分布式文件系统名字空间实现研究
1、名字空间概述
名字空间(Namespace)即文件系统文件目录的组织方式,是文件系统的重要组成部分,为用户提供可视化的、可理解的文件系统视图,从而解决或降低人类与计算机之间在数据存储上的语义间隔。目前树状结构的文件系统组织方式与现实世界的组织结构最为相似,被人们所广泛接受。因此绝大多数的文件系统皆以Tree方式来组织文件目录,包括各种磁盘文件系统(EXTx, XFS, JFS, Reiserfs, ZFS, Btrfs, NTFS, FAT32等)、网络文件系统(NFS, AFS, CIFS/SMB等)、集群文件系统(Lustre, PNFS, PVFS, GPFS, PanFS等)、分布式文件系统(GoogleFS, HDFS, MFS, KFS, TaobaoFS, FastDFS等)。
随着面向对象存储和云存储的发展,出现了一种称为偏平化(Flat)的文件系统组织方式,典型代表有Lustre, PanFS, Amazon S3, Google Storage。这种方式把所有文件目录看作对象Object,每一个对象有一个全局唯一的标识UUID,户使用此UUID(而非路径)来访问存储系统。然而,UUID仅仅对计算机有意义,在用户接口层往往还是需要提供树状文件系统视图,再由系统在Path和UUID之间进行转换。在对象存储层,对象或对象数据分片以文件形式存储在磁盘文件系统之上,物理存储层仍然是树状存储结构。另外,对于法规遵从数据存储领域广泛使用的固定内容存储系统CAS(Content addressed storage, 内容寻址存储),采用基于对象的存储系统,机制与此类似。
具体实现上,磁盘文件系统的名字空间直接在磁盘上来实现,通常以B*/B+/B-树的形式来组织,元数据和数据存储在相同的介质上。而对于分布式文件系统来说,元数据和数据和存储和访问是分离的,这是由高性能、可用性、可扩展性等设计要求所决定的。通常,数据的存取由I/O服务器来实现,而元数据由元数据服务器来负责。名字空间是元数据服务器的核心任务之一,此外可能还要负责安全机制(如授权与认证)、锁机制、I/O负载均衡等。因此,由于元数据与数据的分离,分布式文件系统名字空间实现的自由度比较大,实现方式有更多的选择空间。这里将要介绍四种分布式文件系统名字空间实现机制,均为树状文件系统视图,大致分为基于文件系统的实现和基于全内存的实现,但不包括基于数据库的实现。基于数据库来实现文件系统名字间有众所周知的性能问题,尤其是递归遍历文件目录空间。
2、四种文件系统名字空间实现
(1)基于文件系统的设计
这是一种"站在巨人肩膀上"的设计。磁盘文件系统本身就是树状结构视图,因此可以利用这现成的机制在元数据服务器上实现名字空间。对于分布式文件系统中的每一个目录或文件,在元数据服务器的本地文件系统之上一一对应创建一个目录或文件(以下称为元目录和元文件),两者之间的映射关系如图1所示。元目录用来表示DFS中的目录,其元目录属性保存DFS目录属性;元文件用来表示DFS中的文件,元文件属性保存DFS文件属性,元文件内容则用来保存元数据,包括更详细的文件属性、访问控制信息、数据分片信息、数据存储位置等信息。
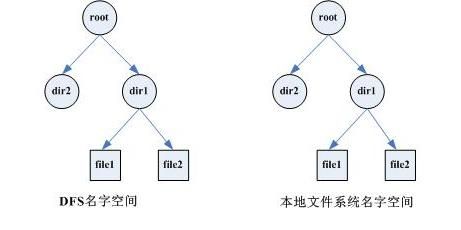
图1 基于文件系统的设计(DFS与本地文件系统名字映射)
基于文件系统我们以极小的代价构建了DFS的名字空间,实现起来简单快速。元文件仅用来存储数据文件的元数据,一般都是小于1KB的小文件,如果文件目录数量达到千万量级就会形成LOSF(Lots of small files)的性能问题。实际应用中如何来解决这种问题呢?目前主要有两种解决方法,一是采用适合海量小文件存储的文件系统。Reiserfs对小文件存储进行了特别优化,它不仅文件查找效率高,而且节省磁盘存储空间,实际测试结果也验证了这一点。二是采用高性能的存储介质,尤其是IOPS指标。非常幸运,固态硬盘SSD技术上已经比较成熟,成本不断降低,非常适合高性能的存储应用。SSD的特点是IOPS高,普通SSD读写IPOS可以达到10000 ~ 50000,高端SSD甚至可以达到100000以上,而FC、SAS、SATA磁盘的IPOS基本小于300,远远小于SSD。因此,采用SSD和Reiserfs文件系统,性能能够得到大幅提升,大多数应用问题不大。
(2)基于全内存的分层设计
这种方式与HDFS实现相仿。与基于文件系统的实现不同,名字空间完全在元数据服务器的内存中,使用层次结构来表示,如图2所示。这种层次结构相当于一棵树,每个结点表示DFS的一个目录或文件,结点的孩子结点理论上没有数量限制(取决于内存可用量),孩子结点使用动态数组来表示。结点数据结构如下所示,其中metadata表示(1)中文件目录类似的元数据信息,children是孩子结点动态数组,使用二分法实现插入、查找和删除操作,严格按照名称进行升序排序。
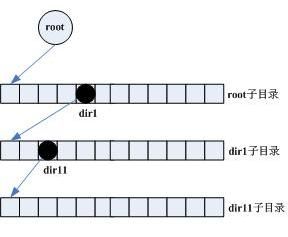
图2 基于全内存的分层设计
对于文件系统ls操作,首先对路径进行解析并拆分成独立的目录名,然后从root结点开始查找,孩子结点数组使用logN的二分搜索BinarySearch查找,直到找到对应的目录结点,然后遍历结点的孩子结点数组即可。假设目录深度为h,目录宽度为n,则查找目录文件的时间复杂度为O(h * log(n))。对于文件系统来说,这种查找时间复杂度显得有点高,尤其是目录层次很深、子目录文件数量庞大的分布式文件系统。HDFS的设计思想源自GFS,可是在名字空间设计上还是与GFS存在一定的差距,可谓形似而神不似。另外,全内存设计对内存需求比较高,假设每个目录文件的元数据大小为100字节,则1千万目录文件的元数据大小总量约等于1,000,000,000 = 1GB。如果需要支持更多的目录文件,则需要应增加内存量。
(3)基于全内存的Hash设计
这种方式与GFS实现相仿。GFS论文中指出其名字空间采用了全内存设计、偏平式组织、前缀压缩算法、二分查找算法、没有支持ls的数据结构,论文中还指出ls操作的效率较低。GFS没有开源,不像HDFS可以查阅原代码,因此也无法完全重现GFS的名字空间实现,基本全内存的Hash设计可能比较接近其设计。这种设计采用Hash和二分查找相结合的来实现,即目录以完整的绝对路径进行hash定位,该目录下的孩子结点使用二分查找进行定位,如图3所示。它与分层设计的主要不同在于,只需要一次hash和一次二分查找,而分层设计需要多次的二分查找,在性能上更优。我们仅对目录进行Hash,名字空间具有一定的偏平性,但没有达到GFS的完全偏平;子文件目录不包括父路径部分,相当于作了前缀压缩,但不如分层前缀压缩彻底。大胆猜测,GFS可能采用了全HASH设计或全列表设计,ls操作通过前缀匹配来实现,即具有相同前缀的文件属于同一个目录,如此实现名字空间。
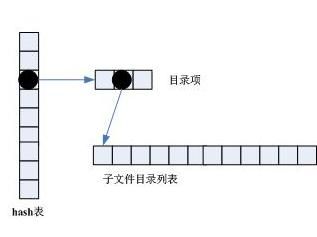
图3 基于内存的hash设计
这种设计下,查找指定文件或执行ls,首先将路径分解成父路径名和目录文件名,对父路径名进行hash运算定位至其孩子结点列表,然后二分查找指定文件,或者遍历孩子结点列表实现ls操作。假设目录宽度为n,查找时间复杂性为log(n),在内存占用量上要稍稍大于分层设计,因为目录结点均重复一次。这种设计具有支持ls的数据结构,相对于GFS来说,执行ls效率要高出许多,如果GFS是全Hash设计则需要遍历整个文件空间进行前缀匹配,如果GFS是全列表设计则需要以父路径名进行二分查找然后局部前缀匹配。
(4)基于全内存的双重Hash设计
这种方式是对基于全内存hash设计的改进。它先对目录进行第一次hash运算,然后对子文件目录进行第二次hash运算,从而将查找时间复杂性从log(n)进一步降低至O(2),如图4所示。目录Hash表是全局的,而目录结点的Hash表是局部的,每一个目录结点都包含一个Hash表,仅用来存储本目录下的子文件目录信息,目录结点数据结构如下所示。
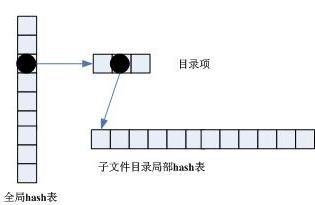
图4 基于内存的双重hash设计
对于文件系统ls操作,对路径名进行一次hash运算定位到目录结点,然后对目录结点中的hash表进行遍历即可。文件查找时,首先将路径名分解成父路径名和文件目录名,对父路径名进行hash运算定位父目录结点,然后对文件目录名进行hash运算并在父目录结点中的hash表进行定位。目录结点中的hash表初始为未创建,直到第一次创建子文件目录时方才创建,hash表项数量定义为平均目录包含的子文件目录数量,在性能和内存空间节省之间进行折中。如果内存充足,hash表项数量应该尽量设置大些,以达到更好的散列效果。与基于全内存的Hash设计相比,这种设计查找性能上更上层楼,内存消耗相应有所增加。
3、对比分析与应用选择
上述分布式文件系统名字空间的四种实现方式,按照实现位置划分,可分为基于文件系统的实现和基于内存的实现。基于文件系统实现的优点是实现简单,内存要求低,可以运行在普通的机器上,缺点是性能可能较低。如果采用SSD+Reiserfs实现,性能应该不是大问题,但成本也随之提高许多。基于内存实现的优点是性能高,缺点是对内存要求极高,实现起来比较复杂,并需要对内存的名字空间进行持久性保护措施防止意外宕机或出错。基于内存的三种实现,性能方面双重hash设计 > hash设计 > 分层设计,内存需求方面则相反。实际实现和应用中,应该结合成本预算和性能需求进行选择,选择的原则是,在满足设计要求的前提下尽量争取性价比最大化。