报表项目中,大部分报表简单的搞搞即可完成。但是,总有一部分复杂报表需要自定义数据集才能实现。自定义数据集是指报表的数据源不能通过简单SQL实现,需要用报表工具提供的API,调用程序员开发的程序来实现。这部分报表数量不多,但是编程、调试工作量较大,在整个项目中占用的时间反而更长。
为什么自定义数据集会成为报表项目的常态?
报表由两部分组成的:数据计算和报表呈现。自定义报表出现的原因,是因为数据库的原始数据结构与报表要展现的数据之间差异大,造成报表数据计算过程比较复杂。
有些报表连接的原始数据库是生产数据库,数据结构不适合报表直接展现,所以要写比较复杂的程序;即使报表连接的是经过整理的数据仓库,其数据结构也不一定能适合所有的报表,特别是项目后期出现的报表,一般都要在数据仓库的基础上做进一步复杂计算才能在报表中展现出来。
出现自定义数据源的另外一个原因,是需要连接多个数据库或者其他种类的异构数据源,如oracle、db2、My sql和文件等,也需要自定义数据源。
自定义数据源唯一的好处:无论数据源计算多么复杂,数据来自多少个不同的数据库或者文件,只要会写代码、肯写代码,一定能把所有数据集中到一起完成计算。
现有的编程手段对自定义数据源没有特别理想的。
以Java为例,用Java来自定义数据源的工作量较大,难度高,因为Java并没有提供常用类库,我们要耗费大量时间和精力来手工实现细节,包括聚合,过滤,分组,排序,排名等。比如,数据存储和访问的细节:每条数据,每个二维表都需用List/map等对象组合起来,再用嵌套的多层循环来算。这类计算往往涉及到批量数据之间的集合和关系运算,或者对象之间和对象属性之间的相对位置的运算,这些底层逻辑搞起来非常费力。如果还有复杂的有序计算,Java处理的工作量就更大了。
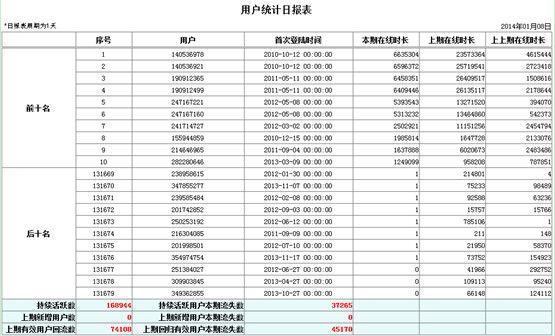
举例:某网络平台需要监测一定周期内的用户状况,为运营部门出具日报、周报、月报、年报等报表,每类报表中均包含本期与上期、上上期数据比较。此处以日报为例(月报年报只是统计周期不同),报表格式如下:
<!--[endif]-->
报表分为两部分,上半部分为用户明细数据,由于用户较多,报表中只显示按本期在线时长排序后的前十名和后十名;下半部分为本期数据与上期、上上期的比较结果。
以润乾报表为例,使用Java来计算自定义数据源的主要代码如下:
获取报表参数
Map map = ctx.getParamMap(false);
if (map != null) {
Iterator it = map.keySet().iterator();
while (it.hasNext()) {
// 分别取得参数
String key = it.next().toString();
data_date = map.get(key).toString();
}
}
执行数据库sql取数
String sql ="select a.userid auserid,a.first_logout_time,b.userid buserid,b.onlinetime bonlinetime,b.account baccount,"
+"c.userid cuserid,c.onlinetime conlinetime,c.account caccount,d.userid duserid,d.onlinetime donlinetime,d.account daccount,"
+"from"
+"(select v.userid, v.first_logout_time"
+"from t_dw_zx_valid_account v"
+"where v.standard_7d_time is not null) a,"
+"(select userid, sum(onlinetime) onlinetime, max(account)"
+"from t_dw_zx_account_status_day"
+"where logtime >= to_date('"+start_time_tm+"','yyyy-mm-dd hh:mi:ss')"
+"and logtime <"+end_time_tm+"','yyyy-mm-dd hh:mi:ss')"
+"group by userid"
+"having max(account) is not null) b,"
+"(select userid, sum(onlinetime) onlinetime, max(account)"
+"from t_dw_zx_account_status_day"
+"where logtime >= to_date('"+start_time_lm+"','yyyy-mm-dd hh:mi:ss')"
+"and logtime < to_date('"+start_time_tm+"','yyyy-mm-dd hh:mi:ss')"
+"group by userid"
+"having max(account) is not null) c,"
+"(select userid, sum(onlinetime) onlinetime, max(account)"
+"from t_dw_zx_account_status_day"
+"where logtime >= to_date('"+start_time_lm_1+"','yyyy-mm-dd hh:mi:ss')"
+"and logtime < to_date('"+start_time_lm+"','yyyy-mm-dd hh:mi:ss')"
+"group by userid"
+"having max(account) is not null) d"
+"where a.userid = b.userid(+)"
+"and a.userid = c.userid(+)"
+"and a.userid = d.userid(+))"
+"order by b.onlinetime desc";
为降低复杂度,数据初步加工(分组、过滤、排序)仍然使用sql完成。
获取列名
for(int i=0;i<colCount;i++){
colName.add(rsmd.getColumnName(i+1));//列名
type = rsmd.getColumnType(i+1);
}
读取表数据,将其存入List
while (rs.next()) {
List<Object> rowData = new ArrayList<Object>();
for(int i=0;i<colCount;i++){
rowData.add(rs.getObject(i+1));
System.out.println("rowData"+i+"="+rowData.get(i));
}
data.add(rowData);
}
构造数据集ds1
DataSet ds1 = new DataSet("ds1");
for (int i = 0; i < colName.size(); i++) {
ds1.addCol(colName.get(i));// 设置数据集的字段
}
Row rr = null;
遍历List计算汇总值
for(int i=0;i<data.size();i++){
List<Object> row_data = data.get(i);
boolean flag1=false;
boolean flag2=false;
boolean flag3=false;
boolean flag4=false;
boolean flag5=false;
for(int j=0;j<row_data.size();j++){
Object single_data = row_data.get(j);
String str_single_data = single_data.toString();
/****************计算汇总值************************/
if(j==3 && single_data!=null){//buserid is not null
flag1=true;
}elseif(j==6 && single_data!=null){//cuserid is not null
flag2=true;
}elseif(j==9 && single_data!=null){//duserid is not null
flag3=true;
}elseif(j==2){
if(str_single_data.compareTo(start_time_lm)>=0 && str_single_data.compareTo(start_time_tm)<0){
flag4=true;//
}
if(str_single_data.compareTo(start_time_lm)<0){
flag5=true;
}
}
if (flag2&&flag3){
count1++;
}
if(flag3&&!flag1){
count2++;
}
if(flag4){
count3++;
}
if(flag1&&flag4){
count4++;
}
if(!flag3&&flag2&&flag5){
count5++;
}
if(!flag1&&!flag3&&flag2&&flag5){
count6++;
}
}
前十名数据
if(i<=10){
// 设置数据集中的数据
rr = ds1.addRow();
for (int j = 0; j <row_data.size(); j++) {
rr.setData(j + 1, row_data.get(j)); }
}
}
后十名
for(int i=0;i<data.size();i++){
List<Object> row_data = data.get(i);
if(i>data.size()-10){
// 设置数据集中的数据
rr = ds1.addRow();
for (int j = 0; j <row_data.size(); j++) {
rr.setData(j + 1, row_data.get(j));
}
}
}
代码已经很长了,加上获取数据库连接、计算前n天和后n天日期的代码会更长。而且,数据的分组排序是数据库(sql)完成的,如果用Java代码量会更大。
我们试着用集算器来弄,找刚进组的小孩做。
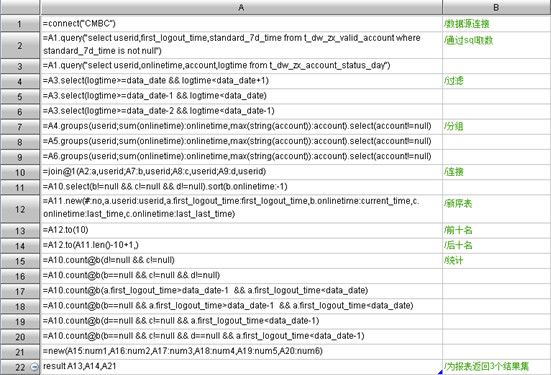
上边的例子,集算器代码如下:
<!--[endif]-->
A4-A6:进行数据过滤
A7-A9:按userid分组
A10:将以上结果集进行关联
A11:基于A10进行过滤后按在线时长排序
A12:新序表,用于读取前后十名记录
A13-A14:通过序号分别取前后十名记录
A15-A20:计算汇总值
A22:将前十名、后十名记录以及汇总值分别以不同结果集通过集算器JDBC返回给报表。
一个屏幕内搞定整个代码,比较简洁。集算器对有序运算的支持,使得取前后十名(A13、A14)非常容易,不用像Java必须写个循环。报表工具通过Jdbc调用自定义数据源。与Java的API接口比较,Jdbc调用更简单。另外,集算器代码是解释执行的,无需编译,程序升级时替换脚本程序文件即可。
学习成本方面,理解集算器的序表、游标花了点功夫,总体看效果不错。