一、如果提高构建索引速度
1、明确当前性能瓶颈确实是lucene构建索引引起
这个问题需要借助一定的三方性能监控工具,我当时在调优时使用的监控工具是sysstat,下载地址:http://sebastien.godard.pagesperso-orange.fr/download.html ,可以选择你需要的版本,具体使用可以google。
通过这个工具对比观察服务器在构建索引和非构建索引时磁盘IO、CPU、内存使用情况,通过比较一目了然,我当时确定问题时
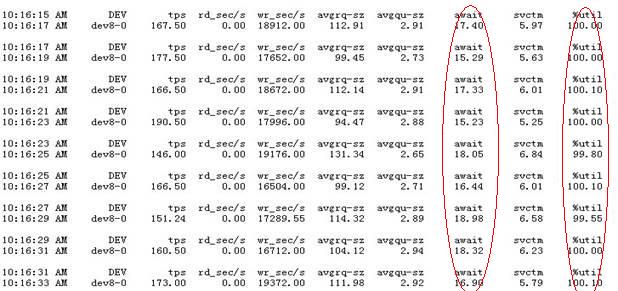
就是IO出现瓶颈,在构建索引时IO利用率达到了100%并出现IO await,所以我可以很负责任的确定是构建索引引起的性能瓶颈。
截图如下:
2、如果找到确实是构建索引引起的问题,那就要从lucene api着手优化构建索引了
a、确定lucene最新版本
我们产品线上目前版本是2.4,不过现在最新版本是3.0.2,在评估成本情况下可以对版本进行升级,3.0比2.x在性能上面确实改进很多
b、确定存储索引的磁盘是本地磁盘系统,有条件的话可以使用存储
如果磁盘一定要是远程磁盘系统,可以将远程的磁盘挂载到本地,有条件可以使用存储做为存储空间,存在在io读写及吞吐量上面比磁盘高效很多
c、尽量使用一个单例的indexwriter
创建和销毁indexwriter需要花费一定的资源的,这个视情况而定,有些系统拆分索引存储目录,可能针对不同的实例需要不同的indexwriter
d、尽量在内存中构建索引
使用indexwriter的setRAMBufferSizeMB()设置lucene写索引时的中转缓存,当内存索引空间大小超过rambuffersizemb时会将索引批量写入磁盘,这样可以避免io一直处于很高的状态,观察发现io利用率的图形是个波形图
e、尽量使用多文件索引,不要使用复合索引
多文件索引结构:多文件索引是使用一系列索引文件分别存储索引,分散管理数据的索引存储格式。多文件索引在打开时需要读取大量文件,会大大占用系统的文件句柄等资源,造成系统响应速度慢,甚至系统崩溃。
通过indexwriter.setUseCompoundFile(false);//使用多文件系统
复合索引结构:复合索引是把索引相关的一系列数据结构组织到少数几个文件中进行管理的索引存储模式。复合索引把所有的索引数据组合成简单的3个文件,大大减少了打开大量文件的压力。但是使用统一文件存储大量数据会造成数据更新的问题,每次更改需要操作一个大的数据文件,读取和存储都会比较慢。
各有优缺点,不过通过测试发现,多文件系统确实性能高很多,对大文件的存储和读取确实很耗性能
f、重复利用document和field对象
道理很简单,减少document和field对象的创建可以减少gc次数,数据量小不明显,当数据量在500万以上时,这就很明显了
g、当你使用保存的field或者term的时候,总是用相同的顺序把field添加到document。
Lucene的合并有一种优化,依赖于对保存的字段和词向量进行的批量复制,但是只有在段间字段名->数字的映射保持一致的情况下才能实施。创建相同顺序filed到document可以增加索引的优化次数,对构建索引和搜索都是性能得提升
h、在analyzer内复用同一个Token实例。
analyzer通常都为序列中的每个term创建一个新的Token实例。你可以通过复用同一个Token实例的方法大幅节约GC的开销
i、在Token中使用char[] API取代String API来展现记号文本。
在Lucene 2.3中,Token可以把他的文本用一个char数组的片段来表示,这可以节省GC的在new和回收String实例时造成的开销。通过复用同一个Token实例以及char[] API你可以避免每个词新建的所有对象。
j、打开IndexWriter时,使用autoCommit=false选项。
在Lucene 2.3中,包含了对保存字段和词向量的文档的显著优化,可以减少对非常大索引文件的合并操作。对一个长时间运行的IndexWriter使用 autoCommit=false选项,你就可以得到显著的性能提升。注意,然而这样的话,搜索器就只能在IndexWriter关闭的时候才能读取到索引的变化;如果你非常需要在写入索引的同时可以搜索到最新更新的内容,那么你应该使用autoCommit=true选项,或者周期性的关闭和重新打开writer。
k、不去索引大量小文本字段,而是把文本聚合成一个单一的“内容”字段(你还是可以索引其他的字段)。
l、增大mergeFactor(合并因子),但是不要太大。
mergeFactor越大段的合并则越晚,因为合并是索引中开销很大的一部分,所以这样做可以提高索引的速度。然而,这将降低搜索的速度,如果太大的话,你可能会耗尽文件描述符。太大的值也可能减缓索引速度,因为一次性合并越多的段,意味着越多的磁盘寻道。
m、关闭所有你并未使用的特性。
如果你存储了字段,但是查询期间并不使用的话,那么不要存储他们。词向量亦如是。如果你索引了太多的字段,关闭这些字段的norm可以提高性能。
n、使用更快的analyzer。
有时候,分析一个文档会花很长时间。例如,StandardAnalyzer非常耗时,尤其是在Lucene 2.2以下的版本的。如果你可以使用一个简单的analyzer,那么用它吧。
o、加速document构建。
从外部系统(数据库,文件系统,爬虫爬取的网站)获取一个document内容的常常是非常耗时的。
p、除非你真的需要(更快的搜索),否则不要优化。
q、 多个线程使用一个IndexWriter。
现代硬件高度并行(多核CPU,多通道内存架构,硬盘的内建指令队列,等等)。所以使用多线程添加文档多半会更快。即使是老的电脑,也经常在IO和CPU间存在并发。测试线程的数量选择性能最好的线程数量。推荐jdk1.5的线程池
r、索引分开不合并。
如果你的索引内容非常的多,你可以把你的内容分为N块,在不同的机器索引每个块,然后使用writer.addIndexesNoOptimize把它们和并为最终索引。
s、使用Java profiler。
如果这些都失败了,profile你的程序找出时间耗费在哪里。我成功使用过一个非常简单的profiler叫做JMP。有很多java的profiler。往往你会很意外的发现,一些愚蠢的、意想不到的方法花费了那么多的时间。
3、API 优化后还需要针对一些业务点进行优化
构建索引的SQL脚本调优
更改全量索引的方式
我们产品线全量索引是通过分页的方式去抓取数据并构建成索引,大数据量构建索引分页抓取数据是很愚蠢的方式,这个增加跟数据库的交互次数,导致数据库压力上去,而且性能很差,可以考虑通过游标的方式一次将数据全部load到数据库缓存中,通过游标去抓取一批构建索引
4、性能优化前后性能对比(性能测试)
通过性能测试去分析优化前后的差距,这个后期有时间分享吧
这里面很多是apache官网总结的,总结的很好,我也是参考实现的,具体参考官网
http://wiki.apache.org/lucene-java/ImproveIndexingSpeed