面向 Java 开发人员的 Ajax: 使用 Jetty 和 Direct Web Remoting 编写可扩展的 Comet 应用程序
面向 Java 开发人员的 Ajax: 使用 Jetty 和 Direct Web Remoting 编写可扩展的 Comet 应用程序
使用 Continuations 和 Reverse Ajax 创建事件驱动 Web 应用程序
2007 年 8 月 02 日
受异步服务器端事件驱动的 Ajax 应用程序实现较为困难,并且难于扩展。Philip McCarthy 在其广受欢迎的 系列文章 中介绍了一种行之有效的方法:结合使用 Comet 模式(将数据推到客户机)和 Jetty 6 的 Continuations API(将 Comet 应用程序扩展到大量客户机中)。您可以方便地在 Direct Web Remoting (DWR) 2 中将 Comet 和 Continuations 与 Reverse Ajax 技术结合使用。<!-- START RESERVED FOR FUTURE USE INCLUDE FILES--><!-- include java script once we verify teams wants to use this and it will work on dbcs and cyrillic characters --> <!-- END RESERVED FOR FUTURE USE INCLUDE FILES-->
作为一种广泛使 用的 Web 应用程序开发技术,Ajax 牢固确立了自己的地位,随之而来的是一些通用 Ajax 使用模式。例如,Ajax 经常用于对用户输入作出响应,然后使用从服务器获得的新数据修改页面的部分内容。但是,有时 Web 应用程序的用户界面需要进行更新以响应服务器端发生的异步事件,而不需要用户操作 —— 例如,显示到达 Ajax 聊天应用程序的新消息,或者在文本编辑器中显示来自另一个用户的改变。由于只能由浏览器建立 Web 浏览器和服务器之间的 HTTP 连接,服务器无法在改动发生时将变化 “推送” 给浏览器。
Ajax 应用程序可以使用两种基本的方法解决这一问题:一种方法是浏览器每隔若干秒时间向服务器发出轮询以进行更新,另一种方法是服务器始终打开与浏览器的连接并在数据可用时发送给浏览器。长期连接技术被称为 Comet (请参阅 参考资料 )。本文将展示如何结合使用 Jetty servlet 引擎和 DWR 简捷有效地实现一个 Comet Web 应用程序。
轮 询方法的主要缺点是:当扩展到更多客户机时,将生成大量的通信量。每个客户机必须定期访问服务器以检查更新,这为服务器资源添加了更多负荷。最坏的一种情 况是对不频繁发生更新的应用程序使用轮询,例如一种 Ajax 邮件 Inbox。在这种情况下,相当数量的客户机轮询是没有必要的,服务器对这些轮询的回答只会是 “没有产生新数据”。虽然可以通过增加轮询的时间间隔来减轻服务器负荷,但是这种方法会产生不良后果,即延迟客户机对服务器事件的感知。当然,很多应用程 序可以实现某种权衡,从而获得可接受的轮询方法。
尽管如此,吸引人们使用 Comet 策略的其中一个优点是其显而易见的高效性。客户机不会像使用轮询方法那样生成烦人的通信量,并且事件发生后可立即发布给客户机。但是保持长期连接处于打开 状态也会消耗服务器资源。当等待状态的 servlet 持有一个持久性请求时,该 servlet 会独占一个线程。这将限制 Comet 对传统 servlet 引擎的可伸缩性,因为客户机的数量会很快超过服务器栈能有效处理的线程数量。
Jetty 6 的目的是扩展大量同步连接,使用 Java™ 语言的非阻塞 I/O(java.nio )库并使用一个经过优化的输出缓冲架构(参阅 参考资料 )。Jetty 还为处理长期连接提供了一些技巧:该特性称为 Continuations 。 我将使用一个简单的 servlet 对 Continuations 进行演示,这个 servlet 将接受请求,等待处理,然后发送响应。接下来,我将展示当客户机数量超过服务器提供的处理线程后发生的状况。最后,我将使用 Continuations 重新实现 servlet,您将了解 Continuations 在其中扮演的角色。
为了便于理解下面的示例,我将把 Jetty servlet 引擎限制在一个单请求处理线程。清单 1 展示了 jetty.xml 中的相关配置。我实际上需要在 ThreadPool 使用三个线程:Jetty 服务器本身使用一个线程,另一线程运行 HTTP 连接器,侦听到来的请求。第三个线程执行 servlet 代码。
<?xml version="1.0"?>
<!DOCTYPE Configure PUBLIC "-//Mort Bay Consulting//DTD Configure//EN"
"http://jetty.mortbay.org/configure.dtd">
<Configure id="Server" class="org.mortbay.jetty.Server">
<Set name="ThreadPool">
<New class="org.mortbay.thread.BoundedThreadPool">
<Set name="minThreads">3</Set>
<Set name="lowThreads">0</Set>
<Set name="maxThreads">3</Set>
</New>
</Set>
</Configure>
|
接下来,为了模拟对异步事件的等待,清单 2 展示了 BlockingServlet 的 service() 方法,该方法将使用 Thread.sleep() 调用在线程结束之前暂停 2000 毫秒的时间。它还在执行开始和结束时输出系统时间。为了区别输出和不同的请求,还将作为标识符的请求参数记录在日志中。
public class BlockingServlet extends HttpServlet {
public void service(HttpServletRequest req, HttpServletResponse res)
throws java.io.IOException {
String reqId = req.getParameter("id");
res.setContentType("text/plain");
res.getWriter().println("Request: "+reqId+"\tstart:\t" + new Date());
res.getWriter().flush();
try {
Thread.sleep(2000);
} catch (Exception e) {}
res.getWriter().println("Request: "+reqId+"\tend:\t" + new Date());
}
}
|
现在可以观察到 servlet 响应一些同步请求的行为。清单 3 展示了控制台输出,五个使用 lynx 的并行请求。命令行启动五个 lynx 进程,将标识序号附加在请求 URL 的后面。
清单 3. 对 BlockingServlet 并发请求的输出
$ for i in 'seq 1 5' ; do lynx -dump localhost:8080/blocking?id=$i & done Request: 1 start: Sun Jul 01 12:32:29 BST 2007 Request: 1 end: Sun Jul 01 12:32:31 BST 2007 Request: 2 start: Sun Jul 01 12:32:31 BST 2007 Request: 2 end: Sun Jul 01 12:32:33 BST 2007 Request: 3 start: Sun Jul 01 12:32:33 BST 2007 Request: 3 end: Sun Jul 01 12:32:35 BST 2007 Request: 4 start: Sun Jul 01 12:32:35 BST 2007 Request: 4 end: Sun Jul 01 12:32:37 BST 2007 Request: 5 start: Sun Jul 01 12:32:37 BST 2007 Request: 5 end: Sun Jul 01 12:32:39 BST 2007 |
清单 3 中的输出和预期一样。因为 Jetty 只可以使用一个线程执行 servlet 的 service() 方法。Jetty 对请求进行排列,并按顺序提供服务。当针对某请求发出响应后将立即显示时间戳(一个 end 消息),servlet 接着处理下一个请求(后续的 start 消息)。因此即使同时发出五个请求,其中一个请求必须等待 8 秒钟的时间才能接受 servlet 处理。
请注意,当 servlet 被阻塞时,执行任何操作都无济于事。这段代码模拟了请求等待来自应用程序不同部分的异步事件。这里使用的服务器既不是 CPU 密集型也不是 I/O 密集型:只有线程池耗尽之后才会对请求进行排队。
现在,查看 Jetty 6 的 Continuations 特性如何为这类情形提供帮助。清单 4 展示了 清单 2 中使用 Continuations API 重写后的 BlockingServlet 。我将稍后解释这些代码。
public class ContinuationServlet extends HttpServlet {
public void service(HttpServletRequest req, HttpServletResponse res)
throws java.io.IOException {
String reqId = req.getParameter("id");
Continuation cc = ContinuationSupport.getContinuation(req,null);
res.setContentType("text/plain");
res.getWriter().println("Request: "+reqId+"\tstart:\t"+new Date());
res.getWriter().flush();
cc.suspend(2000);
res.getWriter().println("Request: "+reqId+"\tend:\t"+new Date());
}
}
|
清单 5 展示了对 ContinuationServlet 的五个同步请求的输出;请与 清单 3 进行比较。
清单 5. 对 ContinuationServlet 的五个并发请求的输出
$ for i in 'seq 1 5' ; do lynx -dump localhost:8080/continuation?id=$i & done Request: 1 start: Sun Jul 01 13:37:37 BST 2007 Request: 1 start: Sun Jul 01 13:37:39 BST 2007 Request: 1 end: Sun Jul 01 13:37:39 BST 2007 Request: 3 start: Sun Jul 01 13:37:37 BST 2007 Request: 3 start: Sun Jul 01 13:37:39 BST 2007 Request: 3 end: Sun Jul 01 13:37:39 BST 2007 Request: 2 start: Sun Jul 01 13:37:37 BST 2007 Request: 2 start: Sun Jul 01 13:37:39 BST 2007 Request: 2 end: Sun Jul 01 13:37:39 BST 2007 Request: 5 start: Sun Jul 01 13:37:37 BST 2007 Request: 5 start: Sun Jul 01 13:37:39 BST 2007 Request: 5 end: Sun Jul 01 13:37:39 BST 2007 Request: 4 start: Sun Jul 01 13:37:37 BST 2007 Request: 4 start: Sun Jul 01 13:37:39 BST 2007 Request: 4 end: Sun Jul 01 13:37:39 BST 2007 |
清单 5 中有两处需要重点注意。首先,每个 start 消息出现两次;先不要着急。其次,更重要的一点,请求现在不需排队就能够并发处理,注意所有 start 和 end 消息的时间戳是相同的。因此,每个请求的处理时间不会超过两秒,即使只运行一个 servlet 线程。
理解了 Jetty Continuations 机制的实现原理,您就能够解释 清单 5 中的现象。要使用 Continuations,必须对 Jetty 进行配置,以使用其 SelectChannelConnector 处理请求。这个连接器构建在 java.nio API 之上,因此使它能够不用消耗每个连接的线程就可以持有开放的连接。当使用 SelectChannelConnector 时,ContinuationSupport.getContinuation() 将提供一个 SelectChannelConnector.RetryContinuation 实例。(然而,您应该只针对 Continuation 接口进行编码;请参阅 Portability and the Continuations API 。)当对 RetryContinuation 调用 suspend() 时,它将抛出一个特殊的运行时异常 —— RetryRequest —— 该异常将传播到 servlet 以外并通过过滤器链传回,并由 SelectChannelConnector 捕获。 但是发生该异常之后并没有将响应发送给客户机,请求被放到处于等待状态的 Continuation 队列中,而 HTTP 连接仍然保持打开状态。此时,为该请求提供服务的线程将返回 ThreadPool ,用以为其他请求提供服务。
|
暂停的请求将一直保持在等待状态的 Continuation 队列,直到超出指定的时限,或者当对 resume() 方法的 Continuation 调用 resume() 时(稍后将详细介绍)。出现上述任意一种条件时,请求将被重新提交到 servlet(通过过滤器链)。事实上,整个请求被重新进行处理,直到首次调用 suspend() 。当执行第二次发生 suspend() 调用时,RetryRequest 异常不会被抛出,执行照常进行。
现在应该可以解释 清单 5 中的输出了。每个请求依次进入 servlet 的 service() 方法后,将发送 start 消息进行响应,Continuation 的 suspend() 方法引发 servlet 异常,将释放线程使其处理下一个请求。所有五个请求快速通过 service() 方法的第一部分,并进入等待状态,并且所有 start 消息将在几毫秒内输出。两秒后,当超过 suspend() 的时限后,将从等待队列中检索第一个请求,并将其重新提交给 ContinuationServlet 。第二次输出 start 消息,立即返回对 suspend() 的第二次调用,并且发送 end 消息进行响应。然后将在此执行 servlet 代码来处理队列中的下一个请求,以此类推。
因此,在 BlockingServlet 和 ContinuationServlet 两种情况中,请求被放入队列中以访问单个 servlet 线程。然而,虽然 servlet 线程执行期间 BlockingServlet 发生两秒暂停,SelectChannelConnector 中的 ContinuationServlet 的暂停发生在 servlet 之外。ContinuationServlet 的总吞吐量更高一些,因为 servlet 线程没有将大部分时间用在 sleep() 调用中。
现在您已经了解到 Continuations 能够不消耗线程就可以暂停 servlet 请求,我需要进一步解释 Continuations API 以向您展示如何在实际应用中使用。
resume() 方法生成一对 suspend() 。可以将它们视为标准的 Object wait() /notify() 机制的 Continuations 等价体。就是说,suspend() 使 Continuation (因此也包括当前方法的执行)处于暂停状态,直到超出时限,或者另一个线程调用 resume() 。suspend() /resume() 对于实现真正使用 Continuations 的 Comet 风格的服务非常关键。其基本模式是:从当前请求获得 Continuation ,调用 suspend() ,等待异步事件的到来。然后调用 resume() 并生成一个响应。
然而,与 Scheme 这种语言中真正的语言级别的 continuations 或者是 Java 语言的 wait() /notify() 范例不同的是,对 Jetty Continuation 调用 resume() 并不意味着代码会从中断的地方继续执行。正如您刚刚看到的,实际上和 Continuation 相关的请求被重新处理。这会产生两个问题:重新执行 清单 4 中的 ContinuationServlet 代码,以及丢失状态:即调用 suspend() 时丢失作用域内所有内容。
第一个问题的解决方法是使用 isPending() 方法。如果 isPending() 返回值为 true,这意味着之前已经调用过一次 suspend() ,而重新执行请求时还没有发生第二次 suspend() 调用。换言之,根据 isPending() 条件在执行 suspend() 调用之前运行代码,这样将确保对每个请求只执行一次。在 suspend() 调用具有等幂性之前,最好先对应用程序进行设计,这样即使调用两次也不会出现问题,但是某些情况下无法使用 isPending() 方法。Continuation 也提供了一种简单的机制来保持状态:putObject(Object) 和 getObject() 方法。在 Continuation 发生暂停时,使用这两种方法可以保持上下文对象以及需要保存的状态。您还可以使用这种机制作为在线程之间传递事件数据的方式,稍后将演示这种方法。
作 为实际示例场景,我将开发一个基本的 GPS 坐标跟踪 Web 应用程序。它将在不规则的时间间隔内生成随机的经纬度值对。发挥一下想象力,生成的坐标值可能就是临近的一个公共车站、随身携带着 GPS 设备的马拉松选手、汽车拉力赛中的汽车或者运输中的包裹。令人感兴趣的是我将如何告诉浏览器这个坐标。图 1 展示了这个简单的 GPS 跟踪器应用程序的类图:
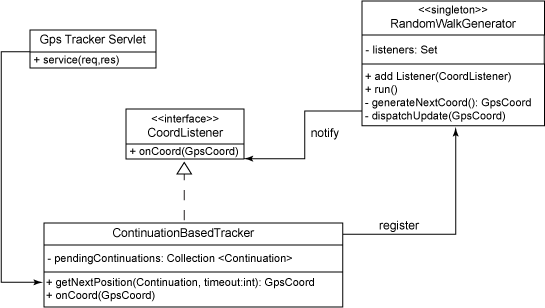
首先,应用程序需要某种方法来生成坐标。这将由 RandomWalkGenerator 完成。从一对初始坐标对开始,每次调用它的私有 generateNextCoord() 方法时,将从该位置移动随机指定的距离,并将新的位置作为 GpsCoord 对象返回。初始化完成后,RandomWalkGenerator 将生成一个线程,该线程以随机的时间间隔调用 generateNextCoord() 方法并将生成的坐标发送给任何注册了 addListener() 的 CoordListener 实例。清单 6 展示了 RandomWalkGenerator 循环的逻辑:
清单 6. RandomWalkGenerator's run() 方法
public void run() {
try {
while (true) {
int sleepMillis = 5000 + (int)(Math.random()*8000d);
Thread.sleep(sleepMillis);
dispatchUpdate(generateNextCoord());
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
|
CoordListener 是一个回调接口,仅仅定义 onCoord(GpsCoord coord) 方法。在本例中,ContinuationBasedTracker 类实现 CoordListener 。ContinuationBasedTracker 的另一个公有方法是 getNextPosition(Continuation, int) 。清单 7 展示了这些方法的实现:
清单 7. ContinuationBasedTracker 结构
public GpsCoord getNextPosition(Continuation continuation, int timeoutSecs) {
synchronized(this) {
if (!continuation.isPending()) {
pendingContinuations.add(continuation);
}
// Wait for next update
continuation.suspend(timeoutSecs*1000);
}
return (GpsCoord)continuation.getObject();
}
public void onCoord(GpsCoord gpsCoord) {
synchronized(this) {
for (Continuation continuation : pendingContinuations) {
continuation.setObject(gpsCoord);
continuation.resume();
}
pendingContinuations.clear();
}
}
|
当客户机使用 Continuation 调用 getNextPosition() 时,isPending 方法将检查此时的请求是否是第二次执行,然后将它添加到等待坐标的 Continuation 集合中。然后该 Continuation 被暂停。同时,onCoord —— 生成新坐标时将被调用 —— 循环遍历所有处于等待状态的 Continuation ,对它们设置 GPS 坐标,并重新使用它们。之后,每个再次执行的请求完成 getNextPosition() 执行,从 Continuation 检索 GpsCoord 并将其返回给调用者。注意此处的同步需求,是为了保护 pendingContinuations 集合中的实例状态不会改变,并确保新增的 Continuation 在暂停之前没有被处理过。
最后一个难点是 servlet 代码本身,如 清单 8 所示:
public class GpsTrackerServlet extends HttpServlet {
private static final int TIMEOUT_SECS = 60;
private ContinuationBasedTracker tracker = new ContinuationBasedTracker();
public void service(HttpServletRequest req, HttpServletResponse res)
throws java.io.IOException {
Continuation c = ContinuationSupport.getContinuation(req,null);
GpsCoord position = tracker.getNextPosition(c, TIMEOUT_SECS);
String json = new Jsonifier().toJson(position);
res.getWriter().print(json);
}
}
|
如您所见,servlet 只执行了很少的工作。它仅仅获取了请求的 Continuation ,调用 getNextPosition() ,将 GPSCoord 转换成 JavaScript Object Notation (JSON),然后输出。这里不需要防止重新执行,因此我不必检查 isPending() 。清单 9 展示了调用 GpsTrackerServlet 的输出,同样,有五个同步请求而服务器只有一个可用线程:
Listing 9. Output of GPSTrackerServlet
$ for i in 'seq 1 5' ; do lynx -dump localhost:8080/tracker & done
{ coord : { lat : 51.51122, lng : -0.08103112 } }
{ coord : { lat : 51.51122, lng : -0.08103112 } }
{ coord : { lat : 51.51122, lng : -0.08103112 } }
{ coord : { lat : 51.51122, lng : -0.08103112 } }
{ coord : { lat : 51.51122, lng : -0.08103112 } }
|
这个示例并不引人注意,但是提供了概念证明。发出请求后,它们将一直保持打开的连接直至生成坐标,此时将快速生成响应。这是 Comet 模式的基本原理,Jetty 使用这种原理在一个线程内处理 5 个并发请求,这都是 Continuations 的功劳。
现在您已经了解了如何使用 Continuations 在理论上创建非阻塞 Web 服务,您可能想知道如何创建客户端代码来使用这种功能。一个 Comet 客户机需要完成以下功能:
- 保持打开
XMLHttpRequest连接,直到收到响应。 - 将响应发送到合适的 JavaScript 处理程序。
- 立即建立新的连接。
更高级的 Comet 设置将使用一个连接将数据从不同服务推入浏览器,并且客户机和服务器配有相应的路由机制。一种可行的方法是根据一种 JavaScript 库,例如 Dojo,编写客户端代码,这将提供基于 Comet 的请求机制,其形式为 dojo.io.cometd 。
然而,如果服务器使用 Java 语言,使用 DWR 2 可以同时在客户机和服务器上获得 Comet 高级支持,这是一种不错的方法(参阅 参考资料 )。如果您并不了解 DWR 的话,请参阅本系列第 3 部分 “结合 Direct Web Remoting 使用 Ajax ”。DWR 透明地提供了一种 HTTP-RPC 传输层,将您的 Java 对象公开给网络中 JavaScript 代码的调用。DWR 生成客户端代理,将自动封送和解除封送数据,处理安全问题,提供方便的客户端实用工具库,并可以在所有主要浏览器上工作。
DWR 2 最新引入了 Reverse Ajax 概念。这种机制可以将服务器端事件 “推入” 到客户机。客户端 DWR 代码透明地处理已建立的连接并解析响应,因此从开发人员的角度来看,事件是从服务器端 Java 代码轻松地发布到客户机中。
DWR 经过配置之后可以使用 Reverse Ajax 的三种不同机制。第一种就是较为熟悉的轮询方法。第二种称为 piggyback , 这种机制并不创建任何到服务器的连接,相反,将一直等待直至发生另一个 DWR 服务,piggybacks 使事件等待该请求的响应。这使它具有较高的效率,但也意味着客户机事件通知被延迟到直到发生另一个不相关的客户机调用。最后一种机制使用长期的、 Comet 风格的连接。最妙的是,当运行在 Jetty 下时,DWR 能够自动检测并切换为使用 Contiuations,实现非阻塞 Comet。
我将在 GPS 示例中结合使用 Reverse Ajax 和 DWR 2。通过这种演示,您将对 Reverse Ajax 的工作原理有更多的了解。
此时不再需要使用 servlet。DWR 提供了一个控制器 servlet,它将在 Java 对象之上直接转交客户机请求。同样也不需要显式地处理 Continuations,因为 DWR 将在内部进行处理。因此我只需要一个新的 CoordListener 实现,将坐标更新发布到到任何客户机浏览器上。
ServerContext 接口提供了 DWR 的 Reverse Ajax 功能。ServerContext 可以察觉到当前查看给定页面的所有 Web 客户机,并提供一个 ScriptSession 进行相互通信。ScriptSession 用于从 Java 代码将 JavaScript 片段推入到客户机。清单 10 展示了 ReverseAjaxTracker 响应坐标通知的方式,并使用它们生成对客户端 updateCoordinate() 函数的调用。注意对 DWR ScriptBuffer 对象调用 appendData() 将自动把 Java 对象封送给 JSON(如果使用合适的转换器)。
清单 10. ReverseAjaxTracker 中的通知回调方法
public void onCoord(GpsCoord gpsCoord) {
// Generate JavaScript code to call client-side
// function with coord data
ScriptBuffer script = new ScriptBuffer();
script.appendScript("updateCoordinate(")
.appendData(gpsCoord)
.appendScript(");");
// Push script out to clients viewing the page
Collection<ScriptSession> sessions =
sctx.getScriptSessionsByPage(pageUrl);
for (ScriptSession session : sessions) {
session.addScript(script);
}
}
|
接下来,必须对 DWR 进行配置以感知 ReverseAjaxTracker 的存在。在大型应用程序中,可以使用 DWR 的 Spring 集成提供 Spring 生成的 bean。但是,在本例中,我仅使用 DWR 创建了一个 ReverseAjaxTracker 新实例并将其放到 application 范围中。所有后续请求将访问这个实例。
我还需告诉 DWR 如何将数据从 GpsCoord beans 封送到 JSON。由于 GpsCoord 是一个简单对象,DWR 的基于反射的 BeanConverter 就可以完成此功能。清单 11 展示了 ReverseAjaxTracker 的配置:
清单 11. ReverseAjaxTracker 的 DWR 配置
<dwr>
<allow>
<create creator="new" javascript="Tracker" scope="application">
<param name="class" value="developerworks.jetty6.gpstracker.ReverseAjaxTracker"/>
</create>
<convert converter="bean" match="developerworks.jetty6.gpstracker.GpsCoord"/>
</allow>
</dwr>
|
create 元素的 javascript 属性指定了 DWR 用于将跟踪器公开为 JavaScript 对象的名字,在本例中,我的客户端代码没有使用该属性,而是将数据从跟踪器推入到其中。同样 ,还需对 web.xml 进行额外的配置,以针对 Reverse Ajax 配置 DWR,如 清单 12 所示:
清单 12. DwrServlet 的 web.xml 配置
<servlet>
<servlet-name>dwr-invoker</servlet-name>
<servlet-class>
org.directwebremoting.servlet.DwrServlet
</servlet-class>
<init-param>
<param-name>activeReverseAjaxEnabled</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<param-name>initApplicationScopeCreatorsAtStartup</param-name>
<param-value>true</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
|
第一个 servlet init-param ,activeReverseAjaxEnabled 将激活轮询和 Comet 功能。第二个 initApplicationScopeCreatorsAtStartup 通知 DWR 在应用程序启动时初始化 ReverseAjaxTracker 。这将在对 bean 生成第一个请求时改写延迟初始化(lazy initialization)的常规行为 —— 在本例中这是必须的,因为客户机不会主动对 ReverseAjaxTracker 调用方法。
最后,我需要实现调用自 DWR 的客户端 JavaScript 函数。将向回调函数 —— updateCoordinate() —— 传递 GpsCoord Java bean 的 JSON 表示,由 DWR 的 BeanConverter 自动序列化。该函数将从坐标中提取 longitude 和 latitude 字段,并通过调用 Document Object Model (DOM) 将它们附加到列表中。清单 13 展示了这一过程,以及页面的 onload 函数。onload 包含对 dwr.engine.setActiveReverseAjax(true) 的调用,将通知 DWR 打开与服务器的持久连接并等待回调。
清单 13. 简单 Reverse Ajax GPS 跟踪器的客户端实现
window.onload = function() {
dwr.engine.setActiveReverseAjax(true);
}
function updateCoordinate(coord) {
if (coord) {
var li = document.createElement("li");
li.appendChild(document.createTextNode(
coord.longitude + ", " + coord.latitude)
);
document.getElementById("coords").appendChild(li);
}
}
|
|
现在我可以将浏览器指向跟踪器页面,DWR 将在生成坐标数据时把数据推入客户机。该实现输出生成坐标的列表,如 图 2 所示:
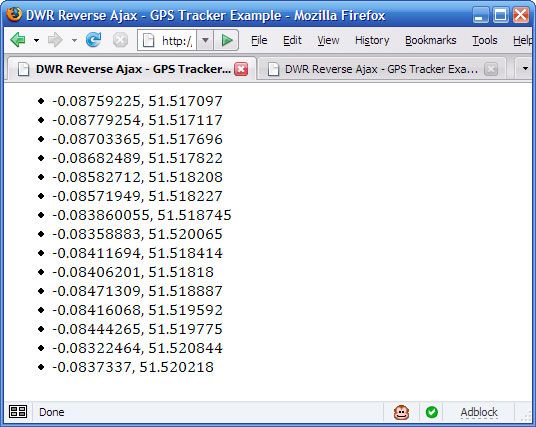
可以看到,使用 Reverse Ajax 创建事件驱动的 Ajax 应用程序非常简单。请记住,正是由于 DWR 使用了 Jetty Continuations,当客户机等待新事件到来时不会占用服务器上面的线程。
此时,集成来自 Yahoo! 或 Google 的地图部件非常简单。通过更改客户端回调,可轻松地将坐标传送到地图 API,而不是直接附加到页面中。图 3 展示了 DWR Reverse Ajax GPS 跟踪器在此类地图组件上标绘随机路线:
Figure 3. 具有地图 UI 的 ReverseAjaxTracker 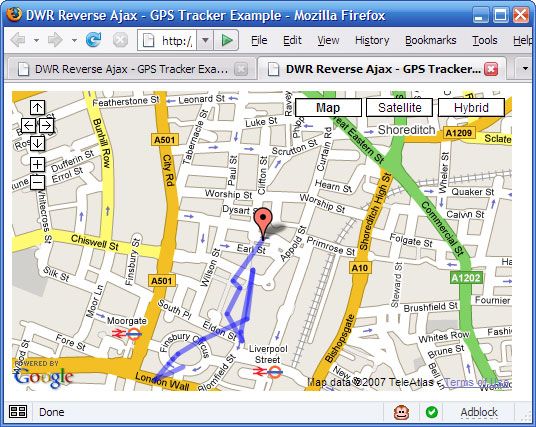
通 过本文,您了解了如何结合使用 Jetty Continuations 和 Comet 为事件驱动 Ajax 应用程序提供高效的可扩展解决方案。我没有给出 Continuations 可扩展性的具体数字,因为实际应用程序的性能取决于多种变化的因素。服务器硬件、所选择的操作系统、JVM 实现、Jetty 配置以及应用程序的设计和通信量配置文件都会影响 Jetty Continuations 的性能。然而,Webtide 的 Greg Wilkins(主要的 Jetty 开发人员)曾经发布了一份关于 Jetty 6 的白皮书,对使用 Continuations 和没有使用 Continuations 的 Comet 应用程序的性能进行了比较,该程序同时处理 10000 个并发请求(参阅 参考资料 )。在 Greg 的测试中,使用 Continuations 能够减少线程消耗,并同时减少了超过 10 倍的栈内存消耗。
您 还看到了使用 DWR 的 Reverse Ajax 技术实现事件驱动 Ajax 应用程序是多么简单。DWR 不仅省去了大量客户端和服务器端编码,而且 Reverse Ajax 还从代码中将完整的服务器-推送机制抽象出来。通过更改 DWR 的配置,您可以自由地在 Comet、轮询,甚至是 piggyback 方法之间进行切换。您可以对此进行实验,并找到适合自己应用程序的最佳性能策略,同时不会影响到自己的代码。
如果希望对自己的 Reverse Ajax 应用程序进行实验,下载并研究 DWR 演示程序的代码(DWR 源代码发行版的一部分,参阅 参考资源 )将非常有帮助。如果希望亲自运行示例,还可获得本文使用的示例代码(参见 下载 )。