master: 192.168.56.102
slave:[192.168.56.106, 192.168.56.107,192.168.56.108]
下载和配置环境变量
master节点
/etc/profile
export JAVA_HOME=/usr/local/java/jdk1.7.0_75 export PATH=$JAVA_HOME/bin/:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export HADOOP_HOME=/home/u2/hadoop-2.6.0 export PATH=$PATH:$HADOOP_HOME/bin export M2_HOME=/home/u2/apache-maven-3.3.1 export PATH=$M2_HOME/bin:$PATH export SCALA_HOME=/usr/local/scala/scala-2.11.6 export PATH=$SCALA_HOME/bin:$PATH export SPARK_HOME=/home/u2/spark-1.3.0-bin-hadoop2.4 export PATH=$SPARK_HOME/bin:$PATH
cd ~/hadoop-2.6.0/
etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/u2/hadoopdata/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.102:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>hadoop-cluster1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.56.102:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/u2/hadoopdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/u2/hadoopdata/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.56.102:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.56.102:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.56.102:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.56.102:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.56.102:8088</value>
</property>
</configuration>
etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>192.168.56.102:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.56.102:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.56.102:19888</value>
</property>
</configuration>
etc/hadoop/hadoop-env.sh 增加
export JAVA_HOME=/usr/local/java/jdk1.7.0_75
etc/hadoop/slaves
192.168.56.106 192.168.56.107 192.168.56.108
cd ~/spark-1.3.0-bin-hadoop2.4/
conf/spark-env.sh增加
export SCALA_HOME=/usr/local/scala/scala-2.11.6 export JAVA_HOME=/usr/local/java/jdk1.7.0_75 export SPARK_MASTER_IP=192.168.56.102 export SPARK_WORKER_MEMORY=1000m
conf/slaves
192.168.56.102 192.168.56.106 192.168.56.107 192.168.56.108
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
cd ~/
scp -r spark-1.3.0-bin-hadoop2.4 [email protected]:~/
scp -r hadoop-2.6.0 [email protected]:~/
scp -r spark-1.3.0-bin-hadoop2.4 [email protected]:~/
scp -r hadoop-2.6.0 [email protected]:~/
scp -r spark-1.3.0-bin-hadoop2.4 [email protected]:~/
scp -r hadoop-2.6.0 [email protected]:~/
3个slave环境变量配好。记得source /etc/profile
cd ~/hadoop-2.6.0/ ./sbin/start-all.sh cd ~/spark-1.3.0-bin-hadoop2.4/ ./sbin/start-all.sh
打开http://192.168.56.102:8088/cluster/nodes

打开http://192.168.56.102:8080/
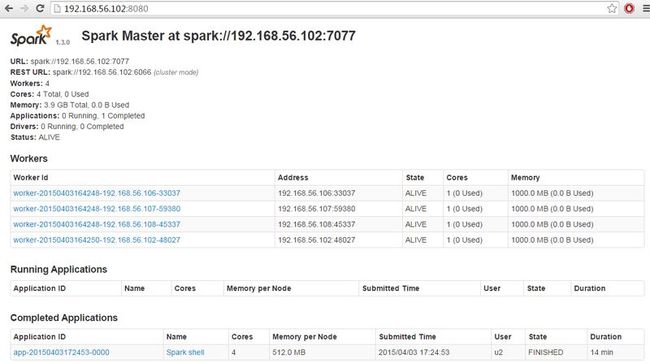
cd ~/hadoop
hdfs dfs -mkdir /input/json/
hdfs dfs -put friends_timeline.json /input/json/friends_timeline.json
cd ~/spark-1.3.0-bin-hadoop2.4
./bin/spark-shell
scala>import org.apache.spark.SparkContext._
scala>val sqlContext = new org.apache.spark.sql.SQLContext(sc)
scala>val table = sqlContext.jsonFile("hdfs://192.168.56.102:9000/input/json/friends_timeline")
scala>table.printSchema()