Lzw字典压缩(思路简单)
Lzw字典压缩:
1978年,Ziv和Lempel开发了一种基于字典的被称为LZ78 的压缩算法,在LZ78中,字典是一个潜在的先前所见的短语的无限序列。后来由于自身限制,由Terry Welch在1984年提出的关于LZ78压缩算法的变种,他的编码器部署出单个字符,只是输出词典短语中的代号(或者说是代码)。
lzw的编码词典就像是一张转换表,用来存放每一项,每个表象分配一个代码,默认的是将0~255即8位的ASCII字符集进行了扩充,增加的符号用来表示创建的新的代码。扩充后的代码可以采用自己定义的位来表示,比如12位,15位等等。不过此时用的是数组存储,可定义默认的数组长度可以是2的12次方4096,或者是2的15次方32768。自己是用的队列,所以相当于是默认的可存放2的16次方65536个对象。
简单说明:
例如对于abababababababababab,字符a(97)和b(98)出现的次数很多,那么就可以将ab作为一个新的节点例如256存储,此时文件就相当于256,256,256。。。如果将ababab当作257,那么文件就会变为257,257.压缩的效果还是很明显的。
适用范围:
对于文件中字符重复出现次数多的压缩效果比较好。
效果展示
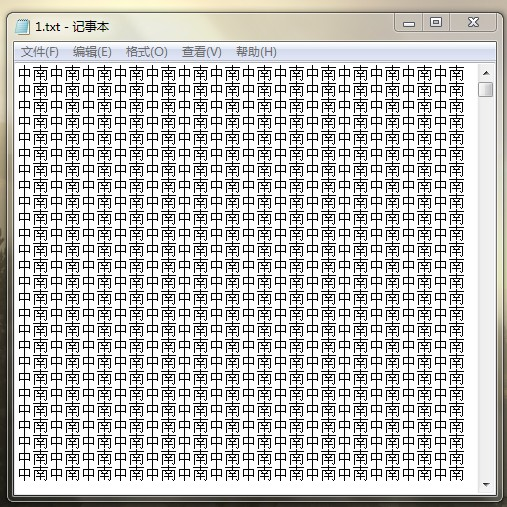
压缩前:
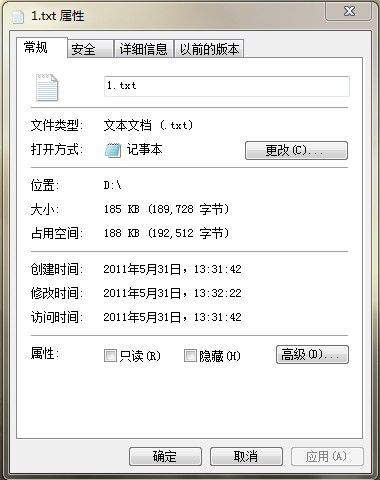
压缩后:
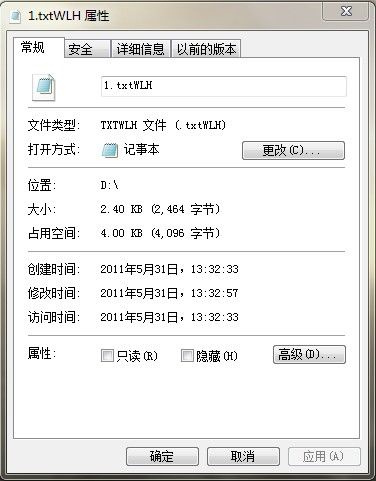
举例实现:
例如比较简单的abababab
压缩:
最后输出的是:a,b,256,257,c 压缩玩了以后就可以将字典扔掉,在解压的时候重新建立字典。
解压:
由于压缩的独特方法,那么解压时也有自己独特的解压方法,关键是:每一步都可以创建一个Dictionary类,这是由于压缩时方法决定的即:每次发现不认识的节点是就创建一个字典类,同时将前缀写进文件中。在解压的时候,每次读取的字符其实都是压缩时不认识后在创建新的字典类的同时也操作写进文件的这个动作的。例如读取了258,其实此次不仅可以先从字典中找出258对应的首个字符(只需知道首个,此规律可以总结出来),完善碎裂的最后元素的后缀,同时创建新的字典类如262,只是我用的是前缀当然是258,默认后缀为0,再读取下个字节时如256,得到256的首个字符作为将上次创建的262的后缀。实际上每步都可以创建新的字典类。
具体的步骤:

package 字典压缩;
import javax.swing.*;
public class LzwMain extends JFrame{
//定义按钮属性
JButton jb1=new JButton("压 缩");
JButton jb2=new JButton("解 压");
//主函数
public static void main(String[] args) {
LzwMain lzwMain=new LzwMain();
}
//构造函数
public LzwMain(){
this.setTitle("十三月的__字典压缩");
this.setSize(300, 200);
this.setLocationRelativeTo(null);
this.setLayout(null);
this.setIconImage(new ImageIcon("字典压缩_1\\张杰.jpg").getImage());
this.add(jb1);
jb1.setBounds(50, 50, 80, 30);
this.add(jb2);
jb2.setBounds(170, 50, 80, 30);
Listener lis=new Listener();
jb1.addActionListener(lis);
jb1.setActionCommand("压缩");
jb2.addActionListener(lis);
jb2.setActionCommand("解压");
this.setVisible(true);
this.setDefaultCloseOperation(3);
}
}
package 字典压缩;
import javax.swing.*;
import java.awt.event.ActionEvent;
public class Listener implements java.awt.event.ActionListener{
public void actionPerformed(ActionEvent arg0) {
if(arg0.getActionCommand().equals("压缩")){
JFileChooser jfc=new JFileChooser();
jfc.setName("字典压缩---压缩");
jfc.setVisible(true);
int returnVal=jfc.showOpenDialog(null);
if(returnVal==JFileChooser.APPROVE_OPTION){
String path=jfc.getSelectedFile().getAbsolutePath();
Lzw_Com l_c=new Lzw_Com();
l_c.read(path);
}
}else{
JFileChooser jfc=new JFileChooser();
jfc.setDialogTitle("字典压缩---解压缩");
jfc.setVisible(true);
int returnVal=jfc.showSaveDialog(null);
if(returnVal==JFileChooser.APPROVE_OPTION){
String path=jfc.getSelectedFile().getAbsolutePath();
Lzw_Decom l_d=new Lzw_Decom();
l_d.read(path);
}
}
}
}
字典类:
package 字典压缩;
//字典类
public class Dictionary {
int index;// 索引
LzwNode lzwNode;// 节点
// 构造函数
public Dictionary(int index, LzwNode lzwNode) {
this.index = index;
this.lzwNode = lzwNode;
}
}
压缩:
package 字典压缩;
import java.io.*;
import java.util.ArrayList;
//压缩
public class Lzw_Com {
ArrayList<Dictionary> arr_dic = new ArrayList<Dictionary>();
public void read(String path) {
// 创建输入流对象
InputStream is = null;
OutputStream os = null;
DataOutputStream dos = null;
int index = 255;
try {
is = new FileInputStream(path);
os = new FileOutputStream(path + "WLH");
dos = new DataOutputStream(os);
int prefix = is.read();
int suffix;
while (is.available() != 0) {
suffix = is.read();
System.out.println("@@@@@@@@ " + prefix + " " + suffix);
LzwNode newNode = new LzwNode(prefix, suffix);
// 遍历
// 定义一种状态 判断是否循环完毕
boolean state = true;
for (int i = 0; i < arr_dic.size(); i++) {
Dictionary dic = arr_dic.get(i);
if (newNode.isEqual(dic.lzwNode)) {
System.out.println("存在相同的。。。。。");
suffix = dic.index;
state = false;
}
}
if (state) {// 如果队列中不存在新建的节点对象
System.out.println("写进去的字符是 " + prefix);
dos.writeChar(prefix);// 将前缀写进文件
index++;
Dictionary newDic = new Dictionary(index, newNode);
arr_dic.add(newDic);// 将字典类对象添加到队列
}
// 后缀变前缀
prefix = suffix;
}
// 处理最后一个字节
int last = prefix;
System.out.println(last);
dos.writeChar(last);
// 完毕输出
System.out.println("@@@@@ 结束。。。。");
dos.close();
os.close();
is.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
解压:
package 字典压缩;
import java.util.ArrayList;
import java.io.*;
//解压
public class Lzw_Decom {
// 存放字典类的队列
ArrayList<Dictionary> arr_dic = new ArrayList<Dictionary>();
// 输出流对象------此处定义成全局变量为了下面用起来方便
OutputStream os = null;
// 解压的方法
public void read(String path) {
InputStream is = null;
DataInputStream dis = null;
try {
is = new FileInputStream(path);
dis = new DataInputStream(is);
// 恢复文件绝对路径
String newPath = path.substring(0, path.length() - 3);
os = new FileOutputStream(newPath);// 创建流对象
int prefix = 0;// 初始化前缀为0(自己设的)
int index = 255;// 初始化索引
LzwNode newNode;// 每一步至少创建的一个节点
while (dis.available() != 0) {
prefix = dis.readChar();// 读取
if (arr_dic.size() != 0) {
// 不为零是为了读取的第一个字节特殊处理---防止数组越界
// 队列中最后一个元素中的节点
LzwNode last = arr_dic.get(arr_dic.size() - 1).lzwNode;
// 改变队列最后一个字典类元素的节点后缀(即改变默认的0)
last.suffix = getPrefix(prefix);
}
// 创建出新的节点
newNode = new LzwNode(prefix, 0);// 后缀默认为0
index++;
Dictionary newDic = new Dictionary(index, newNode);// 新的字典类
arr_dic.add(newDic);
// 调用方法 递归写进文件
if (prefix <= arr_dic.size() + 256) {
write(prefix);
}
}
os.close();
dis.close();
is.close();// 关闭流
} catch (Exception e) {
e.printStackTrace();
}
}
public void write(int prefix) throws IOException {
// 递归终止的条件
if (prefix <= 255) {
os.write(prefix);// 写入前缀
return;
}
// 如果大於256
if (prefix > 255) {
LzwNode lzwnode = arr_dic.get(prefix - 256).lzwNode;// 取得索引下的节点
prefix = lzwnode.prefix;// 前缀
write(prefix);// 递归写入前缀
os.write(lzwnode.suffix);// 递归完以后写入后缀
}
return;
}
// 定义一个取得字典元素中的前缀方法
public int getPrefix(int prefix) {
// 递归的终止条件
if (prefix <= 255) {
return prefix;
}
prefix = arr_dic.get(prefix - 256).lzwNode.prefix;
prefix = getPrefix(prefix);
return prefix;
}
}
这次写的字典压缩并没有采用数组,而是用了队列,所以相当于是LZ16,其实还有lz12,lz15,lz18.各种变长的编码。压缩的时候,时间都是花费在字典查找是否有相同的地方上,还需要更好的方法。最大的好处是解压的时候速度特别的块,而且根本不需要将字典写进压缩文件中去。得等看完更多的压缩后再改进。