最近在学习数据库索引,所以在这里记录下最近的学习心得。
热身学习。
1.二叉平衡树和B树B+树的概念需要了解。
2.了解二叉平衡树的旋转。
3.思考为何数据库索引不使用二叉平衡树而选择B树或者B+树。
4.思考B+树作为索引相对于B树的优点在哪里。
具体可以参考:
知识总结
1.聚集索引
叶子节点包含聚集键值和全部数据。
表中的数据顺序通过聚集键的顺序来维护,聚集索引树本身就包含了一个表。
单独的外链双链表来进行页之间的维护。也就是说在每页中是有序的,每个页也是有序的。
思考,那如果页的最后一条数据添加或者删除会有哪些情况?
思考,聚集键值唯一性,宽度,易变性因素对整个索引产生的影响。
唯一性在下面的问题中探讨。
宽度的影响首先影响本身B树的每个节点的度,其次辅助索叶子节点引用键值的成本增加。
易变性使其记录需要重新定位,容易产生页面分离和碎片。其次每个辅助索引需要修改。
思考,通过聚集键找到叶子节点的时候,将叶子节点的页面加载进来的时候是通过二分查找吗?
2.非聚集索引
叶子节点存储的是索引键值和【聚集键或者sqlserver生成物理标示符RID】
思考RID是sqlserver自动生成的,还是真实物理地址。?
真实的物理行号。
思考,为何聚集键值必须唯一。
假设聚集键值不唯一,聚集键为姓名,非聚集键值为身份证号,如果一个非聚集索引是唯一的如身 份证号,定位到一个姓名A如果存在多个人姓名为A则更新的是跟新多个人的姓名是不合理的,因为 身份证号是唯一的。
如果聚集键不一定则sqlserver会在必要时添加一个隐藏的唯一标识列来保证内部的唯一性。
思考索引和约束有哪些区别?
索引会建立真实的物理结构需要维护,而索引则是逻辑上的意义。
3.索引结构
对于聚簇索引表的聚簇索引结构如下。
-- 创建聚簇索引表
create table employee(
id int not null identity,
lastname Nchar(30) not null,
firstname nchar(29) not null,
middleinit nchar(1) null,
ssn char(11) not null,
othercolumns char(258) not null default 'jack');
alter table employee add constraint employeePK primary key clustered (id)
select * from employee
-- 80000条
insert into employee(lastname,firstname,middleinit,ssn,othercolumns) values('','','','','')
-- 查询索引结构
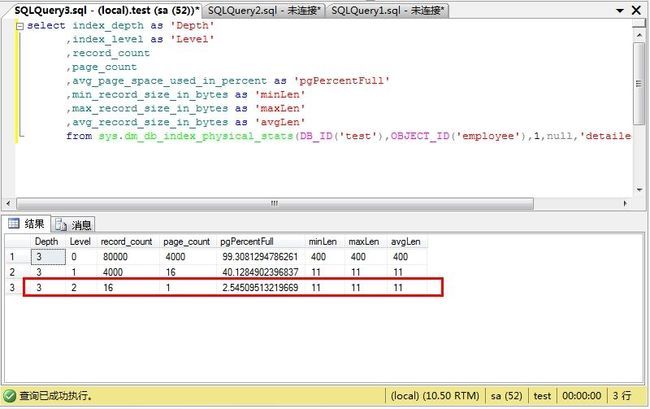
select index_depth as 'Depth'
,index_level as 'Level'
,record_count
,page_count
,avg_page_space_used_in_percent as 'pgPercentFull'
,min_record_size_in_bytes as 'minLen'
,max_record_size_in_bytes as 'maxLen'
,avg_record_size_in_bytes as 'avgLen'
from sys.dm_db_index_physical_stats(DB_ID('test'),OBJECT_ID('employee'),1,null,'detailed')
dbcc page ( {'dbname' | dbid}, filenum, pagenum [, printopt={0|1|2|3} ])
The filenum and pagenum parameters are taken from the page IDs that come from various system tables and appear in DBCC or other system error messages. A page ID of, say, (1:354) has filenum = 1 and pagenum = 354.
The printopt parameter has the following meanings:
0 - print just the page header
1 - page header plus per-row hex dumps and a dump of the page slot array (unless its a page that doesn't have one, like allocation bitmaps)
2 - page header plus whole page hex dump
3 - page header plus detailed per-row interpretation
database consistenecy checker,简称dbcc
Trace flag 3604 is to print the output in query window.
Since you have not given -1 parameter (DBCC TRACEON(6304,-1)),
it would be session specific. Once you close the window, it would be cleared.
-- 寻找12345的记录。
--创建临时表
create table temp_table(
PageFID tinyint,
pagePID int ,
IAMFID tinyint,
IAMPID int,
objectID int,
indexID tinyint,
partitionNumber tinyint,
partitionID bigint,
iam_chain_type varchar(30),
pagetype tinyint,
indexLevel tinyint,
nextpageFID tinyint,
nextpagePID int,
prePageFID tinyint,
prepagePID int,
primary key(PageFID,PagepID)
)
--寻找索引id
select * from sys.sysindexes where name='employeePK'
--查询dbcc ind结果集
--此处需要索引ID
truncate table temp_table
insert temp_table
exec ('dbcc ind (test,employee,1)')
-- 找到根页
select indexLevel,
PageFID,
pagePID,
prePageFID,
prepagePID,
nextpageFID,
nextpagePID
from temp_table
order by indexLevel desc,prepagePID
--查询根页的记录开始B树搜索
--LEVEL 2
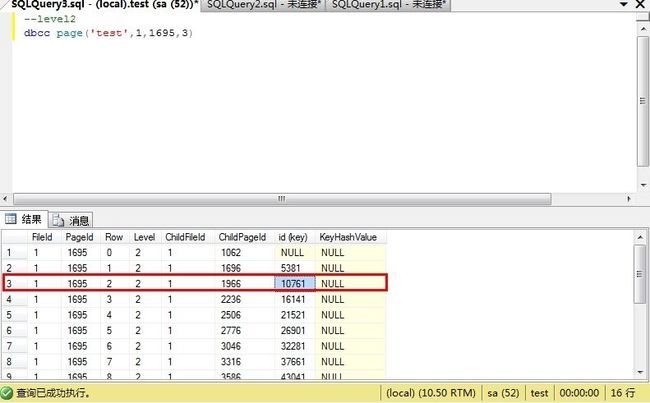
dbcc page('test',1,1695,3)
--LEVEL 1
dbcc page('test',1,1966,3)
--LEVEL 0
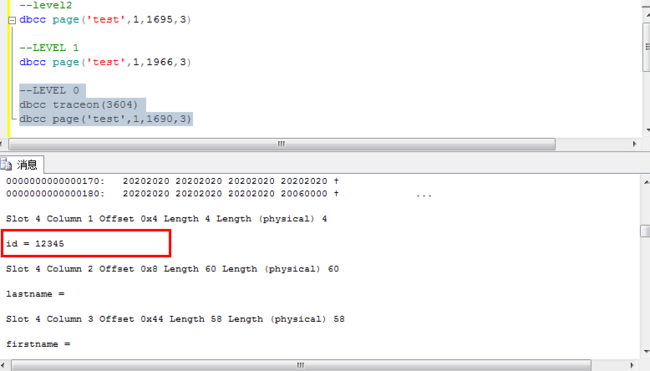
dbcc traceon(3604)
dbcc page('test',1,1690,3)
根据索引名称获取索引ID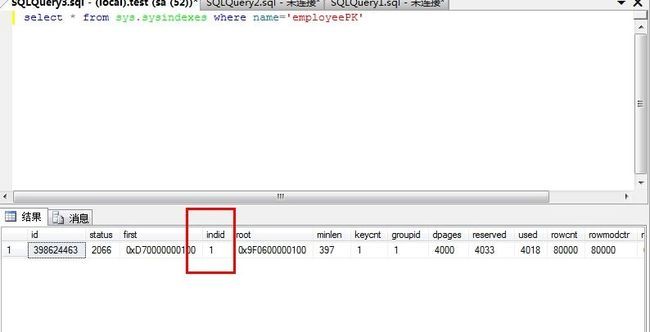
根据索引ID找到级别2的Root页号 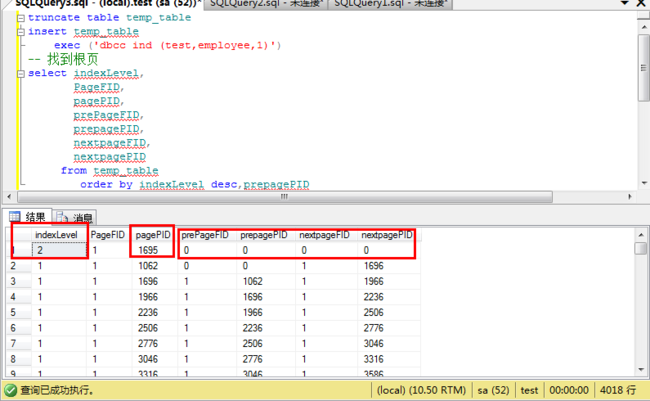
查询级别2的页内容,定位级别1的页号。
根据级别1的页号,查询级别1的内容,定位叶子节点的页号。 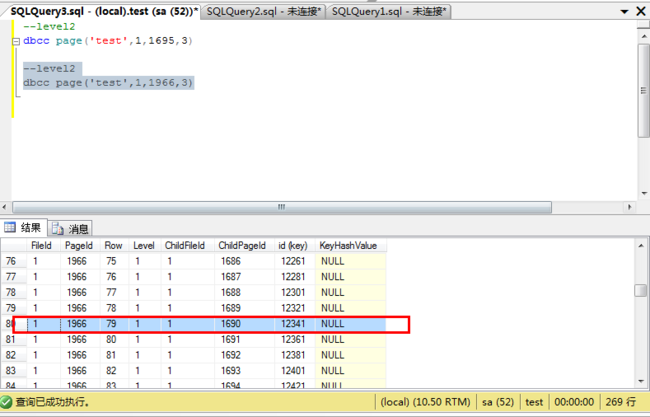
根据叶子节点的页号,查询叶子节点的内容。
聚簇索引表的非聚簇索引结构。
-- 修改原来的聚簇索引表结构
update employee set ssn = CAST(id as char(8))+'ssn'
--添加UK索引
alter table employee add constraint employeeSSNUK unique nonclustered (ssn)
--还是查找12345
-- 查询索引结构
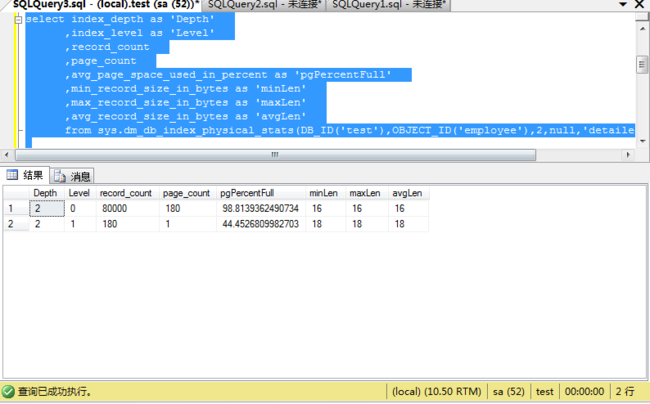
select index_depth as 'Depth'
,index_level as 'Level'
,record_count
,page_count
,avg_page_space_used_in_percent as 'pgPercentFull'
,min_record_size_in_bytes as 'minLen'
,max_record_size_in_bytes as 'maxLen'
,avg_record_size_in_bytes as 'avgLen'
from sys.dm_db_index_physical_stats(DB_ID('test'),OBJECT_ID('employee'),2,null,'detailed')
--寻找索引ID 2
select * from sys.sysindexes where name='employeeSSNUK'
-- 查询结果集
truncate table temp_table
insert temp_table
exec ('dbcc ind (test,employee,2)')
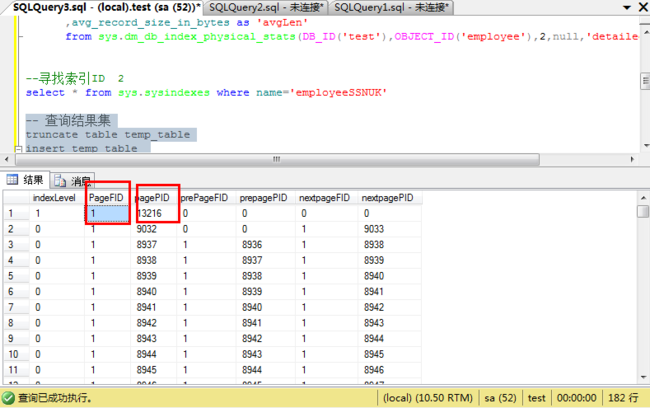
-- 找到根页fID,pageID
select indexLevel,
PageFID,
pagePID,
prePageFID,
prepagePID,
nextpageFID,
nextpagePID
from temp_table
order by indexLevel desc,prepagePID
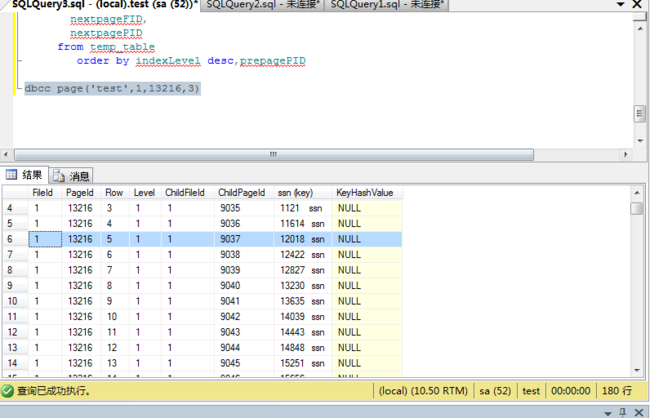
--查询根页内容找到叶子节点的页号
dbcc page('test',1,13216,3)
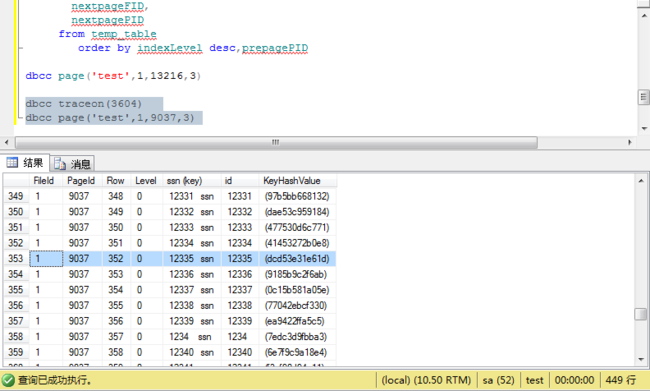
--查询叶子节点的内容 存储的是聚集键
dbcc traceon(3604)
dbcc page('test',1,9037,3)
查询索引结构
查询索引ID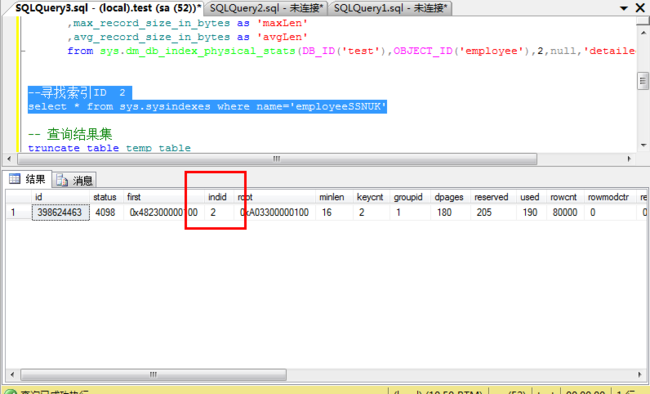
寻找根页号需要fID和pageID
查询根页内容,根据范围寻找叶子节点的页号。
查询叶子节点的内容。
关于堆表索引结构
--创建堆表
create table employeeHeap(
id int not null identity,
lastname Nchar(30) not null,
firstname nchar(29) not null,
middleinit nchar(1) null,
ssn char(11) not null,
othercolumns char(258) not null default 'jack');
alter table employeeHeap add constraint employeeHeapPK primary key nonclustered (id)
--查询索引ID
select * from sys.sysindexes where name='employeeHeapPK'
-- 查询索引的结构
select index_depth as 'Depth'
,index_level as 'Level'
,record_count
,page_count
,avg_page_space_used_in_percent as 'pgPercentFull'
,min_record_size_in_bytes as 'minLen'
,max_record_size_in_bytes as 'maxLen'
,avg_record_size_in_bytes as 'avgLen'
from sys.dm_db_index_physical_stats(DB_ID('test'),OBJECT_ID('employeeHeap'),3,null,'detailed')
truncate table temp_table
insert temp_table
exec ('dbcc ind (test,employeeHeap,3)')
-- 查找12345 步骤
-- 找到根页
select indexLevel,
PageFID,
pagePID,
prePageFID,
prepagePID,
nextpageFID,
nextpagePID
from temp_table
order by indexLevel desc,prepagePID
--level 1 7888
dbcc page('test',1,7888,3)
--查看叶节点的内容
dbcc page('test',1,7830,3)
-- 创建解析函数
create function convert_rids (@rid binary(8))
returns varchar(30)
as
begin
return (
convert (varchar(5),
convert(int,substring(@rid,6,1)
+substring(@rid,5,1)))
+':'+
convert(varchar(10),convert(int,substring(@rid,4,1) +substring(@rid,3,1)+substring(@rid,2,1)+substring(@rid,1,1)))
+':'+
convert(varchar(5),convert(int,substring(@rid,8,1)+substring(@rid,7,1)))
)
end
--fileID,pageID,slotNum 解析rid
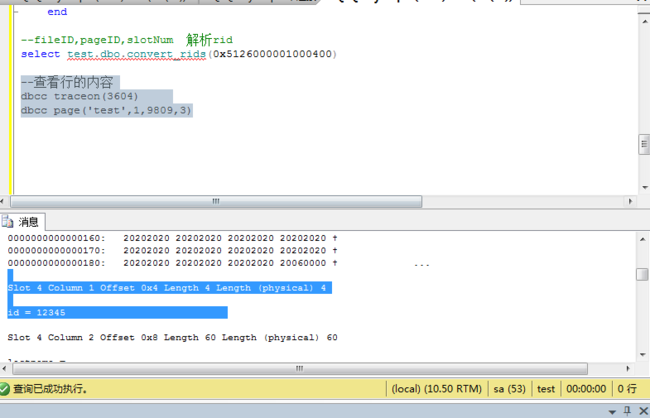
select test.dbo.convert_rids(0x5126000001000400)
--查看行的内容
dbcc traceon(3604)
dbcc page('test',1,9809,3)
查询索引ID
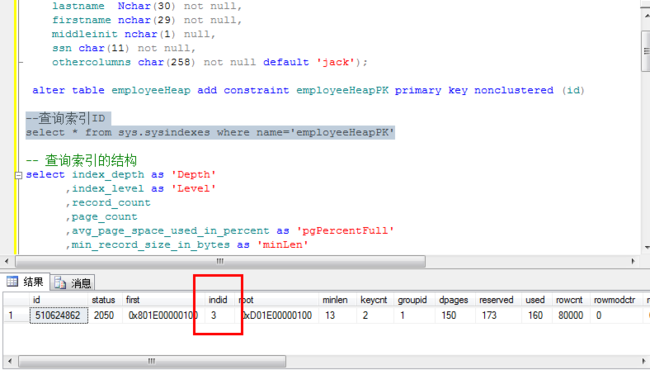
根据索引ID查看索引结构
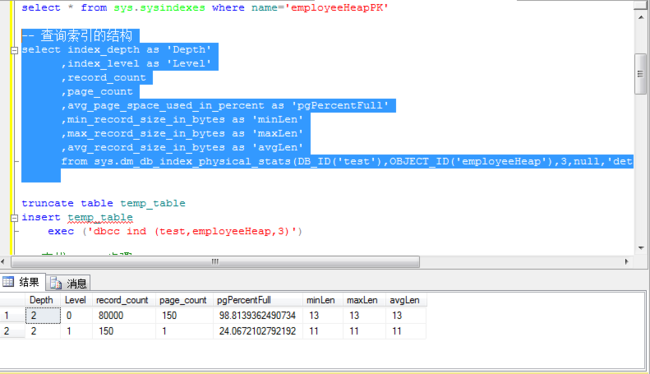
根据索引ID获取根页号

查看根页的内容获取子节点的fID和pageID
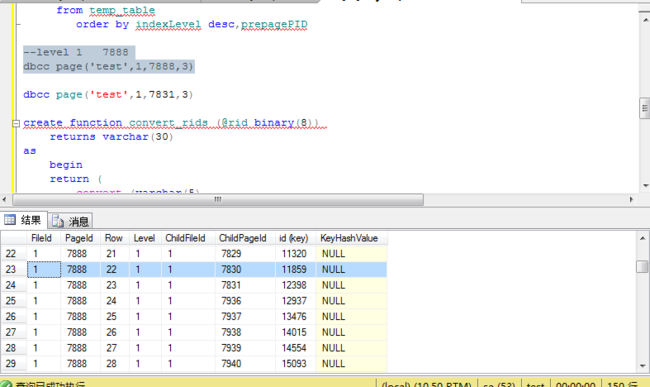
根据根页提供的pageID查看叶子节点的内容
叶子节点存储的是物理行号,
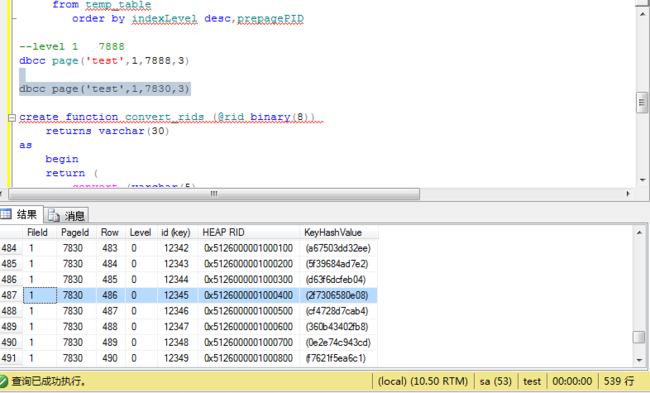
解析行号。
查看行数据。