最近团队中有分析的场景,用到了JStorm来做数据的实时分析,于是花时间对于一些概念做了了解。
什么是Storm?
这个的话出来应该有几年时间了,阿里巴巴也重写了一套JStorm,核心的类名都是服用的Storm的,他是一套实时数据处理系统,容错行好,然后足够稳定,目前很多数据实时分析的场景,选择Storm的越来越多了。
核心概念介绍
Nimbus:负责在集群里面发送代码,分配工作给机器,并且监控状态。全局只有一个。相当于master的角色。
Supervisor:监听分配给它那台机器的工作,根据需要启动/关闭工作进程Worker。每一个要运行Storm的机器上都要部署一个,并且,按照机器的配置设定上面分配的槽位数。
zookeeper:Storm重点依赖的外部资源。Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的。Nimbus也是根据Zookeerper上的心跳和任务运行状况,进行调度和任务分配的。两者之间的调度器。
Spout:在一个topology中产生源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。Spout是一个主动的角色,其接口中有个nextTuple()函数,storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
Bolt:在一个topology中接受数据然后执行处理的组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作。
Topology:storm中运行的一个实时应用程序,因为各个组件间的消息流动形成逻辑上的一个拓扑结构。
Worker:具体处理组建逻辑的进程,
Task:不再与物理进程对应,是处理任务的线程,
Stream:源源不断传递的tuple就组成了stream。
Tuple:一次消息传递的基本单元。本来应该是一个key-value的map,但是由于各个组件间传递的tuple的字段名称已经事先定义好,所以tuple中只要按序填入各个value就行了,所以就是一个value list.
整体物理布局
放一张Nimbus和Supervisior的关系图

数据处理的流程
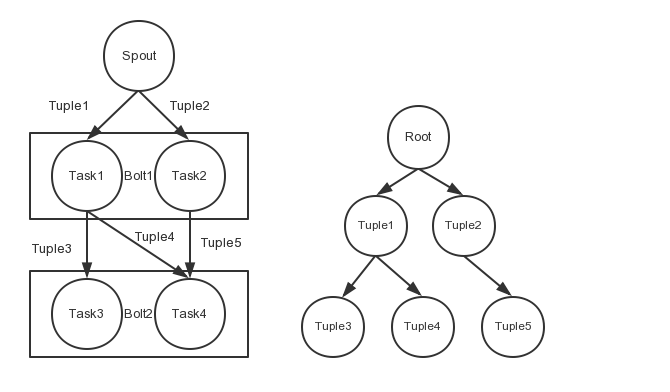
Topology是一个完成的数据处理流程,在Nimbus提交jar,然后Nimbus分发到Supervisior中,Sport负责数据流的读入,是入口,然后Bolt是处理数据加工数据的节点,中间数据被封装在Tuple中,然后Bolt节点可以产生新的Tuple。总体流程图如下

Storm如何保证消息被最终处理
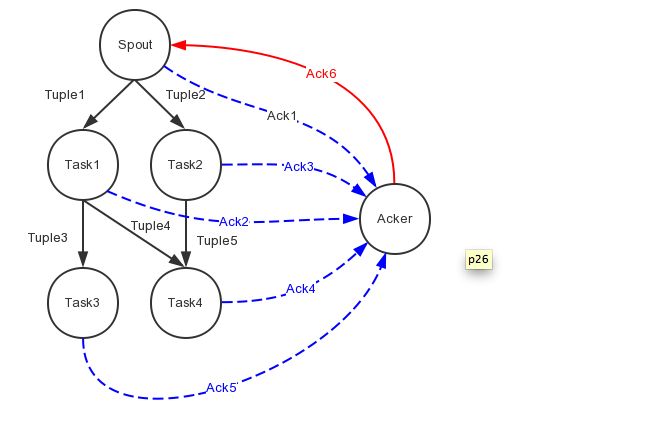
总体的流程介绍,首先Spout发完tuple后发送一条Ack消息给Acker线程,告诉Acker自己发送了哪些tuple需要ack,每一个Bolt 的 task 在执行完对tuple的处理之后,需要手动的ack一下,ack的时候发送一条Ack消息给Acker线程,告知自己要ack的tuple和需要下面的节点ack的tuple,当Acker收到所有的ack的时候就向Spout发送一条ack消息,通知这棵树上的tuple被完整的处理了。
每当一个Spout发送出一个tuple,就会在拓扑中产生了一棵由tuple构成的树,Jstorm中为每棵树设置了一个rootID来唯一的标示这棵树。
Storm如何存储数据
严格来讲,Storm中设计的组建,没有专门存储数据的,一般情况下,会借助第三方的存储,例如mysql、Nosql 等,Bolt的节点,可以用于存储计算的中间结果或者最终结果。
从这里看,Storm在取舍上拿捏的恰到好处,发挥里实时处理数据的核心场景。
Spout和Bolt为啥需要实现序列化
这两个核心的接口,都实现了序列化,在开发web类系统的时候,一般接口或者操作类,是没有必要实现序列化接口的,这里为啥需要呢。
深入理解一些Storm的机制,一个topology程序提交到集群,是先提交到Nimbus的,然后由其进行分发,分发是跨进程的,到了另外一个进程中,是需要反序列化出来这个处理类的。
Storm中的grouping机制有那些
一个 Bolt 可以设置为多个 Task 并发执行数据处理任务,订阅了一个 Spout 的 Stream,那么应该把 Spout 的数据发送给哪一个具体的Task执行,这个是由grouping的方式决定的。
1、随机分组,伪随机,按照一定的逻辑均匀的分发
2、特定字段分组
3、真正的随机分组
4、广播,每个都发一遍
5、直接制定那个任务接收

事务拓扑是怎么回事
事务拓扑,保证流入拓扑的数据能够被完整的处理且处理一次;
Acker拓扑,保证流入拓扑的数据能够被完整的处理,但不保证不重复;
普通拓扑,不保证流入拓扑的数据能够被完整的处理;
如何测试这种编程模型的系统呢
简单想了一些测试的思路,这种实时处理,数据是流动的,测试难度比较大
1、验证数据,截取特定时间点的分析结果数据快照,然后利用这些时间在离线的分析集群里面对照写分析逻辑,看结果是否一致;
2、验证数据分析处理逻辑,中间的Bolt阶段,涉及到数据的加工分析以及过滤,可以mock数据输入,验证计算逻辑是否准确;
3、测试环境下,模拟有可能异常的业务数据,流入系统,看系统的容错机制如何;
Spout如何获取数据
1、直接链接,Spout作为数据输入的源头,启动线程直接链接对应的数据源,拉取特定条件的数据;
2、通过队列过度,不是直接的方式,通过消息队列来进行过度;
3、外部系统通知,消息系统通知到Spout,然后转换为Tuple进行传输;
实时计算业务场景举例
1、日志分析
例如应用系统产生大量的业务日志,这些例如网关系统的API调用情况日志,这些日志,不太适合马上存入数据库,需要进行加工,日志文件的量又非常大,所以没法直接统计,这时候可以通过Storm来进行分析。
2、大数据实时统计
互联网的数据量是海量的时候,没有办法在数据库层面直接SQL来进行统计,需要对于产生的数据,进行二次加工,然后产出结果,正好把实时变化的数据流到storm中处理一遍。
3、管道传输
例如有数据需要从A系统流道B系统,这时候需要中间处理一下,场景是不是很切和。
参考文章:
http://storm.apache.org/documentation/Concepts.html
http://tech.uc.cn/?p=2159
http://xumingming.sinaapp.com/category/storm/
http://www.searchtb.com/2012/09/introduction-to-storm.html