从虚拟机视角谈Java应用性能优化
Java 平台已无处不在,Java EE、Java SE、Java ME 和 Java Card,Java 的发展为无数程序员提供了工作机会,都是“Java”,然而除了基本的 Java 语法大都一致外,程序员必须基于不同的平台有不同的考虑,学习不同平台的特点:
- 不同平台的环境
Java EE 所运行的硬件服务器、操作系统,Java SE 所在 PC 机的体系结构(X86/X64、MAC、SPARC 等),Java ME 所运行的手机或移动设备,Java Card 所在的智能卡芯片类型等;
- 不同平台虚拟机的特点
如 是否支持多线程(这似乎是毋庸置疑,但是在 Java Card 平台上,由于计算资源相当有限,多线程目前还不被支持),Java EE 和 Java SE 的虚拟机特性几乎相同,而 Java ME 虚拟机(KVM)根据移动设备的特点进行裁剪和优化,以适应于有限的物理内存和存储空间,而根据设备处理能力的强弱还分为 CDC(Connected Device Configuration,联网设备配置)和 CLDC(Connected Limited Device Configuration,联网受限设备配置),更小设备和智能卡的虚拟机 JCVM(Java Card VM)更是裁剪了许多特性,如多线程、许多复杂数据类型的支持、主动的垃圾收集机制等,这甚至导致了对 Java 语法集的裁剪;
- 不同平台的 API 和可用的第三方库
Java EE 和 Java SE 是超集与子集的关系,因为她们所处的计算机平台和操作系统目前很好的兼容,而 Java ME 和 Java Card 与 EE 和 SE 是 Totally different,除了 java.lang.*,部分 java.io.* 等核心类库保留外,其他的 API 和类库完全不同。java.microedition.* 和 javax.microedition.* 表明这是 ME 平台,javacard.* 表明这是 Java Card 平台。同时,由于 EE 和 SE 平台的普及程度和开发者人数,使得之上的第三方库十分海量。深入了解和掌握平台的 API 和库是不同平台程序员进阶的必由之路。
从这个角度上说,Java 在不同的平台之间,并不是“一次编写、处处运行”,考虑应用程序的设计和优化的时候,首先要看是在什么平台上,因为源于以上不同的特点,编程模型、设计模式,甚至语言集都不尽相同。在这里我们着重考虑 Java EE 和 SE 的视角,但有很多设计、编程原则和习惯对于所有平台的程序员来说,都适用。
Java 虚拟机是支持 Java 语言运行的基础,避开过多的 JVM 和实现的技术细节,我们对基础架构进行了解,是进行应用程序优化必不可少的。如下图所示:

- 类装载子系统 :通过类的全限定名(包名和类名,网络装载还包括 URL)将 Class 装载进运行时数据区;
- 方法区 :Class 对于所有方法和 static 静态数据的定义存储在这里,它就像一张表或数组,让程序执行时在这里找到相应方法的 Java 字节码和静态数据;
- Java 堆 :Java 对象的持久化存储区,从类实例化而来的对象存储在此,垃圾收集也在此进行,若是空间不够容纳当前所有对象,Out Of Memory 的异常将会抛出,对 Java 堆和垃圾收集的认识对应用性能调优很关键;
- Java 栈 :Java 方法的字节码执行的地方,方法中局部变量的生命周期都在栈中,栈的大小是我们要考虑的一个关键点,它直接决定了方法调用的层数,这对递归程序来说尤为重 要。我们所用的 JVM 都是基于 Java 栈的运行机制,而有一个例外的实现,Google 移动设备操作系统 Android 的虚拟机 Dalvik 则是基于寄存器的机制(Dalvik 虽然支持 Java 语言开发,但从虚拟机的角度看,并不符合 Java 标准)。
- 程序计数器 :对于基于栈实现的 JVM,这几乎是唯一寄存器了,它用来指示当前 Java 执行引擎执行到哪条 Java 字节码,指针指向方法区的字节码;
- 本地方法栈 :这是 Java 调用操作系统本地库的地方,用来实现 JNI(Java Native Interface,Java 本地接口);
- 执行引擎 :JVM 的心脏,控制装入 Java 字节码并解析;
- 本地接口 :连接了本地方法栈和操作系统库。
Java 字节码是 JVM 的指令,所有 Java 平台虚拟机有各自的指令集,而大部分指令相同,共 200 条左右,Java Card 虚拟机由于支持的数据类型少,相应的指令较少。部分虚拟机实现商为了优化性能,增加了一些自己特有的指令,当对于 Java 程序员来说,是透明的。下面是一段 Java 方法的字节码示例:
|
当程序计数器中值为 0x000092ca:0x04ad ,表明下一条即将执行字节码为 _INVOKESTATIC, HIGH(0x8046), LOW(0x8046) ,该字节码表明将调用某个静态方法。
Java 语言一大好处就是不用关心对于内存的分配和回收,一切由垃圾收集器搞定。然而这并不代表 Java 程序员可以高枕无忧,再高效的收集器也可能因为滥用而导致性能问题。我们已经知道,Java 程序所涉及的空间分配和回收包括:
- Java 堆,创建的 Java 对象(包括数组,数组也是一种对象)分配在堆中,垃圾收集对象来释放空间;
- Java 栈,栈划分为操作数栈、栈帧数据和局部变量区,方法中分配的局部变量在栈中,同时每一次方法的调用都会在栈中分配栈帧,因此程序员在设计和开发应用时需考虑调用层数。
来看一段字节码在 Java 栈中的执行示例,100 与 98 相加:
|

此外,对于 JVM,还需了解支持的数据类型和它们占用的空间:
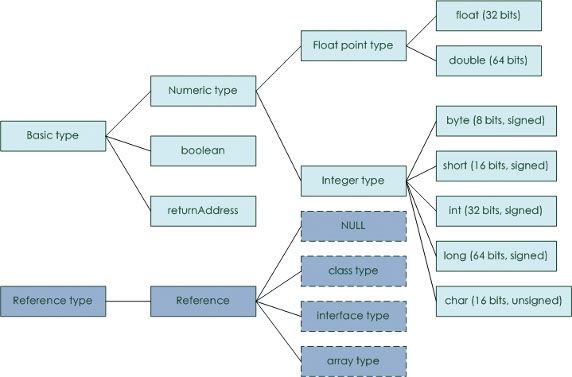
虽然各家 JVM 的实现(Sun Hotspot、IBM J9、Oracle JRockit 等)不同,但均采用了按代的垃圾收集机制。垃圾收集就是标识出虚拟机中不被用到的垃圾对象,删除以回收空间。按代垃圾收集算法主要分为三种:
- 复制算法,空间被分为等大的两块,从根开始访问每一个关联的活跃对象,将空间 A 的活跃对象全部复制到空间 B,然后一次性回收整个空间 A,优点:只访问活跃对象,将所有活动对象复制走之后就清空整个空间,不用去访问死对象,所以遍历空间的成本较小,缺点:需要巨大的复制成本和较多的内 存;
- 标记清除算法,从根开始访问所有活跃对象,标记为活跃对象。然后再遍历一次整个内存区域,把所有没有标记活跃的对象进行回收处理,优点:不需要额外的空间,缺点:较长的 GC 暂停时间,较大的扫描时间开销,产生较多的空间碎片;
- 标记清除整理算法,综合上两种算法的优点,先标记活跃对象,然后将其合并成较大的内存块。
代的划分:
- 年轻代:新创建的对象分配在此,研究表明,大部分程序所产生的对象都在此消亡,几乎所有的收集器为年轻代使用复制算法,年轻代又被划分为 1 个伊甸园区和 2 个存活区用来实施复制算法;
- 年老代:从年轻代存活下来的对象被复制到年老代,主要实施标记清除或标记清除整理算法;
- 持久代:装载的类数据和信息存储于此,无可消亡对象。
Java 虚拟机都提供了相应的选项来设置各个代所占用区的大小,无论是 Java EE 的服务器应用,还是 Java SE 桌面应用或产品,都需要经过对运行时对象创建和消亡状态的分析,进行这些选项的合理设置,才能获得较好的性能提升,毕竟垃圾收集是一项耗时的工作。读者可 以进一步深入研究相关的虚拟机选项,为自己的应用程序设置优化的数值。
垃圾收集按频率可分为:
- 次收集(Minor Collection):频繁发生在年轻代,收集快速消亡的对象;
- 主收集(Major Collection):年轻代和年老代的全范围收集,频率很低。
垃圾收集运行时,同一个 CPU 上的所有其它线程都将会被阻塞,所以对于 Java 应用程序来说,整个世界似乎停滞了,当整个标记、清除、整理周期完成后,所有应用程序线程得以继续,许多 JVM 实现的垃圾收集机制对多 CPU 的机器环境进行优化,通过同步来实现垃圾收集线程和应用程序线程的并发,使程序获得很好的总体性能。
通过设置虚拟机参数来配置垃圾收集器的行为和堆中不同区的大小分配。不同虚拟机的实现,参数选项不尽相同。IBM J9 虚拟机在 IBM 的从移动设备到企业解决方案中广泛的被使用,本文关于虚拟机选项参数的设定均基于 IBM 的 J9。
了解了垃圾收集以及它对性能的影响后,我们可以根据应用程序的特点来设置 GC 的策略进行有效的优化。相关参数是 -Xgcpolicy:[optthruput | optavgpause | gencon | subpool]
- -Xgcpolicy:optthruput ,针对吞吐量优化,这是虚拟机默认的 GC 策略,适用于两种极端情况:应用需要尽可能快的在短时间内运行结束,或应用长时间运行,且运行过程中的吞吐量没有比较固定的大小和分布;
- -Xgcpolicy:optavgpause ,针对 GC 导致的停顿优化,通过并发地执行一部分垃圾收集,在高吞吐量和短 GC 停顿之间进行折中。应用程序停顿的时间更短。适用于应用具有比较规则和突发的吞吐量周期分布;
- -Xgcpolicy:gencon ,分代并发进行 GC,以不同方式处理短期存活的对象和长期存活的对象。采用这种策略时,具有许多短期存活对象的应用程序会表现出更短的停顿时间,同时仍然产生很好的吞吐量;
- -Xgcpolicy:subpool ,子池优化,采用与默认策略相似的算法,但是采用一种比较适合多处理器计算机的分配策略。适用于在多核环境下运行的具有较高对象创建速率的多线程应用。
除了设置 GC 策略,最常设置的堆大小参数有:-Xms ,设置堆的初始大小;-Xmx ,设置堆空间的最大值;-Xmn ,设置年轻代空间大小;-Xmo ,设置年老代空间大小。程序员需要根据实际的机器环境和应用本身的特点来设置合理的值。
对虚拟机工作机制的了解能够使我们有把握写出更优雅、更高效的 Java 代码。下面是几条值得参考的设计、编程原则和习惯。
- 及时更新虚拟机。
除 了由于某些产品兼容性的需要必须使用过去某个虚拟机版本外,建议将开发环境和最终产品部署的虚拟机运行时环境要求更新至最新版本。最新的版本意味着最新的 API,更好的实现优化。这一点对嵌入式 Java(Java ME 和 Java Card)并不适用,随着移动或智能设备的发行,虚拟机就已经固化在其中,而新发布的虚拟机版本不能像在 EE 和 SE 安装的服务器和 PC 机一样,轻松进行安装。部分移动设备可以通过更新固件和操作系统程序来实现 VM 的版本更新。
- 良好的面向对象设计和架构,应用设计模式。
这 点对于 Java 应用的性能、重用和可维护性尤为重要,设计模式是由大师们总结出的解决典型问题的通用架构,用对象来描述问题域,用设计模式来组织对象之间的行为。在设计 和解决局部问题时,首先要看看抽象出来的问题是否和某个设计模式的目标问题一致。此外,尽可能多的了解虚拟机所支持的 API,看所需的功能是否已有现成的实现可供调用,虚拟机平台实现的 API 大都具有良好的性能。
- 关心 Java 栈。
前 面了解到,对于基于栈的 Java 虚拟机,方法的调用和执行伴随着压栈和出栈操作。每个线程有各自独立的栈,由虚拟机来管理栈的大小,但我们应该对它的大小有个概念。栈的大小是把双刃剑, 如果太小,可能会导致栈溢出,特别是在该线程内有递归、大的循环时出现溢出的可能性更大,如果过大,就会影响到可创建栈的数量,如果是多线程的应用,就会 导致内存溢出。通过 -Xss 可以设置 Java 栈的最大值,默认值为 256K 。不建议设置该选项为其他值,好的方案是,通过优化程序来减少递归层数、避免过大的循环、减少方法的调用层次,让你的程序尽量“扁平”,用尽可能好的对象间的关系来取代少数对象间深层次的方法调用。
- 加强对象管理,不放任自流。
过 分依赖垃圾收集有时候会出现严重的性能问题,特别对于在程序运行中伴随着大量大对象创建的情况。好的习惯是显式的释放不用对象的引用,在下一垃圾收集周期 中被回收,这一点常常被 Java 程序员忽视,遗留的引用会导致 GC 无法回收这些逻辑上消亡的对象,看下面代码示例:
清单 3. Java 实现的栈
public class Stack {
private static final int MAXLEN = 10;
private Object stk[] = new Object[MAXLEN];
private int stkp = -1;
public void push(Object p) {
stk[++stkp] = p;
}
public Object pop1 () {
return stk[stkp--];
}
public Object pop2 () {
Object p = stk[stkp];
stk[stkp--] = null;
return p;
}
}示例代码是一个栈结构,栈中存储对象引用,容量为 10,stkp 是栈顶指针,push 方法将对象压入栈中,pop1 和 pop2 弹出栈顶对象。pop1 直接将对象弹出,该对象可能被其它对象使用之后立刻释放,而栈中仍有指向该对象的引用,由于栈可能在程序中长久存在,所以导致弹出的对象不能被回收。 pop2 方法在弹出对象前,将栈原来持有的对象引用置空释放,从而使弹出的对象彻底与栈脱离关系而不影响 GC。对于在程序运行中要大量创建和释放的对象,加强管理是很好的习惯,使用对象池机制是很好的解决方案,根据需要在对象池中创建一批对象,将不用的对象 放回池中,待下次取出使用,这也大大节省了对象的反复创建和销毁时间。
清单 4. Java 对象池代码
import java.util.HashMap;
import java.util.LinkedHashSet;
public class ObjectFactory {
/** A counter for counting the number of objects in use. */
private static int objInUse = 0;
/** A counter for counting the number of objects in pool. */
private static int objInPool = 0;
/** The object pool. */
private static HashMap objectPool = new HashMap();
/** The corresponding object pool for a specific class. */
private static LinkedHashSet subObjPool;
/** Generate object for use */
public synchronized static Object generate(String className) {
Object retObj = null;
subObjPool = (LinkedHashSet) objectPool.get(className);
if (subObjPool != null && subObjPool.size() < 0) {
retObj = subObjPool.iterator().next();
subObjPool.remove(retObj);
objInPool--;
} else {
try {
retObj = newObj(className);
} catch (InstantiationException ie) {
return null;
} catch (IllegalAccessException iae) {
return null;
} catch (ClassNotFoundException cnfe) {
return null;
}
}
objInUse++;
return retObj;
}
public synchronized static void drop(Object freeObject) {
if (freeObject != null) {
subObjPool = (LinkedHashSet) objectPool.get(className);
if (subObjPool == null) {
subObjPool = new LinkedHashSet();
objectPool.put(className, subObjPool);
}
if (!subObjPool.contains(freeObject)) {
subObjPool.add(freeObject);
objInPool++;
objInUse--;
}
}
}
/** Counts the number of objects which are in use now. */
public static int countObjectInUse() {
return objInUse;
}
/** Checks the current size of the object pool. */
public static int checkPoolSize() {
return objInPool;
}
/** New object for class name. */
private static Object newObj(String className)
throws InstantiationException, IllegalAccessException,
ClassNotFoundException {
Object obj = Class.forName(className).newInstance();
return obj;
}
}
Java Profiler 是采用 JMX(Java Management Extensions,Java 资源管理框架)或 JVMPI(Java Virtual Machine Profiler Interface,Java 虚拟机监视程序接口)实现的对 Java 虚拟机中的资源、应用程序对象等进行监试的一类工具。Profiler 工具主要可以监视对象分配和回收、堆空间、线程运行、线程死锁、网络状态等。这为 Java 程序员进行性能分析提供了入手点,通过对程序运行时的状态分析,可以快速的定位问题,从而着手优化。Java Profiler 工具是分析 Java 程序性能的好帮手,但归根结底,性能的提高还依赖于程序员对 Java 虚拟机有一定了解,在此基础上遵循良好的设计和开发原则。这也是 Java 程序员成为真正高手的必由之路。
关于如何使用 profiler 工具,读者可参考相关资源进行深入研究,常用的 Java Profiler 工具有:
- JConsole ,虚拟机 SDK 自带工具,安装好 Java SDK 后,在 /bin 目录下启动;
- Eclipse TPTP(Test and Performance Tools Platform) 是由 Eclipse.org 顶级项目提供的一个测试与性能监测方面的工具插件;
- Netbeans Profiler ,Sun 内置于 Netbeans 中 profiler,方便用 Netbeans 开发时使用;
- Visual VM ,最初,Sun 随 JDK 6 Update 7 发布的 profiler,Visual Vm 包含 JConsole,同时界面更加美观且易于使用。