JUC之 ThreadPoolExecutor 源码解析
用下面语句创建一个线程池 ThreadPoolExecutor 。
ExecutorService executorProducer = Executors. newFixedThreadPool (2);
该段代码主要初始化线程池的一些参数,如: corePoolSize , maximumPoolSize , workQueue 等。
executorProducer.execute( new Runnable() {
public void run() {
}
});
上述代码首先创建一个 Runnable 实例,然后执行 execute() 方法,具体代码如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize (command)) {
if (runState == RUNNING && workQueue.offer (command)) {
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
else if (!addIfUnderMaximumPoolSize(command))
reject(command); // is shutdown or saturated
}
}
当线程池已满,或者不能把当前线程加入到线程池中 addIfUnderCorePoolSize() ,则将运行状态的线程加入( workQueue . offer () )到等待队列中去( LinkedBlockingQueue workQueue )。
AddIfUnderCorePoolSize 代码如下:
private boolean addIfUnderCorePoolSize (Runnable firstTask) {
Thread t = null;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (poolSize < corePoolSize && runState == RUNNING)
t = addThread(firstTask);
} finally {
mainLock.unlock();
}
if (t == null)
return false;
t.start();
return true;
}
其中有个方法 addThread 代码如下:
private Thread addThread(Runnable firstTask) {
Worker w = new Worker(firstTask);
Thread t = threadFactory.newThread(w) ;
if (t != null) {
w.thread = t;
workers.add(w);
int nt = ++poolSize;
if (nt > largestPoolSize)
largestPoolSize = nt;
}
return t;
}
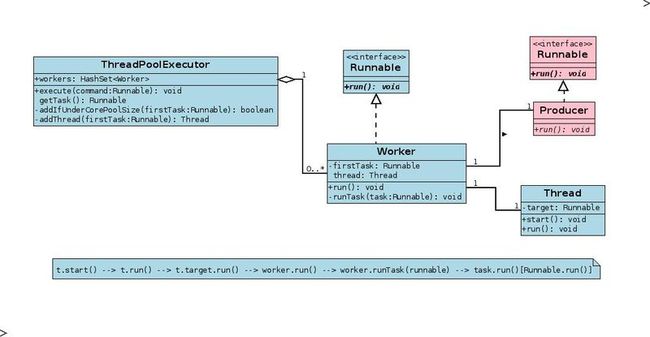
其所用数据结构如下图所示:
-
用户创建一个多线程对象实例( Producer )。
-
使用 1 创建出来的实例,创建一个 Worker 实例。 --> worker.firstTask = producer.
-
以 2 的实例作为 target 创建一个线程实例。 Thread t = new Thread(..., worker, ...)
-
将 2 的属性 worker.thread 与 3 创建的线程实例关联起来。 Worker.thread = t
-
如果 3 的实例为 null, 表示未能创建 produder 对性的执行线程 worker 。转 7 。
-
如果 3 创建了一个线程,则启动线程 t.start() , 返回 true 表示成功将 producer 分配给线程池一个执行线程 worker 。
-
如果未能创建 worker 执行 producer ,则将 producer 放入队列 workQueue.offer() 中,等待以后执行。
其中 3 创建的 thread 主要目的是为了执行 6 中的 thread.start ()方法,因为 Runnable 只是一个接口,没有办法启动一个线程,所以用 Thread 包装了一下。
由图可知通过 Executors 执行用户的线程流程如下:
ThreadPoolExecutor.executor(Producer) --> Thread.start() --> Thread.run() --> Worker.run() --> Worker.runTask(producer) --> producer.run().
其中 worker.run () 代码如下:
public void run() {
try {
Runnable task = firstTask;
firstTask = null;
// 如果 worker 有线程,或者可以从等待队列取到线程,则执行该线程
while (task != null || (task = getTask() ) != null) {
runTask(task);
task = null;
}
} finally {
workerDone(this);
}
}
最终执行线程代码如下:
private void runTask (Runnable task) {
final ReentrantLock runLock = this.runLock;
runLock.lock();
try {
/*
* Ensure that unless pool is stopping, this thread
* does not have its interrupt set. This requires a
* double-check of state in case the interrupt was
* cleared concurrently with a shutdownNow -- if so,
* the interrupt is re-enabled.
*/
if (runState < STOP &&
Thread.interrupted() &&
runState >= STOP)
thread.interrupt();
/*
* Track execution state to ensure that afterExecute
* is called only if task completed or threw
* exception. Otherwise, the caught runtime exception
* will have been thrown by afterExecute itself, in
* which case we don't want to call it again.
*/
boolean ran = false;
beforeExecute(thread, task);
try {
task.run(); //线程实际执行的地方
ran = true;
afterExecute(task, null);
++completedTasks;
} catch (RuntimeException ex) {
if (!ran)
afterExecute(task, ex);
throw ex;
}
} finally {
runLock.unlock();
}
}
最后,总结一下 ThreadPoolExecutor 的执行图如下:
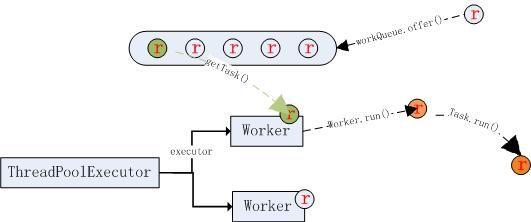
1. ThreadPoolExecutor 通过 executor方法的 addIfUnderCorePoolSize(Runnable)创建线程池里执行线程 worker[i]
2. 如果需要执行的线程个数小于线程池的最大线程数量,则每个 worker 执行一个线程,结束任务。
3. 如果需要执行的线程个数大于线程池的最大线程数量,则每个 worker 取个一个线程,把剩余需要执行的任务存入等待队列中(workQueue.offer()).
4. worker.run() 设置 task 为 firstTask 或者 getTask()的线程。其中 getTask()即为从等待队列取得一个任务,分给该worker执行。
5. task.run() 执行线程。