我用的是python2.6。
学习python写爬虫的时候,一般都会用到一个Demo------- ![]()
这个Dmoe在学习的时候确实是非常好的例子,但是我们可能需要对它进行修改,这就会出现一些问题。
再对demo进行修改的时候发现了一些编码问题下面就发出来做个记录。 python UnicodeEncodeError:'ascii'code can't encode characters in position 23-26:ordinal not in range(128) 这是一个编码错误。
我的错误代码具体如下:
item['intro'] = self._get_xpath_text(hxs, u'//td[contains(text(), "企业介绍")]/preceding-sibling::td/strong/text()')这样写就会发生下面的错误
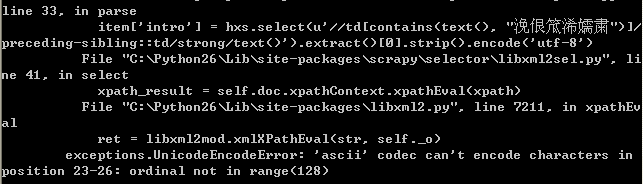
这个错误我首先在dmoz_spider.py的文件头部加入了:
# -*- coding:utf-8 -*-
发现没有任何效果。
最后通过在下面的位置加入代码问题就解决了。
这部分一定要在前面加入一句引用:
import sys

编码问题得到解决了
在原例子中把爬取得内容保存成json格式,但是我们平时需要把内容保存到数据中,一般是mysql或者excel中。
在阅读了一些文献后发现可以这么解决,
在进行爬虫的时候命令修改为:
scrapy crawl dmoz -o items.xml -t xml
这样文件会直接保存成一个XML文件,再调用mysql或者excel都可以完全的导入进去。