简单入门正则表达式 - 第九章 “四项处理”—断言的用法

一、“四向处理”
前一章介绍过行界与词界,它们都是零长度断言,所谓零长度 就是因为它们不和任何字符相匹配,只是与某个位置进行匹配。在有些时候,我们可能想按照指定的条件来精确地确定要匹配的位置,而不仅仅是行界和词界,这就需要提供更多的匹配信息,所以,正则表达式提供了一种叫做“四项处理(lookaround)”功能。
“四项处理”的作用是与字符相匹配,然后根据是否能找到要匹配的字符,从而确定下来是否有符合要匹配样式的位置,在这个过程中,“四项处理”的匹配操作并不会占用目标字符串,它只是纯粹用于位置判断。下面是“四项处理” 的四种语法,分别是前向肯定断言、前向否定断言、 后向肯定断言和后向否定断言:
| (?=pattern) | 前向肯定断言 |
| (?!pattern) | 前向否定断言 |
| (?<=pattern) | 后向肯定断言 |
| (?<!pattern) | 后向否定断言 |
二、前向断言(Lookahead Assertion)和后向断言(Lookbehind Assertion)
前向断言从目标字符串的当前位置向前测试断言条件是否成立;相似的,后向断言从目标字符串的当前位置向后测试断言条件是否成立。
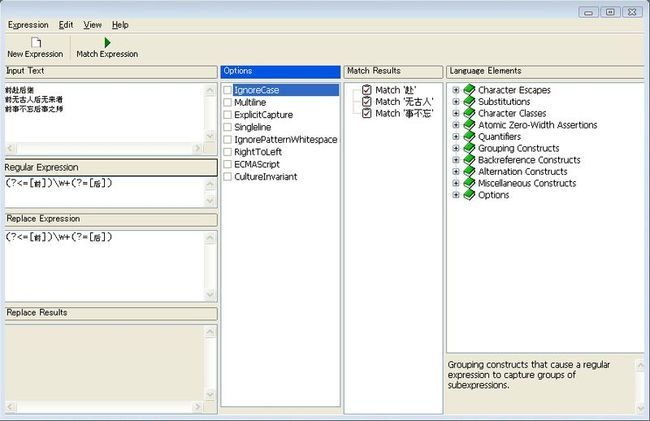
比如说我们要从成语“前赴后继”、“前无古人后无来者”和“前事不忘后事之师”中,找到以“前”字开头,“后”字结尾的字符串。要想匹配以“前”字开头,就要使用后向断言,因为它是从“前无古人后无来者”的“无古人”的“无”字向后进行匹配,所以我们使用后向断言(?<=[前])来匹配“前”字的,这样构造的正则表达式就是(?<=[前])/w+;接下来构造前向断言(?=[后])来匹配“后”字,这样就能确定以“后”字结尾的内容了,最终构造出来的正则表达式就是(?<=[前])/w+(?=[后]),匹配的结果字符串为“前无古人后无来者”等。下面是在工具“Rad Software Regular Expression Designer”中的运行结果。
三、肯定断言(Positive Assertion)和否定断言(Negative Assertion)
在正则表达式(?<=[前])/w+(?=[后])中所用到的都是肯定断言,而与其对应的,还有否定断言。否定断言就是从目标字符串的当前位置开始,向前或向后,对断言条件进行判断,看是否“不”成立。
比如我们要从句子“Pigtail does not mean a piggy's tail!”中找到单词“tail”(尾巴),但单词“pigtail”不能作为匹配的对象。现在分析一下如何构造正则表达式,首先,单词“tail”的前边不能是字母,这样就会容易匹配到合成词,如“pigtail”。所以,我们先构造前向断言(?<=/w),然后补上单词“tail”,结果就是(?<=/w)tail。
但我们相匹配的内容是非字母的,所有要把肯定的前向断言改成否定的前向断言(?<!/w)tail。这样匹配的结果就出来了,“Pigtail does not mean a piggy's tail!”。这里只是为了演示否定断言的用法,所以生硬的采用了否定前向断言,其实/btail/b完全可以满足需求。
与否定的前向断言类似,可以用否定的后向断言判断目标字符串的后面是否不存在指定的内容。我们可以构造正则表达式/b[pP]ig(?!t)/w+/b来匹配单词“piggy”。/b是词界,用来告诉引擎要匹配的内容是一个单词;[pP]ig用来与字符串“Pig”或“pig”;否定后向断言(?!t)指明“Pig”或“pig”的后面不能是字母“t”;/w+用来匹配“Pig”或“pig”后面的字符串,直到找到词界/b为止。最终匹配的结果是“Pigtail does not mean a piggy's tail!”。
四、关于断言中的回溯
一般地,前向断言和后向断言中不允许使用正则表达式,原因是正则引擎不会对断言的内容进行回溯操作。即使像 Perl 和 Python 这样的语言,或是我们使用的引擎类似于 Perl 中的正则引擎,断言中允许使用的内容也只能是事先就能够确定长度的字符串,如字面常量和字符集等。还有一点非常重要,就是断言语法所使用的圆括号并不作为捕获组,所有不能使用编号或命名来对它进行引用。
比方说我们要对一个两边内容相同的字符串“ABC12ABC”进行匹配,一般使用(/w+)/w*/1就可以了。现在我们使用后向断言来进行改写(?<=(/w+))/w*/1,这次可能什么都没有匹配到,这是因为在有些正则引擎中不能对“+”、“*”这样的长度无法确定的正则表达式进行处理,但如果改换成(?<=(/w{3}))/w*/1就能成功匹配“ABC12ABC”;如果改换成(?<=(/w{2}))/w*/1,匹配的结果就是“ABC12AB”。
为了加深理解,我们再看一个为数字添加逗号的例子。比如一个很长很长的数字,为了便于理解,一般情况都是从它的个位开始,每隔三位添加一个数字。现在我们就以字符串“123456789”为例,看看如何进行处理。假如按照以往的做法,可能是先用(/d{3}),在匹配到的捕获组的内容后面添加一个逗号,然后得到的处理结果是“123,456,789,”。这个结果并不能令我们满意,虽然用 substring 这样的方法很容易截掉最后一个字符,但能不能直接得到结果“123,456,789”呢?答案是肯定的!修改正则表达式为(/d{3})(?=/d),前面的(/d{3})保持不变,在后面添加一个前向断言,保证匹配到的内容不是百位、十位和个位。下面是 C# 对应的实现代码:
- namespace KNIGHTRCOM
- {
- public partial class MainApp : Form
- {
- public MainApp()
- {
- InitializeComponent();
- }
-
- private void MainApp_Load(object sender, EventArgs e)
- {
- String source = "123456789";
- String pattern = @"(/d{3})(?=/d)";
- String replacement = "$1,";
- String result = System.Text.RegularExpressions.Regex.Replace(source, pattern, replacement);
- MessageBox.Show(result);
- }
- }
- }
刚才的例子情况比较特殊,恰好是 3 的整数倍,而实际的情况往往很复杂,这次换成字符串“1234567890”结果又会怎样呢?同样的代码,答案却是“123,456,789,0”,并不是我们想要的“1,234,567,890”。这是因为正则表达式的处理总是按照从左向右的顺序,要是能反向顺序来处理就好了,但这并不可能,所以还是换个思路比较好。既然正则引擎不能帮反向处理,我们就自己来想办法,上面的例子用的是前向断言,我们就从后向断言入手,尝试一种新的解决方案。正则表达式(?<=/d{3})(/d{3})可以匹配所有的前面是连续的三个数字的三位数字,但这样对“1234567890”处理后的结果仍旧是“123,456,789,0”。
现在新的问题又来了,要是能事先把“1234567890”分成两个部分,前一个由 0 至 3 个数字组成,后面的由 3 的整数倍个数字组成,如“1,234567890”,然后再利用正则表达式(?<=/d{3})(/d{3})就能很轻松地得到正确的结果。其实这个问题并不难解决,再构造一个新的正则表达式(/d{1,3})((/d{3})+)把“1234567890”替换成$1,$2,“$1”代表第一个捕获组,“$2”代表第二个捕获组。这里对第一个捕获组说明一下,为什么要使用(/d{1,3})而不是(/d{0,3})。假设采用了(/d{0,3}),替换后的结果就会把字符串“123456789”变成“,123456789”,所以我们要把 0 的情况排除。下面是 Java 的实现代码:
- package blog.csdn.com.knightrcom;
-
- public class Test extends BaseException {
-
- public static void main(String[] args) {
- String sample = "1234567890";
- sample = sample.replaceAll("^(//d{1,3})((//d{3})+)$", "$1,$2");
- System.out.println(sample.replaceAll("(?<=//d{3})(//d{3})", ",$1")); // 1,234,567,890
- sample = "123456789";
- sample = sample.replaceAll("^(//d{1,3})((//d{3})+)$", "$1,$2");
- System.out.println(sample.replaceAll("(?<=//d{3})(//d{3})", ",$1")); // 123,456,789
- }
- }
<!-- InstanceEndEditable -->