DirectX10 游戏的美好未来
转自:http://www.pcpop.com/doc/0/161/161825_8.shtml
● 第三章 第一节技术背景 directX 的发展和API相关基本常识,DX10新特点概要。
Microsoft发布的DirectX 10代表了自从可编程Shader出现以来在3D API方面的最巨大的进步。通过一番脱胎换骨般的重建,DirectX 10展现出一系列非常醒目的新特性,包括高度优化的运行时,强大的Geometry Shader,纹理数组等等;这些特性将引领PC实时三维图形进入一个全新的世界。
在过去的十年中,DirectX已经稳步成为了Microsoft Windows平台上进行游戏开发的首选API。每一代的DirectX都带来对新的图形硬件特性的支持,因此每次都能帮助游戏开发者们迈出惊人的一步。通过不断的首先推出完全支持新版本DirectX全部特性的图形处理器,NVIDIA已经逐渐成为3D图形硬件业界的先驱者。当DirectX 10出现的时候,他们再次继承了这一传统。
DirectX 10 是自DirectX诞生以来,首次进行的一次彻底的重新设计。为了使得产品成为主要的DirectX硬件平台,NVIDIA为DirectX 10 设计了一套全新的GPU架构——Geforce 8800系列架构。这套新的架构是NVIDIA历时三年的独立研发以及与Microsoft的协作的结晶。基于这套架构的第一代产品,就是世界上第一个完全支持DirectX 10的GPU——Geforce 8800 GTX。
Geforce 8800 GTX GPU拥有很多特性方面的新记录,它已经成为目前世界上最复杂和最强大的GPU。128个工作频率在1.35GHz的处理器阵列,使它在执行效率上几乎找不到任何对手。而16x抗锯齿,128位HDR渲染和新的各项异性过滤引擎,使得可与好莱坞电影媲美的实时三维特效成为可能。
● 第三章 第二节DX10的架构特性 以及带来的好处。
DirectX之所以在广大的开发者中流行,是得益于它的简单易用和丰富的功能特性。然而,DirectX一直被一个主要的问题所困扰,那就是高CPU负载。
在图形编程API出现之前,三维程序直接向图形硬件发送图形命令来完成绘制工作。虽然这样绘制效率相当高,但是程序中要应对各种不同硬件上的不同命令,这使得开发工作十分困难,且程序中很容易出错。当越来越多不同的图形硬件冒出来的时候,这就成了一件十分不能忍的事。
于是便出现了像DirectX和OpenGL这样的图形API。它们在图形硬件和应用程序之间架起了一个中间层,这样,应用程序可以使用统一的图形编程代码,而对底层各种硬件的适应,则由图形API来完成。这就将游戏程序员们从与大量的图形硬件交换意见的恶梦中解救出来,使他们能够将精力集中在“制作伟大的游戏作品”上面^_^
但是这样就完美了么?不是的。每次DirectX从应用程序那里接收到一条命令,它就需要先对这条命令进行分析和处理,再向图形硬件发送相对应的硬件命令。由于这个分析和处理的过程是在CPU上完成的,这就意味着每一条3D绘图命令都会带来CPU的负载。这种负载给3D图象带来两个负面影响:限制了画面中可以同时绘制的物体数量;限制了可以在一个场景中使用的独立的特效的数量。这就使得游戏画面中的细节数量受到了很大的限制。而使图像具有真实感的重要因素,偏偏是细节量。
DirectX 10的一个主要目标就是最大地降低CPU负载。它主要通过三个途径来达到这个目的:第一,修改API核心,使得绘制物体和切换材质特效时的消耗降低;第二,引入新的机制,降低图形运算操作对CPU的依赖性,使更多的运算在GPU中完成;第三,使大量的物体可以通过调用单条DirectX绘制命令进行批量绘制。下面我们就来仔细的看一下这三种方式:
1.降低绘制消耗
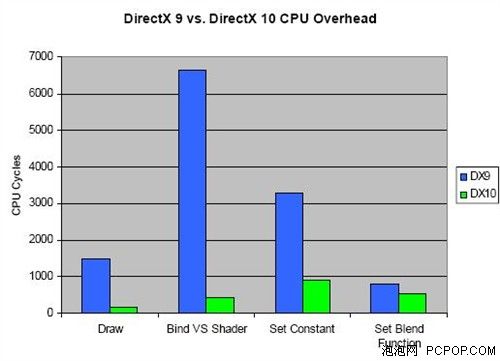
第一种方式的一个重要例子就是DirectX 10中对三维数据和绘制命令进行验证过程的修改。所谓三维数据和命令的验证,是指在DirectX绘制图形之前,对传给它的图形数据和绘制命令进行格式和数据完整性的检查,以保证它们被送到图形硬件时不会导致硬件出问题;这是很必要的一步操作,但是不幸的是它会带来很大的性能开销。

从上表我们可以很容易的看出,在DirectX 9中,每次绘制一帧画面之前,都会对即将使用的相关数据进行一次验证。而DirectX 10中,仅当这些数据被创建后验证一次。这很明显是可以大大提高游戏进行中的效率的。
2.降低CPU依赖性
在降低CPU依赖性方面,DirectX 10 引入的三个重要机制就是:纹理阵列(texture arrays)、绘制断言(predicated draw)和数据流输出(stream out)。不要被这三个晦涩的名词吓倒,实际上它们是三个不难理解的机制。
首先我们来看纹理阵列。传统的DirectX在多张纹理中进行切换的操作是一个很消耗CPU的操作,因为每切换一次,都要调用一次DirectX的API函数。而每绘制一个使用新纹理的物体,就要进行一次这样的切换操作;有时为了实现特殊的材质特效,绘制一个物体时可能就要切换好几次纹理,开销很大。
所以,以前游戏美工们经常索性将大量的小纹理拼合到一张大的纹理中,通过给不同的三维物体分配这张大纹理的不同局部以期减少纹理切换,提高游戏运行效率。然而,想想也知道,这件事做起来会非常麻烦,而且DirectX 9中对纹理的尺寸的限制是4048×4048像素,也就是说,如果要容下更多的小纹理块,可能就得开辟很多张这样的大纹理。
DirectX 10引入的新的纹理阵列机构,将允许在一个由显卡维护的阵列中容纳512张单独的纹理,而且,在shader程序中可以使用一条新的指令来获取这个阵列中的任意一张纹理。而这种shader指令是运行在GPU中的;这样,就把原来要消耗很多CPU时间的纹理切换工作轻松地转给了GPU。由于纹理一般是直接放在显存中的,所以这件事由同显存一起放在显卡上的GPU来完成真是天经地义,大快人心^_^。现在,在应用程序的层面,只要一开始设置好纹理阵列中的纹理,然后每次绘制一个物体时为它指定一个纹理的索引号,并同物体三维数据一起传递到shader中,就可以放心的让GPU来给物体选纹理了。
然后说说绘制断言。在一般的三维场景里,很多物体都是完全被别的物体挡在后面的。这时候如果要显卡绘制这些物体就是白费力气。尽管高级的GPU可以通过硬件算法将场景画面中被挡住的像素(注意是像素)预先剔除,但是仍然会有一些处理消耗。例如,一个完全被挡住的复杂的角色模型,它的身上可能有几千个顶点,需要做复杂的骨骼皮肤动画处理、顶点光照运算等等——然而,GPU是在处理完这些顶点之后,并要把这个角色模型一个像素一个像素地画到画面中时,才开始判断每个像素是否需要画——当所有的像素都被剔除了时,之前做的顶点处理也就全白费了-_- || 于是,游戏开发者们想出了一个方法来解决这个问题,这就是绘制断言。
简言之就是用一个可以代表某个复杂物体的简单物体来判断这个物体是否被全部挡住了——例如用一个可以罩住刚才那个角色的大盒子,当绘制这个盒子时,如果所有的像素都被P掉了,也就说明这个盒子肯定完全看不见,更甭说里边的角色了,也就不用做什么骨骼皮肤运算啦之类的操作了。一个盒子顶多有八个顶点,这学过初中几何的人都知道,相比处理几千个顶点,开销小得多。但是,以前这步中有些部分也是要在CPU中完成的。现在,在DirectX 10中,已经彻彻低低的交由GPU来做了^_^。真是很周到啊。
最后来看看数据流输出。这是一个DirectX 10中的非常重要的特性,它允许GPU上的Vertex shader或Geometry shader向显存中添加数据!您也许觉得这感觉没什么,然而在以往的vertex shader中是史无前例的。以前的DirectX中,vertex shader只能读取显存中已有的顶点数据;而DirectX 10中引入的新的Geometry shader,不但能读取显存中的顶点数据、几何(点、线段、三角形)数据,还可以生成新的几何数据放回显存。鉴于其重要性,这一机制我们将在第四节:几何Shader以及Stream Out中单独介绍。
3.批量绘制
在DirectX 9中,对渲染状态的管理一直是一个十分消耗CPU时间的操作。所谓渲染状态,是指显卡进行一次绘制操作时所需要设置的各种数据和参数。例如,要绘制一个人物角色,就需要先设置他的几何模型数据的数据格式、纹理过滤模式、半透明混合模式等等——每设置一项,都要调用一次DirectX API,占用大量CPU时间,极大的约束了渲染的性能。
为了使这些操作能够批量的进行,DirectX 10中引入了两个新的结构——状态对象(state object)和常量缓冲(constant buffers)。
状态对象就是将以前的零散状态按照功能归结为几个整体,这样,当要设置一系列相关状态时,无需为每一个状态来调用一次DirectX API,只需要调用一次将这些状态统统设置到显卡中去。
而常量缓冲是另一个十分有意义的机制。在绘制模型前的准备工作中,渲染状态的设置只是一小部分。还是拿绘制人物角色来说,能照亮这个人的光源的颜色、位置、类型、范围等等,都要提前设给显卡;为了通过骨骼来带动他的皮肤做出姿势,还要设置骨骼的位置信息等等——总之是很多东西;而这些东西主要都是通过GPU中的常量寄存器(constant registers)来传递给它的。每个常量寄存器可以存储一个4维的浮点型向量(即四个浮点数)。常量寄存器是游戏程序向GPU输入游戏场景中数据的重要途径。在DirectX 9中,这种常量寄存器的数量是十分有限的,这在下文中的对比图表中我们也可以看到;而且每次更新一个寄存器,都需要调用一次DirectX API函数。而DirectX 10中,使用了常量缓冲(constant buffer)这种结构;在每个constant buffer中都可以容纳4096个常量,而且只需调用一次API就可以更新一大批常量。

![]() 采用constant buffer绘制的大量克隆物体。
采用constant buffer绘制的大量克隆物体。
图片来源:Microsoft DirectX 10 SDK
举一个具体些的例子来对比一下:在以前,如果程序中想在场景里画很多的树木和杂草,可以采用一个类似于“克隆”的方法:先做好一棵或几棵树、草的三维模型,然后在画一帧画面时,不停的在不同的位置、方向,用不同的大小为参数,调用DirectX API的绘制函数来画这些模型,就可以画出很多草木来;但是每画一棵,都要设置一大堆参数后调用一次API;这是很耗CPU时间的,所以在以前的游戏中很难有大规模且细节丰富的森林场景。
而在DirectX 10中,我们可以先把树、草的几个模型设给显卡,然后将所有要画的树木的位置、方向和大小一次性的写入到constant buffer中,然后告诉DirectX——画!显卡就一下把所有的树木和草都一起绘制出来了^_^ 这样,像Far cry 2 那样的游戏,才能营造出十分逼真的森林效果。
总结
总之,DirectX 10降生到这个世上,就是为了带走由于CPU负载过大而给游戏图形效果带来的苦难。通过提前数据验证、纹理阵列、绘制断言、数据流输出、状态对象、常量缓冲等机制,帮助游戏的效果和效率上升到一个新的高度。
● 第三章 第三节Shader Model 4.0
当Shader Model 3.0的光彩尚未退去的时候,在DirectX 10中,又引入了Shader Model 4.0。它包含下面几项革新?/P>
1 加入了一种新的Shader——Geometry shader
通过它可以编程操纵几何图元;为vertex、geometry、pixel shader采用了统一的Sahder架构。Geometry shaders是可编程图形流水线的一大进步。它第一次允许由GPU来动态的生成和销毁几何图元数据。通过和新的数据流输出功能配合使用,许多以前无法实时使用的算法现在都可以在GPU中使用了。在下一节,将仔细讨论Geometry shaders。
2 统一的Shader架构
在DirectX 9中,Pixel shader总是在各个方面落后于vertex shaders,包括常量寄存器个数、可用的指令个数、shader长度等。程序员需要区分对待这两种shader。
而在shader model 4中,这vertex、geometry和pixel shader有着统一的指令集、同样的临时/常量寄存器个数。它们将平等的共享GPU中的所有可用资源。在游戏程序中不用再考虑每种shader自身的限制了。
3 百倍于DirectX 9的可用资源
对于shader中可用的资源,在Shader model 4.0中比原来有了惊人的扩充。就像早期的程序员们绞尽脑汁的省着用可怜的640k内存一样,在使用以前的DirectX开发游戏的过程中,程序员需要小心翼翼的分配珍贵的shader寄存器资源。寄存器的数量,直接影响着shader程序的复杂度。这和在640k内存的机器上,怎么也不可能写出Microsoft Office这样的大规模软件是同一个道理。而在DirectX 10中,将临时寄存器由原来的32个扩充到了4096个,将常量寄存器由原来的256个扩充到了65536个!而这些并不仅仅是DirectX给出的理论值——在Geforce 8800架构中,它们都是实实在在的在显卡上面的!
4 更多的纹理
在Shader Model 4.0中提供了对纹理阵列(Texture arrays)的支持。在前文中已经对纹理阵列有了比较详细的介绍,在这里只着重介绍一下与shader相关的部分。在每个纹理阵列中,最多可以保存512张同样大小的纹理。而且每张贴图的分辨率被扩展到了8192×8192。更大的分辨率意味着纹理中更丰富的细节。在一个shader中能够同时访问的纹理个数被增加到了128个,也就是说在每次执行同一个shader时,可以使用一个纹理阵列的512个纹理中的128个。所以说,在DirectX 10中,纹理的多样性和细节程度将会有大幅的提升。

![]() 使用纹理阵列实现细致的纹理
使用纹理阵列实现细致的纹理
5 更多的渲染目标(Render Target)
所谓渲染目标,就是指GPU可以把画面绘制到的目标,我们可以把它理解为GPU的画布。一般来说,渲染目标被输出到屏幕上,这样我们就能看到画好的画面了;但是有时为了实现一些特效,某些渲染结果并不直接画到屏幕上,而是再返给GPU做进一步的特效处理;而且渲染目标中也不一定是画好的画面的颜色信息。
根据特效的需要,它们可能是每个物体距离屏幕的远近,或者物体表面上每个像素的方向,或者每个物体表面的温度(为了实现《分裂细胞》中那种热能感应器的效果)…总之为了实现特效,可以按需要在其中绘制任何信息。为了提高这种情况下的效率,很多新的显卡都支持在同一遍Shader执行结束后,同时把不同的信息绘制到不同的渲染目标中。在DirectX 9中就已经支持这种机制了,但是它约束最多同时向四个渲染目标绘制。而DirectX 10将这个数量提升了一倍。
6 新的HDR颜色格式
要说这些年来在实时图形界炒得最热的概念,应该是HDR了。它通过采用浮点格式的颜色格式来为纹理、光照等计算提供极大的精度和颜色范围(以前的纹理一般都是采用整数型的颜色格式)。尽管最后显示到屏幕上还是每个颜色通道8位的整数格式,但是以前由于在材质、光照计算中纹理也是用每通道8位的格式来参与计算,所以在显示到画面之前,很多细节就在低精度的运算中丢失了。
而采用每颜色通道16位浮点数的纹理,能够保证在运算过程中几乎没有颜色细节信息的丢失。另外,采用16位浮点格式的颜色通道,可以表现更大的颜色范围。这些就是HDR的优越性。对于玩家来说,当游戏中的画面罩上一层HDR效果后,立刻显得和真正的照片一样,有朦胧的光晕、细致的高光和十分自然的色调。在玩《极品飞车9》时,充满风格的色调让人有一种置身于电影里的感觉。

![]() HDR(高动态范围)渲染。图片来源:Futuremark
HDR(高动态范围)渲染。图片来源:Futuremark
然而,采用每个颜色通道16位浮点数的格式,比采用每通道8位的整数格式的纹理要多占据一倍的显存;这给绘制的效率带来了负面的影响。所以在DirectX 10中引入了两个新的HDR格式。第一种是R11G11B10,表示红色和绿色通道用11位浮点数,而蓝色通道采用10位浮点数表示。那么,为什么不都用11位呢?这是为了凑32这个整数。学过计算机的人都知道,当内存中一个数据单元的宽度是32位时,对它的操作效率最高;而且在纹理数据中一般要求每个像素的数据宽度是2的倍数,如2,8,16,32,64等等。又因为人眼对蓝色的敏感度不如对红色和绿色,所以它比其他两个通道少用了一位。
另外一种格式是采用每通道9位尾数、所有通道共享5位指数的形式(众所周知,在计算机中,浮点数是采用尾数附加指数的形式来表示的),加起来还是32位。这些新的格式使得纹理能够与原来占用同样多的显存空间,避免了大的空间和带宽消耗。同时,为了适合需要精确的科学计算的场合,DirectX 10和Geforce 8800 GTX完全支持每通道32位(4个通道加起来128位)精度的浮点数纹理。
总结
上面提到的这些扩充和提高,对于图形程序员来说是一件非常爽的事。他们可以摆脱束缚,创建出包含前所未有的细节度的实时游戏场景;对于玩家来说也是一件非常爽的事,因为他们的眼球有得养了。
● 第三章 第四节几何Shader以及 Stream Out
直到现在,图形硬件只有在GPU上操作已有数据的能力。顶点着色器(Vertex Shader)和像素着色器(Pixel Shader)都允许程序操作内存中已有的数据。这种开发模型非常成功,因为它在复杂网格蒙皮和对已有像素进行精确计算方面都表现的很出色。但是,这种开发模型不允许在图像处理器上生成新数据。当一些物体在游戏中被动态的创建时(比如新型武器的外形),就需要调用CPU了。可惜现在大多数游戏已经很吃CPU了,游戏进行时动态创建庞大数量新数据的机会就变得微乎其微了。
Shader Model 4.0中引入的几何着色器(Geometry Shader),第一次允许程序在图像处理器中创建新数据。这一革命性的事件使得GPU在系统中的角色由只可处理已有数据的处理器变成了可以以极快速度既可处理又可生成数据的处理器。在以前图形系统上无法实现的复杂算法现如今变成了现实。使用DirectX 10和Geforce 8800 GTX,类似模板阴影(Stencil Shadow)、动态立方体贴图(Dynamic Cube Map)、虚拟位移贴图(Displacement Mapping)等依靠CPU或多通道渲染(Multi-Pass Rendering)的算法效率提升了很多。

![]() DirectX 10流水线加入了几何着色器和数据流输出(Stream Output),使GPU可以在不用CPU干涉的条件下进行反复运算。
DirectX 10流水线加入了几何着色器和数据流输出(Stream Output),使GPU可以在不用CPU干涉的条件下进行反复运算。
几何着色器被放在顶点着色器和光栅化阶段(Rasterizer)中间。所谓光栅化,就是一行一行的扫描每个三角形,把它们一个像素一个像素的绘制到画面上。几何着色器把经过顶点着色器处理过的顶点当作输入,对于每个顶点,几何着色器可以生成1024个顶点作为输出。这种生成大量数据的能力叫做数据扩大(Data AmplificATIon)。同样的,几何着色器也可以通过输出更少的顶点来删除顶点,因此,就叫做数据缩小(Data MinimizATIon)。这两个新特性使GPU在改变数据流方面变得异常强大。
1 细分的虚拟位移贴图(Displacement Mapping with TessellATIon)
几何着色器终于让虚拟位移贴图可以在GPU上生成了。虚拟位移贴图是在离线渲染系统中非常流行的一项技术,它可以用一个简单的模型和高度图(Height Map)渲染出非常复杂的模型。高度图是一张用来表示模型上各点高度的灰度图。渲染时,低多边形的模型会被细分成多边形更多的模型,再根据高度图上的信息,把多边形挤出,来表现细节更丰富的模型。
因为在DirectX 9中,GPU无法生成新的数据,低多边形的模型无法被细分,所以只有小部分功能的虚拟位移贴图可以实现出来。现在,使用DirectX 10和Geforce 8800 GTX的强大力量,数以千计的顶点可以凭空创造出来,也就实现了实时渲染中真正的细分的虚拟位移贴图。
2 基于边缘(Adjacency)的新算法
几何着色器可以处理三种图元:顶点、线和三角形。同样的,它也可以输出这三种图元中的任何一种,虽然每个着色器只能输出一种。在处理线和三角形时,几何着色器有取得边缘信息的能力。使用线和三角形边缘上的顶点,可以实现很多强大的算法。比如,边缘信息可以用来计算卡通渲染和真实毛发渲染的模型轮廓。

![]() 使用几何着色器的非照片模拟渲染
使用几何着色器的非照片模拟渲染
(Non-Photorealistic Rendering - NPR)
3 数据流输出(Stream Output)
在DirectX 10之前,几何体必须在写入内存之前被光栅化并送入像素着色器(pixel shader)。DirectX 10引入了一个叫做数据流输出(Stream Output)的新特性,它允许数据从顶点着色器或几何着色器中直接被传入帧缓冲内存(Frame Buffer Memory)。这种输出可以被传回渲染流水线重新处理。当几何着色器与数据流输出结合使用时,GPU不仅可以处理新的图形算法,还可以提高一般运算和物理运算的效率。
在生成、删除数据和数据流输出这些技术的支持下,一个完整的粒子系统就可以独立地在GPU上运行了。粒子在几何着色器中生成,在数据扩大的过程中被扩大与派生。新的粒子被数据流输出到内存,再被传回到顶点着色器制作动画。过了一段时间,它们开始逐渐消失,最后在几何着色器中被销毁。
● 第三章 第五节高级渲染语言(HLSL 10)
DirectX 10 为以前的DirectX 9中的“高级着色语言”(High Level Shading Language )带来了诸多功能强大的新元素。其中包括可以提升常量更新速度的“常量缓冲器”(Constant Buffers),提升渲染流程中操作数据的灵活性的“观念”(view),为更广泛的算法所准备的“整形与位指令”(Integer and Bitwise Instructions),添加了switch语句。
1 常量寄存器(Constant Buffers)
着色程序同普通的程序一样需要使用常量来定义各种参数,例如光源的位置和颜色,摄像机的位置和投影矩阵以及一些材质的参数(例如反光度)。在整个渲染的过程中,这些常量往往需要频繁的更新,而数以百计的常量的使用以及更新无疑会给CPU带来极大的负载。DirectX 10中新加入的常量缓冲器可以根据他们的使用频率将这些常量分配到指定的缓冲器中并协调的对其进行更新。
在一个着色程序中DirectX 10支持最多16个常量缓冲器,每一个缓冲器可以存放4096个常量。与其相比DirectX 9实在是少得可怜,因为它在每个着色程序中同时最多只能支持256个常量。

相比DirectX 9,DirectX 10不仅提供了更多的常量,最主要的是它大幅的提升了常量更新的速度。对那些被分配到同一个缓冲器中的常量,我们只需进行一次操作就可以将它们全部更新完毕,而非单个单个的去更新。
由于不同的常量更新的时间间隔各异,所以跟据使用的频率来对他们进行组织就可以获得更高的效率。举例来说:摄像机的视矩阵只在每一祯之间发生改变,而像贴图信息这样的材质参数却会在图元切换时发生改变。于是这些常量缓冲器被分成了两个部分——那些每祯更新的常量缓冲器专门存放那些需要在两祯间更新的常数并在两祯间一次把他们全部更新,另外的图元切换更新的常量缓冲器也同理。这样就会将更新常量过程中的一些不必要的工作消除,以便让整个着色器脚本比在DirectX 9中运行的更加顺畅。
2 Views
在DirectX 9中,着色器(shader)中的数据的类型是被严格划分开的。例如,顶点着色器用到的顶点缓冲器中的数据不能当作贴图的数据来让像素着色器使用。这样就将特定的资源类型同其相对应的渲染流程中的特定步骤紧密地结合了起来,同时限制了资源资源在整个渲染流程中可以使用的范围。
DirectX 10舍弃了“严格区分的数据类型”这一概念。当一段数据被创建,那么DirectX 10所做的仅仅是将其简单的当作内存中的一段比特域(bit field)来对待。如果要想使用这一段没有定义类型的比特域数据就必须通过使用一个“view”。 使用“view”,相同的一段数据就可以有各种各样的方法来读取。DirectX 10支持对同一段资源在同时使用两个“view”。
通过这种多重“view”的手段,就可以在整个渲染流程的不同部分以不同目的使用同一段数据。例如:我们可以通过像素着色器将一段几何数据渲染到一张纹理上,之后顶点着色器通过一个“view”将这张纹理视为一个顶点缓冲器并将其中的数据作为几何数据渲染。“view”通过在整个渲染流程中的不同步骤重复使用同一段数据为“数据处理”带来了更大的灵活性,帮助开发者实现更多更有创意更精彩的特效。
3 整形与位运算指令 (Integer and Bitwise Instructions)
在新的高级着色器语言中添加了“整形与位指令”。这样把“整形与位运算指令”的操作加入其基础运算函数的好处在于帮助一些算法在GPU上的实现。开发者终于可以直接使用整形而非从浮点中强转来计算出准确的答案。数组的索引号现在可以轻松的计算出来。GPU无整形运算的时代终于被终结了。这将为shader程序的开发带来很大的便利。
4 Switch 语句(Switch Statement)
终于,HLSL 10可以支持switch语句了!!!这将大幅简化那些有着大量判断(分支)的着色器脚本的编码。一种用法就是建立一个“航母级的着色器(shader)程序”——包含了大量的小型着色器程序并且自身体形巨大的着色器程序。在这个“航母级的着色器程序”,我们可以通过设定一个材质ID在switch语句中判断来轻松的在渲染同一个图元时切换不同的特效。也就是说,现在一个军队中的每个士兵身上都可以拥有各自不同的特效了。
● 第三章 第六节其他改进
● 第三章 第六节 第一小节 alpha to coverage
在游戏中,经常使用带有半透明信息纹理的多边形模型来模拟复杂的物体,例如,草、树叶、铁丝网等。如果使用真正的模型,一颗边缘参差不齐的小草可能就要消耗掉几百个多边形;然而采用透明纹理,可以只用2~3个多边形就解决了。

![]() 半透明纹理示意——一片树叶
半透明纹理示意——一片树叶
然而,当使用这种有半透明信息的纹理时候,它的不透明和透明部分的边界线上,常常会出现难看的锯齿。采用半透明混合技术可以解决这个问题,但是它需要把场景中所有这类物体按照由远到近的顺序来绘制,才能保证它们的遮挡关系是正确的——这是十分消耗CPU时间的,所以很不可取。在以前,alpha测试和混合简直就是图形程序员的噩梦。
在DirectX 10中,使用了一种新的技术叫做Alpha to coverage。使用这种技术,在透明和不透明交界处的纹理像素会被进行多极取样(Multi-sample),达到抗锯齿的效果。这就在不引入大的性能开销的情况下华丽的解决了这个问题^_^ 室外场景的游戏将大大受益于这种技术。树叶、铁丝网、草的边缘将会更加柔和、圆滑。

![]() 使用Alpha to coverage技术,叶片的边缘更加平滑。
使用Alpha to coverage技术,叶片的边缘更加平滑。
● 第三章 第六节 第二小节 shadow map filtering
阴影图(Shadow map)技术已经逐渐成为了渲染真实感阴影的流行技术。在包括《战争机器》、《分裂细胞:双重特工》、《Ghost Recon》、《刺客信条》等的各大次世代游戏中都能看到它的身影。然而,由于shadow map的尺寸限制,用它实现的阴影边缘往往有明显的锯齿。在DirectX 10中,提供了对shadow map进行过滤的功能的正式支持。经过过滤后,阴影的边缘将会变得更加柔和。
● 第三章 第七节游戏效果
DirectX 10为游戏开发者提供了很多新的特性,采用这些特性可以用来开发大量的次世代图形效果。然而,由于这是基于强大、灵活的可编程特性基础上的,所以很难简单的指出这些特性都带来了哪些效果。实际上,很多图形效果都是对这些特性进行综合运用的结果。在这一部分,让我们来仔细的看一下几种次世代特效技术,感受一下新的DirectX 10特性在其中起到的作用。
● 第三章 第七节 第一小节 次世代Instancing技术
在上文中,我们已经用这张图来说明DirectX 10的常量缓冲器特性。其实,这里采用的技术有一个学名叫做Instancing,大意就是通过一个或几个模型来复制出它们的很多实例,实现满山遍野的树木、敌兵那样的效果。这种技术在DirectX 9时代就已经出现了,但是有很多的限制,例如模型不能有动画,所有的模型实例必须使用同一张纹理贴图和同一种材质效果,等等。这就给这项技术带来很多遗憾的地方——玩家肯定不喜欢看见游戏里满山遍野的敌人或树木都长成一个模样,或者只有那么几种模样。
在DirectX 10中,通过常量缓冲器、纹理阵列、动态shader执行分支等特性,将Instancing技术从这些局限中解放了出来。模型的实例没必要使用同一张纹理贴图;它们可以通过自己本身的纹理来从纹理阵列中取出各自的纹理;它们甚至可以有不同的特效——程序员可以写一个包含很多特效的“超级”shader,然后为每个模型实例运用这个shader程序的不同执行分支部分,从而给不同的模型赋以不同的材质特效。甚至连为每个模型实例使用骨骼蒙皮动画这种需要大量变换矩阵操作的问题,在16×4096常量寄存器的强大攻势下都可以迎刃而解。
“克隆人”的时代已经结束了^_^ 通过DirectX 10的高级特性,Instancing将允许每个模型实例拥有它的个性:纹理贴图,pixel和vertex shader,以及动作动画。每个实例都将会有它自己的生命。
● 第三章 第七节 第二小节 基于象素级别的位移贴图技术
在介绍这项技术之前,首先请允许我对工作在坐落于北京海淀区知春路的微软亚洲研究院/工程院的工程师们致以崇高的敬意\ ^ ^ /。因为这项技术的实现方法,是由这些中国的工程师们研究、创造出来的。

![]() 实时每像素位移贴图。图象来源:Microsoft DirectX SDK。
实时每像素位移贴图。图象来源:Microsoft DirectX SDK。
位移贴图技术,用过3DS MAX的读者可能不会感到陌生。在3DS MAX中,这种技术有时也被翻译成“置换贴图”,其核心思想就是在制作三维模型时采用比较低的细节,然后给这个模型赋上一张表面高度图;在渲染时,会根据这张高度图来修改模型的表面,使它们隆起或凹陷——这样,就可以十分省力的给模型表面加上真正的凹凸不平的效果。毕竟,在3DS MAX里一个点一个点的修改模型表面来添加凹凸细节,要比直接拿Photoshop绘制一张高度图麻烦的多。
位移贴图要比单纯的normal map技术的凹凸贴图逼真——因为它是真正的将模型的表面进行修改,抬高或降低它们。然而,由于它需要在渲染时将模型表面进行细分,即将原来的一个多边形分成大量的小多边形,这样才能有足够多的顶点来进行移动。这在原来的DirectX中是不能实现的,因为那时没有geometry shader,不能动态生成多边形图元,也就不能实现动态的多边形细分。即使在有了geometry shader以后,将多边形细分也是一个消耗性能很大的操作。
然而,微软亚洲工程院/研究院的工程师们另辟蹊径,创造了一种新的每像素位移贴图技术。它的大致过程是,将简单模型表面的三角形向上拉伸,成为一个三棱台,这样它就具有了一定的体积;而它的高度,就是模型表面根据高度图进行位移后能达到的最大高度。然后在填充三角形的每个像素时,通过将观察者的视线和这个三棱台进行求交,得到一个相对于这个三棱台的交线段。
由于高度图是相对于这个三棱台的,只有同样使用相对于这个三棱台的交线段,才能正确的求出线段和高度图所代表的表面高度的交点。然后再通过这个交点来计算应该把颜色纹理中的哪个点绘制到屏幕上。在这里只是简单介绍了一下这种技术的大体原理,实际的实现算法比这个要复杂,因为需要克服各种各样的问题。

![]() 每像素位移贴图原理示意。图片来源:Microsoft DirectX SDK
每像素位移贴图原理示意。图片来源:Microsoft DirectX SDK
总结
还有很多新出现的基于DirectX 10和Geforce 8800架构的次世代图形特效技术,在这里就不一一赘述了^_^ 相信随着时间的推移,越来越多的实时图形特效技术将会大放异彩,实时演算的画面效果达到非实时CG动画效果的一天终会到来。