jakarta-ORO API为例介绍如何使用正则表达式。 |
| 我们先从简单的开始。假设你要搜索一个包含字符“cat”的字符串,搜索用的正则表达式就是“cat”。如果搜索对大小写不敏感,单词“catalog”、“Catherine”、“sophisticated”都可以匹配。也就是说: |
| 假设你在玩英文拼字游戏,想要找出三个字母的单词,而且这些单词必须以“t”字母开头,以“n”字母结束。另外,假设有一本英文字典,你可以用正则表达式搜索它的全部内容。要构造出这个正则表达式,你可以使用一个通配符——句点符号“.”。这样,完整的表达式就是“t.n”,它匹配“tan”、“ten”、“tin”和“ton”,还匹配“t#n”、“tpn”甚至“t n”,还有其他许多无意义的组合。这是因为句点符号匹配所有字符,包括空格、Tab字符甚至换行符: |
| 为了解决句点符号匹配范围过于广泛这一问题,你可以在方括号(“[]”)里面指定看来有意义的字符。此时,只有方括号里面指定的字符才参与匹配。也就是说,正则表达式“t[aeio]n”只匹配“tan”、“Ten”、“tin”和“ton”。但“Toon”不匹配,因为在方括号之内你只能匹配单个字符: |
| 如果除了上面匹配的所有单词之外,你还想要匹配“toon”,那么,你可以使用“|”操作符。“|”操作符的基本意义就是“或”运算。要匹配“toon”,使用“t(a|e|i|o|oo)n”正则表达式。这里不能使用方扩号,因为方括号只允许匹配单个字符;这里必须使用圆括号“()”。圆括号还可以用来分组,具体请参见后面介绍。 |
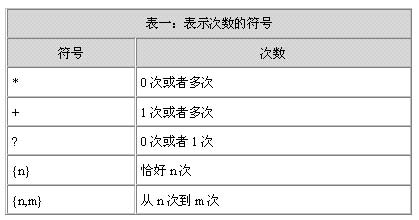
| 表一显示了表示匹配次数的符号,这些符号用来确定紧靠该符号左边的符号出现的次数: |
| 假设我们要在文本文件中搜索美国的社会安全号码。这个号码的格式是999-99-9999。用来匹配它的正则表达式如图一所示。在正则表达式中,连字符(“-”)有着特殊的意义,它表示一个范围,比如从0到9。因此,匹配社会安全号码中的连字符号时,它的前面要加上一个转义字符“\”。 |
| 图一:匹配所有123-12-1234形式的社会安全号码 |
| 假设进行搜索的时候,你希望连字符号可以出现,也可以不出现——即,999-99-9999和999999999都属于正确的格式。这时,你可以在连字符号后面加上“?”数量限定符号,如图二所示: |
| 图二:匹配所有123-12-1234和123121234形式的社会安全号码 |
| 下面我们再来看另外一个例子。美国汽车牌照的一种格式是四个数字加上二个字母。它的正则表达式前面是数字部分“[0-9]{4}”,再加上字母部分“[A-Z]{2}”。图三显示了完整的正则表达式。 |
| “^”符号称为“否”符号。如果用在方括号内,“^”表示不想要匹配的字符。例如,图四的正则表达式匹配所有单词,但以“X”字母开头的单词除外。 |
| 假设要从格式为“June 26, 1951”的生日日期中提取出月份部分,用来匹配该日期的正则表达式可以如图五所示: |
| 新出现的“\s”符号是空白符号,匹配所有的空白字符,包括Tab字符。如果字符串正确匹配,接下来如何提取出月份部分呢?只需在月份周围加上一个圆括号创建一个组,然后用ORO API(本文后面详细讨论)提取出它的值。修改后的正则表达式如图六所示: |
| 图六:匹配所有Month DD,YYYY格式的日期,定义月份值为第一个组 |
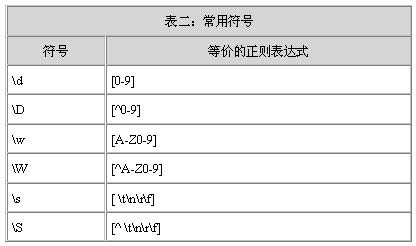
| 为简便起见,你可以使用一些为常见正则表达式创建的快捷符号。如表二所示: |
| 例如,在前面社会安全号码的例子中,所有出现“[0-9]”的地方我们都可以使用“\d”。修改后的正则表达式如图七所示: |
| 图七:匹配所有123-12-1234格式的社会安全号码 |
| 有许多源代码开放的正则表达式库可供Java程序员使用,而且它们中的许多支持Perl 5兼容的正则表达式语法。我在这里选用的是Jakarta-ORO正则表达式库,它是最全面的正则表达式API之一,而且它与Perl 5正则表达式完全兼容。另外,它也是优化得最好的API之一。 |
| Jakarta-ORO库以前叫做OROMatcher,Daniel Savarese大方地把它赠送给了Jakarta Project。你可以按照本文最后参考资源的说明下载它。 |
| 我首先将简要介绍使用Jakarta-ORO库时你必须创建和访问的对象,然后介绍如何使用Jakarta-ORO API。 |
| 首先,创建一个Perl5Compiler类的实例,并把它赋值给PatternCompiler接口对象。Perl5Compiler是PatternCompiler接口的一个实现,允许你把正则表达式编译成用来匹配的Pattern对象。 |
| 要把正则表达式编译成Pattern对象,调用compiler对象的compile()方法,并在调用参数中指定正则表达式。例如,你可以按照下面这种方式编译正则表达式“t[aeio]n”: |
| 默认情况下,编译器创建一个大小写敏感的模式(pattern)。因此,上面代码编译得到的模式只匹配“tin”、“tan”、 “ten”和“ton”,但不匹配“Tin”和“taN”。要创建一个大小写不敏感的模式,你应该在调用编译器的时候指定一个额外的参数: |
| 创建好Pattern对象之后,你就可以通过PatternMatcher类用该Pattern对象进行模式匹配。 |
| PatternMatcher对象根据Pattern对象和字符串进行匹配检查。你要实例化一个Perl5Matcher类并把结果赋值给PatternMatcher接口。Perl5Matcher类是PatternMatcher接口的一个实现,它根据Perl 5正则表达式语法进行模式匹配: |
| 使用PatternMatcher对象,你可以用多个方法进行匹配操作,这些方法的第一个参数都是需要根据正则表达式进行匹配的字符串: |
| · boolean matches(String input, Pattern pattern):当输入字符串和正则表达式要精确匹配时使用。换句话说,正则表达式必须完整地描述输入字符串。 |
| · boolean matchesPrefix(String input, Pattern pattern):当正则表达式匹配输入字符串起始部分时使用。 |
| · boolean contains(String input, Pattern pattern):当正则表达式要匹配输入字符串的一部分时使用(即,它必须是一个子串)。 |
| 另外,在上面三个方法调用中,你还可以用PatternMatcherInput对象作为参数替代String对象;这时,你可以从字符串中最后一次匹配的位置开始继续进行匹配。当字符串可能有多个子串匹配给定的正则表达式时,用PatternMatcherInput对象作为参数就很有用了。用PatternMatcherInput对象作为参数替代String时,上述三个方法的语法如下: |
| · boolean matches(PatternMatcherInput input, Pattern pattern) |
| · boolean matchesPrefix(PatternMatcherInput input, Pattern pattern) |
| · boolean contains(PatternMatcherInput input, Pattern pattern) |
| 下面我们来看看Jakarta-ORO库的一些应用实例。 |
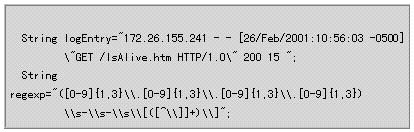
| 任务:分析一个Web服务器日志文件,确定每一个用户花在网站上的时间。在典型的BEA WebLogic日志文件中,日志记录的格式如下: |
| 分析这个日志记录,可以发现,要从这个日志文件提取的内容有两项:IP地址和页面访问时间。你可以用分组符号(圆括号)从日志记录提取出IP地址和时间标记。 |
| 首先我们来看看IP地址。IP地址有4个字节构成,每一个字节的值在0到255之间,各个字节通过一个句点分隔。因此,IP地址中的每一个字节有至少一个、最多三个数字。图八显示了为IP地址编写的正则表达式: |
| IP地址中的句点字符必须进行转义处理(前面加上“\”),因为IP地址中的句点具有它本来的含义,而不是采用正则表达式语法中的特殊含义。句点在正则表达式中的特殊含义本文前面已经介绍。 |
| 日志记录的时间部分由一对方括号包围。你可以按照如下思路提取出方括号里面的所有内容:首先搜索起始方括号字符(“[”),提取出所有不超过结束方括号字符(“]”)的内容,向前寻找直至找到结束方括号字符。图九显示了这部分的正则表达式。 |
| 现在,把上述两个正则表达式加上分组符号(圆括号)后合并成单个表达式,这样就可以从日志记录提取出IP地址和时间。注意,为了匹配“- -”(但不提取它),正则表达式中间加入了“\s-\s-\s”。完整的正则表达式如图十所示。 |
| 现在正则表达式已经编写完毕,接下来可以编写使用正则表达式库的Java代码了。 |
| 为使用Jakarta-ORO库,首先创建正则表达式字符串和待分析的日志记录字符串: |
| 这里使用的正则表达式与图十的正则表达式差不多完全相同,但有一点例外:在Java中,你必须对每一个向前的斜杠(“\”)进行转义处理。图十不是Java的表示形式,所以我们要在每个“\”前面加上一个“\”以免出现编译错误。遗憾的是,转义处理过程很容易出现错误,所以应该小心谨慎。你可以首先输入未经转义处理的正则表达式,然后从左到右依次把每一个“\”替换成“\\”。如果要复检,你可以试着把它输出到屏幕上。 |
| 初始化字符串之后,实例化PatternCompiler对象,用PatternCompiler编译正则表达式创建一个Pattern对象: |
| 现在,创建PatternMatcher对象,调用PatternMatcher接口的contain()方法检查匹配情况: |
| 接下来,利用PatternMatcher接口返回的MatchResult对象,输出匹配的组。由于logEntry字符串包含匹配的内容,你可以看到类如下面的输出: |
| 下面一个任务是分析HTML页面内FONT标记的所有属性。HTML页面内典型的FONT标记如下所示: |
| 程序将按照如下形式,输出每一个FONT标记的属性: |
| 在这种情况下,我建议你使用两个正则表达式。第一个如图十一所示,它从字体标记提取出“"face="Arial, Serif" size="+2" color="red"”。 |
| 第二个正则表达式如图十二所示,它把各个属性分割成名字-值对。 |
| 现在我们来看看完成这个任务的Java代码。首先创建两个正则表达式字符串,用Perl5Compiler把它们编译成Pattern对象。编译正则表达式的时候,指定Perl5Compiler.CASE_INSENSITIVE_MASK选项,使得匹配操作不区分大小写。 |
| 接下来,创建一个执行匹配操作的Perl5Matcher对象。 |
| 假设有一个String类型的变量html,它代表了HTML文件中的一行内容。如果html字符串包含FONT标记,匹配器将返回true。此时,你可以用匹配器对象返回的MatchResult对象获得第一个组,它包含了FONT的所有属性: |
| 接下来创建一个PatternMatcherInput对象。这个对象允许你从最后一次匹配的位置开始继续进行匹配操作,因此,它很适合于提取FONT标记内属性的名字-值对。创建PatternMatcherInput对象,以参数形式传入待匹配的字符串。然后,用匹配器实例提取出每一个FONT的属性。这通过指定PatternMatcherInput对象(而不是字符串对象)为参数,反复地调用PatternMatcher对象的contains()方法完成。PatternMatcherInput对象之中的每一次迭代将把它内部的指针向前移动,下一次检测将从前一次匹配位置的后面开始。 |
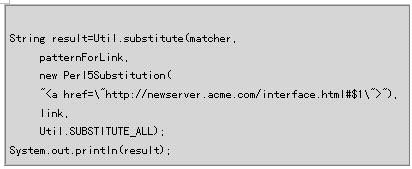
| 下面我们来看看另一个处理HTML的例子。这一次,我们假定Web服务器从widgets.acme.com移到了newserver.acme.com。现在你要修改一些页面中的链接: |
| 如果能够匹配这个正则表达式,你可以用下面的内容替换图十三的链接: |
| 注意#字符的后面加上了$1。Perl正则表达式语法用$1、$2等表示已经匹配且提取出来的组。图十三的表达式把所有作为一个组匹配和提取出来的内容附加到链接的后面。 |
现在,返回Java。就象前面我们所做的那样,你必须创建测试字符串,创建把正则表达式编译到Pattern对象所必需的对象,以及创建一个PatternMatcher对象: |
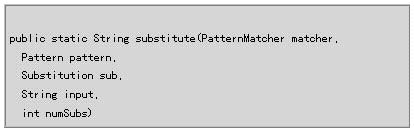
| 接下来,用com.oroinc.text.regex包Util类的substitute()静态方法进行替换,输出结果字符串: |
| Util.substitute()方法的语法如下: |
| 这个调用的前两个参数是以前创建的PatternMatcher和Pattern对象。第三个参数是一个Substiution对象,它决定了替换操作如何进行。本例使用的是Perl5Substitution对象,它能够进行Perl5风格的替换。第四个参数是想要进行替换操作的字符串,最后一个参数允许指定是否替换模式的所有匹配子串(Util.SUBSTITUTE_ALL),或只替换指定的次数。 |
| 【结束语】在这篇文章中,我为你介绍了正则表达式的强大功能。只要正确运用,正则表达式能够在字符串提取和文本修改中起到很大的作用。另外,我还介绍了如何在Java程序中通过Jakarta-ORO库利用正则表达式。至于最终采用老式的字符串处理方式(使用StringTokenizer,charAt,和substring),还是采用正则表达式,这就有待你自己决定了。 |
常用正则表达式
说明:正则表达式通常用于两种任务:1.验证,2.搜索/替换。用于验证时,通常需要在前后分别加上^和$,以匹配整个待验证字符串;搜索/替换时是否加上此限定则根据搜索的要求而定,此外,也有可能要在前后加上\b而不是^和$。此表所列的常用正则表达式,除个别外均未在前后加上任何限定,请根据需要,自行处理。
正则表达式(英文:Regular Expression)在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。
说明 正则表达式
| 网址(URL) |
[a-zA-z]+://[^\s]* |
| IP地址(IP Address) |
((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?) |
| 电子邮件(Email) |
\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* |
| QQ号码 |
[1-9]\d{4,} |
| HTML标记(包含内容或自闭合) |
<(.*)(.*)>.*<\/\1>|<(.*) \/> |
| 密码(由数字/大写字母/小写字母/标点符号组成,四种都必有,8位以上) |
(?=^.{8,}$)(?=.*\d)(?=.*\W+)(?=.*[A-Z])(?=.*[a-z])(?!.*\n).*$ |
| 日期(年-月-日) |
(\d{4}|\d{2})-((1[0-2])|(0?[1-9]))-(([12][0-9])|(3[01])|(0?[1-9])) |
| 日期(月/日/年) |
((1[0-2])|(0?[1-9]))/(([12][0-9])|(3[01])|(0?[1-9]))/(\d{4}|\d{2}) |
| 时间(小时:分钟, 24小时制) |
((1|0?)[0-9]|2[0-3]):([0-5][0-9]) |
| 汉字(字符) |
[\u4e00-\u9fa5] |
| 中文及全角标点符号(字符) |
[\u3000-\u301e\ufe10-\ufe19\ufe30-\ufe44\ufe50-\ufe6b\uff01-\uffee] |
| 中国大陆固定电话号码 |
(\d{4}-|\d{3}-)?(\d{8}|\d{7}) |
| 中国大陆手机号码 |
1\d{10} |
| 中国大陆邮政编码 |
[1-9]\d{5} |
| 中国大陆身份证号(15位或18位) |
\d{15}(\d\d[0-9xX])? |
| 非负整数(正整数或零) |
\d+ |
| 正整数 |
[0-9]*[1-9][0-9]* |
| 负整数 |
-[0-9]*[1-9][0-9]* |
| 整数 |
-?\d+ |
| 小数 |
(-?\d+)(\.\d+)? |
| 不包含abc的单词 |
\b((?!abc)\w)+\b |
以上正则表达式均经过多次测试,并不断增加,因为不同程序或工具的正则表达式略有区别,大家可以根据需要进行简单修改
常用正则表达式
正则表达式用于字符串处理、表单验证等场合,实用高效。现将一些常用的表达式收集于此,以备不时之需。
用户名:/^[a-z0-9_-]{3,16}$/
密码:/^[a-z0-9_-]{6,18}$/
十六进制值:/^#?([a-f0-9]{6}|[a-f0-9]{3})$/
电子邮箱:/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
URL:/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
IP 地址:/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
HTML 标签:/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/
Unicode编码中的汉字范围:/^[u4e00-u9fa5],{0,}$/
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行
匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^\s*|\s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国大陆邮政编码:[1-9]\d{5}(?!\d)
评注:中国大陆邮政编码为6位数字
匹配身份证:\d{15}|\d{18}
评注:中国大陆的身份证为15位或18位
匹配ip地址:\d+\.\d+\.\d+\.\d+
评注:提取ip地址时有用
匹配特定数字:
^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
表达式全集
正则表达式有多种不同的风格。下表是在PCRE中元字符及其在正则表达式上下文中的行为的一个完整列表:
字符 描述
\
| 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。序列“\\”匹配“\”而“\(”则匹配“(”。 |
^
| 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
$
| 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
*
| 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,}。 |
+
| 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
?
| 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
{n}
| n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
{n,}
| n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
{n,m}
| m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
?
| 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 |
.
| 匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“[.\n]”的模式。 |
(pattern)
| 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。 |
(?:pattern)
| 匹配pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分是很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
(?=pattern)
| 正向预查,在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
(?!pattern)
| 负向预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
x|y
| 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”。 |
[xyz]
| 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
[^xyz]
| 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“p”。 |
[a-z]
| 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 |
[^a-z]
| 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
\b
| 匹配一个单词边界,也就是指单词和空格间的位置。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
\B
| 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
\cx
| 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
\d
| 匹配一个数字字符。等价于[0-9]。 |
\D
| 匹配一个非数字字符。等价于[^0-9]。 |
\f
| 匹配一个换页符。等价于\x0c和\cL。 |
\n
| 匹配一个换行符。等价于\x0a和\cJ。 |
\r
| 匹配一个回车符。等价于\x0d和\cM。 |
\s
| 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]。 |
\S
| 匹配任何非空白字符。等价于[^\f\n\r\t\v]。 |
\t
| 匹配一个制表符。等价于\x09和\cI。 |
\v
| 匹配一个垂直制表符。等价于\x0b和\cK。 |
\w
| 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。 |
\W
| 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
\xn
| 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。. |
\num
| 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 |
\n
| 标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。 |
\nm
| 标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。 |
\nml
| 如果n为八进制数字(0-3),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
\un
| 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(?)。 |
以下是以PHP的语法所写的示例
验证字符串是否只含数字与英文,字符串长度并在4~16个字符之间
<?php
$str = 'a1234';
if (preg_match("^[a-zA-Z0-9]{4,16}$", $str)) {
echo "验证成功";
} else {
echo "验证失敗";
}
?>
简易的台湾身份证字号验证
<?php
$str = 'a1234';
if (preg_match("/^\w[12]\d{8}$/", $str)) {
echo "验证成功";
} else {
echo "验证失敗";
}
?>
以下示例是用 Perl 语言写的,与上面的示例功能相同
print $str = "a1234" =~ m:^[a-zA-Z0-9]{4,16}$: ? "COMFIRM" : "FAILED";
print $str = "a1234" =~ m"^\w[12]\d{8}$" ? "COMFIRM" : "INVAILD";
如何写出高效率的正则表达式
如果纯粹是为了挑战自己的正则水平,用来实现一些特效(例如使用正则表达式计算质数、解线性方程),效率不是问题;如果所写的正则表达式只是为了满足一两次、几十次的运行,优化与否区别也不太大。但是,如果所写的正则表达式会百万次、千万次地运行,效率就是很大的问题了。我这里总结了几条提升正则表达式运行效率的经验(工作中学到的,看书学来的,自己的体会),贴在这里。如果您有其它的经验而这里没有提及,欢迎赐教。
为行文方便,先定义两个概念。
误匹配:指正则表达式所匹配的内容范围超出了所需要范围,有些文本明明不符合要求,但是被所写的正则式“击中了”。例如,如果使用\d{11}来匹配11位的手机号,\d{11}不单能匹配正确的手机号,它还会匹配98765432100这样的明显不是手机号的字符串。我们把这样的匹配称之为误匹配。
漏匹配:指正则表达式所匹配的内容所规定的范围太狭窄,有些文本确实是所需要的,但是所写的正则没有将这种情况囊括在内。例如,使用\d{18}来匹配18位的身份证号码,就会漏掉结尾是字母X的情况。
写出一条正则表达式,既可能只出现误匹配(条件写得极宽松,其范围大于目标文本),也可能只出现漏匹配(只描述了目标文本中多种情况种的一种),还可能既有误匹配又有漏匹配。例如,使用\w+\.com来匹配.com结尾的域名,既会误匹配abc_.com这样的字串(合法的域名中不含下划线,\w包含了下划线这种情况),又会漏掉ab-c.com这样的域名(合法域名中可以含中划线,但是\w不匹配中划线)。
精准的正则表达式意味着既无误匹配且无漏匹配。当然,现实中存在这样的情况:只能看到有限数量的文本,根据这些文本写规则,但是这些规则将会用到海量的文本中。这种情况下,尽可能地(如果不是完全地)消除误匹配以及漏匹配,并提升运行效率,就是我们的目标。本文所提出的经验,主要是针对这种情况。
掌握语法细节。正则表达式在各种语言中,其语法大致相同,细节各有千秋。明确所使用语言的正则的语法的细节,是写出正确、高效正则表达式的基础。例如,perl中与\w等效的匹配范围是[a-zA-Z0-9_];perl正则式不支持肯定逆序环视中使用可变的重复(variable repetition inside lookbehind,例如(?<=.*)abc),但是.Net语法是支持这一特性的;又如,JavaScript连逆序环视(Lookbehind,如(?<=ab)c)都不支持,而perl和python是支持的。《精通正则表达式》第3章《正则表达式的特性和流派概览》明确地列出了各大派系正则的异同,这篇文章也简要地列出了几种常用语言、工具中正则的比较。对于具体使用者而言,至少应该详细了解正在使用的那种工作语言里正则的语法细节。
先粗后精,先加后减。使用正则表达式语法对于目标文本进行描述和界定,可以像画素描一样,先大致勾勒出框架,再逐步在局步实现细节。仍举刚才的手机号的例子,先界定\d{11},总不会错;再细化为1[358]\d{9},就向前迈了一大步(至于第二位是不是3、5、8,这里无意深究,只举这样一个例子,说明逐步细化的过程)。这样做的目的是先消除漏匹配(刚开始先尽可能多地匹配,做加法),然后再一点一点地消除误匹配(做减法)。这样有先有后,在考虑时才不易出错,从而向“不误不漏”这个目标迈进。
留有余地。所能看到的文本sample是有限的,而待匹配检验的文本是海量的,暂时不可见的。对于这样的情况,在写正则表达式时要跳出所能见到的文本的圈子,开拓思路,作出“战略性前瞻”。例如,经常收到这样的垃圾短信:“发*票”、“发#漂”。如果要写规则屏蔽这样烦人的垃圾短信,不但要能写出可以匹配当前文本的正则表达式 发[*#](?:票|漂),还要能够想到 发.(?:票|漂|飘)之类可能出现的“变种”。这在具体的领域或许会有针对性的规则,不多言。这样做的目的是消除漏匹配,延长正则表达式的生命周期。
明确。具体说来,就是谨慎用点号这样的元字符,尽可能不用星号和加号这样的任意量词。只要能确定范围的,例如\w,就不要用点号;只要能够预测重复次数的,就不要用任意量词。例如,写析取twitter消息的脚本,假设一条消息的xml正文部分结构是<span class=”msg”>…</span>且正文中无尖括号,那么<span class=”msg”>[^<]{1,480}</span>这种写法的思路要好于<span class=”msg”>.*</span>,原因有二:一是使用[^<],它保证了文本的范围不会超出下一个小于号所在的位置;二是明确长度范围,{1,480},其依据是一条twitter消息大致能的字符长度范围。当然,480这个长度是否正确还可推敲,但是这种思路是值得借鉴的。说得狠一点,“滥用点号、星号和加号是不环保、不负责任的做法”。
不要让稻草压死骆驼。每使用一个普通括号()而不是非捕获型括号(?:…),就会保留一部分内存等着你再次访问。这样的正则表达式、无限次地运行次数,无异于一根根稻草的堆加,终于能将骆驼压死。养成合理使用(?:…)括号的习惯。
宁简勿繁。将一条复杂的正则表达式拆分为两条或多条简单的正则表达式,编程难度会降低,运行效率会提升。例如用来消除行首和行尾空白字符的正则表达式s/^\s+|\s+$//g;,其运行效率理论上要低于s/^\s+//g; s/\s+$//g; 。这个例子出自《精通正则表达式》第五章,书中对它的评论是“它几乎总是最快的,而且显然最容易理解”。既快又容易理解,何乐而不为?工作中我们还有其它的理由要将C==(A|B)这样的正则表达式拆为A和B两条表达式分别执行。例如,虽然A和B这两种情况只要有一种能够击中所需要的文本模式就会成功匹配,但是如果只要有一条子表达式(例如A)会产生误匹配,那么不论其它的子表达式(例如B)效率如何之高,范围如何精准,C的总体精准度也会因A而受到影响。
巧妙定位。有时候,我们需要匹配的the,是作为单词的the(两边有空格),而不是作为单词一部分的t-h-e的有序排列(例如together中的the)。在适当的时候用上^,$,\b等等定位锚点,能有效提升找到成功匹配、淘汰不成功匹配的效率。