Python程序的结构
Python的程序由包,模块(即一个Python文件)和函数组成。包是由一系列模块组成的集合。模块是处理某一类问题的函数和类的集合。

包中必须至少含有一个__init__.py文件,该文件的内容可以为空。用于标识当前文件夹是一个包。
模块的内置函数
| 函数 |
说明 |
| abs(x) |
返回x的绝对值 |
| apply(func[,args[,kwargs]]) |
把函数的参数放置在序列中传入函数 |
| bool([y]) |
把一个值或表达式转换为bool类型 |
| cmp(x,y) |
比较x,y的大小 |
| delattr(object,name) |
等价于del object.name |
| eval(s[,globals[,locals]]) |
计算表达式的值 |
| float(x) |
把数字或字符串转换成float类型 |
| hash(object) |
返回一个对象的hash值 |
| help([object]) |
返回内联函数的帮助说明 |
| id(x) |
返回一个对象的id标识 |
| input([prompt]) |
接收控制台的输入,并把输入转换为数字 |
| int(x) |
把数字或者字符串转换为整形 |
| len(object) |
对象包含的元素个数 |
| range([start,]end[,step]) |
生成一个序列并返回 |
| raw_input([prompt]) |
接收控制台输入,返回字符串类型 |
| reduce(func,sequence[,initial]) |
对序列的值进行累计计算 |
| round(x,n=0) |
四舍五入函数 |
| set([iterable]) |
返回一个set集合 |
| sorted(iterable[,cmp[,key[,reverse]]]) |
返回一个排序后的列表 |
| sum(iterable[,start = 0]) |
返回一个序列的和 |
| type(object) |
返回一个对象的类型 |
| xrange([start,]end[,step]) |
功能和range()类似,但是一次返回一个值 |
| zip(seq1[,seq2,….]) |
把n个序列作为列表的元素返回 |
1. filter()
filter()可以对某个序列做过滤处理,对自定义函数的参数返回的结果是否为“真”来过滤,并一次性返回处理结果。
声明如下:
filter(func or None, sequence)->list,tuple or string
(1) 参数func是自定义的过滤函数,在函数func(item)中定义过滤规则。果然func为“None”,则过滤项Item都为真,返回所有序列的元素。
(2) 参数sequence为待处理的序列。
(3) filter()函数的返回值由func()的返回值组成的序列,返回的类型与参数sequence的类型相同。
示例代码:
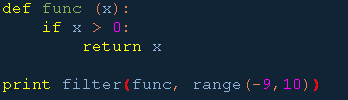
输出结果:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
注意:filter()的过滤函数func()的参数不能为空,否则,没有可以存取sequence元素的变量,func()也不能处理过滤。
2. reduce()
对序列中元素的连续操作可以通过循环来处理(例如对某个序列中的元素进行累加操作)。Python提供的reduce()也可以实现连续处理的功能。
声明如下:
reduce(func,sequence[,initial])->value
(1) 参数func是自定义的函数,实现对参数sequence的连续操作。
(2) 参数sequence为待处理的序列
(3) 参数initial可以省略,如果initial不为空,则initial的值将首先传入func()进行计算。如果sequence为空,则对initial的值进行计算。
示例代码:
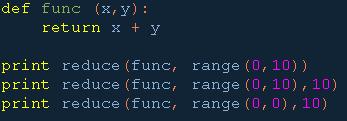
输出结果:
45
55
10
注意:如果用reduce()进行累计计算,必须在func中定义两个参数,分别对应加法运算符两侧的操作数。
3. map()
函数声明如下:
map(func,sequence[,sequence,…])-> list
map()的返回值是对序列元素处理后的列表。
示例代码:

输出:
[1, 4, 27, 256]
[1, 16, 27, 16]
注意:如果map()提供了多个序列,则每个序列中的元素一一对应进行计算。如果每个序列的长度不同,则短的序列后补充“None”,在进行计算。
函数
函数的定义:
def 函数名(参数1[=默认值],参数2[=默认值]…):
…
return 表达式
函数的参数:
在程序的开发过程中,常常需要传递可变长度的参数。在函数的参数前使用标识符“*”可以实现这个要求。“*”可以引用元组,把多个参数组合到一个元组中:

输出:
(1, 2, 3, 4)
由此可见,由于参数中使用了“*args”的形式,因此传入的实际参数被“打包”到一个元组中。
Python还 提供了另一个标识符“**”。在形式参数前面添加“**”,可以引用一个字典。根据实际参数的赋值表达式生成字典。
示例代码:

输出:
['three', 'tow', 'one']
['3', '2', '1']
find: 1
find: 3
上面的代码实现了在一个元组中匹配一个字典中的元素。定义函数时,设计两个参数。一个是待匹配的元组,表示为“*t”。另一个是字典,表示为“**d”。函数调用时,实际参数分为两部分,一部分参数是若干个数字或字符串,另一部分参数是赋值表达式。
如下图:

注意:“*”必须写在“**”的前面,这是语法规定。
函数的返回值
1.在函数没有return语句时,默认返回值为“None”。“None”是Python中的一个对象,不属于数字也不属于字符串。当函数中的return语句不带任何参数时,返回的结果也是“None”:

2.如果需要返回多个值,可以把这些值“打包”到元组中。在调用时,对返回的元组“解包”即可。
示例代码:

函数的嵌套
1. 在函数外定义函数
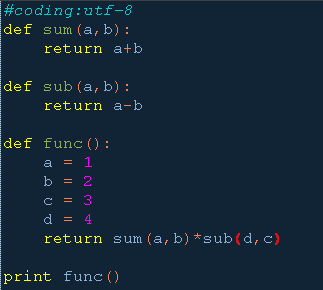
2. 在函数内部定义函数

3. 嵌套函数,直接使用外层函数的变量
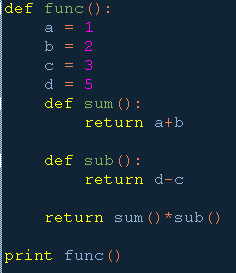
lambda函数
lambda函数用于创建一个匿名的函数,函数名未和标识符进行绑定。使用lambda函数可以返回一些简单的运算结果。
lambda函数的格式如下:
#赋值:
func = lambda 变量1,变量2…:表达式
#调用
func()
示例代码:

输出:
<function <lambda> at 0x00AFBC30>
<function <lambda> at 0x00AFBC70>
6
注意:lambda函数中只能使用表达式,不能使用判断,循环等多重语句。
Generator函数
生成器(Generator)的作用是一次产生一个数据项,并把数据项输出。Generator函数可以用在for循环中遍历。Generator函数所具有的每次返回一个数据项的功能,使得迭代器的性能更佳。
Generator函数的定义如下:
def 函数名(参数列表):
。。。
yield 表达式
Generator函数的定义和普通函数的定义没有什么区别。只要在函数体内使用yield生成数据项即可。
Generator函数可以被for循环遍历,而且可以通过next()方法获得yield生成的数据项。
示例代码:

注意:yield保留字和return语句返回值的执行原理各不相同。yield生成值后并不会终止程序的执行,返回值后程序继续往后执行。return返回后,程序将终止执行。