Region的架构
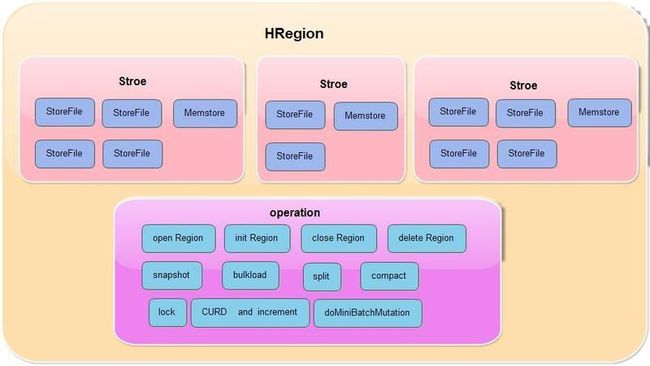
HRegionServer:
配置:
hbase.client.retries.number (默认10) 客户端的重试次数
hbase.regionserver.msginterval (默认3*1000) ???
hbase.regionserver.checksum.verify(默认false) 是否启用checksum
hbase.server.thread.wakefrequency(默认10*1000) 线程检查频率
hbase.regionserver.numregionstoreport(默认10) ???
hbase.regionserver.handler.count(默认10) handler处理线程个数
hbase.regionserver.metahandler.count(默认10) 处理meta和root的线程个数
hbase.rpc.verbose(默认false)
hbase.regionserver.nbreservationblocks(默认4)
hbase.regionserver.compactionChecker.majorCompactPriority(默认Integer.MAX_VALUE)
HRegionServer的主要操作:
包含的类有
HRegion集合
Leases(租借时间检查)
HMasterRegionInterface(管理hbase)
HServerLoad(hbase负载)
CompactSplitThread(用于合并处理)
MemStoreFlusher(用于刷新memstore)
HLog(WAL相关)
LogRoller(日志回滚)
ZooKeeperWatcher(zk监听)
SplitLogWorker(用于切分日志)
ExecutorService(用户启动open,close HRegion的线程池)
ReplicationSourceService和ReplicationSinkService(replication相关)
HealthCheckChore(健康检查)
一些监听类
MasterAddressTracker
CatalogTracker
ClusterStatusTracker
一些函数
postOpenDeployTasks() 此函数用于更新root表或meta表
各种CURD,scanner,increment操作
multi操作(对于delete和put)
对HRegion的flush,close,open(提交到线程池去做)
split,compact操作,这些最终由一个具体的HRegion去完成
启动的线程
hbase.regionserver.executor.openregion.threads 3
hbase.regionserver.executor.openroot.threads 1
hbase.regionserver.executor.openmeta.threads 1
hbase.regionserver.executor.closeregion.threads 3
hbase.regionserver.executor.closeroot.threads 1
hbase.regionserver.executor.closemeta.threads 1
hlog roller
cache flusher
compact
health check
lease
WEB UI
replication
rpc server
split worker
HRegion
配置:
HRegion的主要操作:
1.CURD和increment操作
2.doMiniBatchMutation操作(用于delete和put)
3.对region的open,delete,init,close,以及addRegionToMeta等操作
4.snapshot
5.bulkload
6.split
7.compact(major,minor)
8.lock
包含的内部类
WriteState(在flush,close,compact时会根据这个类加锁)
RegionScannerImpl(scan的region级别操作)
coprocessor的处理原理
//HRegion的构造函数
coprocessorHost = new RegionCoprocessorHost(this, rsServices, conf);
//RegionCoprocessorHost类中 将自定义的coprocessor类加载进来,并放到集合中
protected SortedSet<E> coprocessors = new SortedCopyOnWriteSet<E>(new EnvironmentPriorityComparator());
public RegionCoprocessorHost类中() {
// load system default cp's from configuration.
loadSystemCoprocessors(conf,"hbase.coprocessor.region.classes");
// load system default cp's for user tables from configuration.
if (!HTableDescriptor.isMetaTable(region.getRegionInfo().getTableName())) {
loadSystemCoprocessors(conf,"hbase.coprocessor.user.region.classes");
}
// load Coprocessor From HDFS
loadTableCoprocessors(conf);
}
public void load相关函数() {
//1.从当前线程上下文classloader中找到类并加载
//2.放到coporcessors集合中
}
//coprocessor的执行过程
//coprocessorHost.preFlush()时候会遍历执行所有集合中的处理器
HRegion#flush() {
//1.coprocessorHost.preFlush();
//2.flush
//3.coprocessorHost.postFlush();
}
服务端接收处理过程
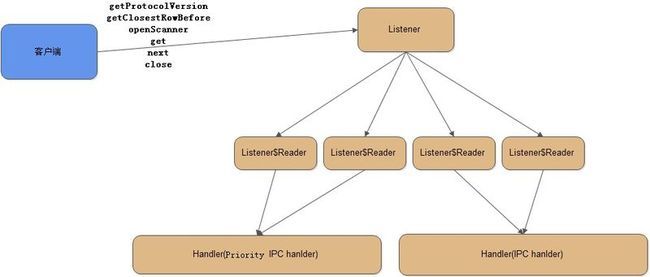
HBaseServer$Listener的run()函数和doAccept()函数简化如下 这是一个独立的listene线程
while (running) {
SelectionKey key = null;
selector.select(); // FindBugs IS2_INCONSISTENT_SYNC
Iterator<SelectionKey> iter = selector.selectedKeys().iterator();
while (iter.hasNext()) {
key = iter.next();
iter.remove();
if (key.isValid()) {
if (key.isAcceptable())
doAccept(key);
}
}
}
}
void doAccept(SelectionKey key) {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
currentReader = (currentReader + 1) % readers.length;
Reader reader = readers[currentReader];
readSelector.wakeup();
SelectionKey readKey = reader.registerChannel(channel);
c = getConnection(channel, System.currentTimeMillis());
readKey.attach(c);
}
HBaseServer$Listener$Reader的run()函数简化如下 这是一个独立的select线程
while (running) {
SelectionKey key = null;
readSelector.select();
while (adding) {
this.wait(1000);
}
Iterator<SelectionKey> iter = readSelector.selectedKeys().iterator();
while (iter.hasNext()) {
key = iter.next();
iter.remove();
if (key.isValid()) {
if (key.isReadable()) {
doRead(key);
}
}
}
}
//doRead()主要是读取远端的数据并解析处理
//没有这个process()函数,只是将逻辑简化了一下展示而言
//解析id,param并封装成一个Call对象,插入到并发队列中,之后由Handler线程处理
void process() {
int id = dis.readInt();
param = ReflectionUtils.newInstance(paramClass, conf);//read param
param.readFields(dis);
Call call = new Call(id, param, this, responder, callSize);
if (priorityCallQueue != null && getQosLevel(param) > highPriorityLevel) {
priorityCallQueue.put(call);
} else if (replicationQueue != null && getQosLevel(param) == HConstants.REPLICATION_QOS) {
replicationQueue.put(call);
} else {
callQueue.put(call); // queue the call; maybe blocked here
}
}
HBaserServer$Handler的run()函数简化如下
public void run() {
//这里的myCallQueue和callQueue是一个队列
Call call = myCallQueue.take();
Invocation call = (Invocation)param;
Method method = protocol.getMethod(call.getMethodName(),
call.getParameterClasses());
Object[] params = call.getParameters();
Object value = method.invoke(impl, params);
//最后会调用到HBaserServer自身的某个函数
//onlineRegions 是ConcurrentHashMap<String, HRegion>()
String name = HRegionInfo.encodeRegionName(regionName)
onlineRegions.get(name);
Result r = region.getClosestRowBefore(row, family);
return r;
}
flush的过程
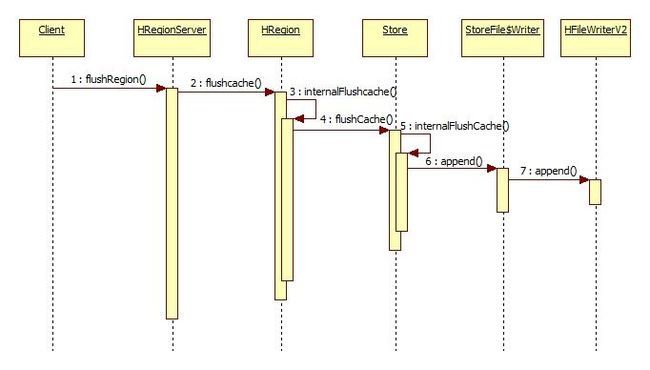
服务端是收到了客户端发来的flushRegion请求,具体过程参见 客户端请求过程一文
客户端如果是flush全表,先是获取这个表的所有region名字,然后做一次批量的flushRegion请求(多个请求),但是所有的请求都是在一个线程中执行的
和flush相关的类函数简化如下,1-4是调用顺序
1.HRegion#flushcache()
2.HRegion#internalFlushcache()
3.Store#internalFlushCache()
4.StoreFile$Writer#append()
//刷新region中的数据,注意有一个读锁
HRegion#flushcache() {
try {
lock.readLock().lock();
internalFlushcache(status);
} finally {
lock.readLock().unlock();
}
}
//这里是遍历获取region中的所有store,然后对每个store都创建一个
//StoreFlusher对象,使用这个对象来刷新数据
//注意在获取所有Store的时候使用了写锁
HRegion#internalFlushcache() {
try {
this.updatesLock.writeLock().lock();
List<StoreFlusher> storeFlushers = new ArrayList<StoreFlusher>(stores.size());
for (Store s : stores.values()) {
storeFlushers.add(s.getStoreFlusher(completeSequenceId));
}
} finally {
this.updatesLock.writeLock().unlock();
}
for (StoreFlusher flusher : storeFlushers) {
flusher.flushCache(status);
}
}
//将memstore中的数据取出然后遍历所有的KV
//将其刷新到HFile中,注意刷新的时候有一个flush锁
Store#internalFlushCache() {
InternalScanner scanner = null;
KeyValueScanner memstoreScanner = new CollectionBackedScanner(set, this.comparator);
Scan scan = new Scan();
scan.setMaxVersions(scanInfo.getMaxVersions());
scanner = new StoreScanner(this, scanInfo, scan,
Collections.singletonList(memstoreScanner), ScanType.MINOR_COMPACT,
this.region.getSmallestReadPoint(), HConstants.OLDEST_TIMESTAMP);
try {
flushLock.lock();
StoreFile.Writer writer = createWriterInTmp(set.size());
List<KeyValue> kvs = new ArrayList<KeyValue>();
boolean hasMore;
do {
hasMore = scanner.next(kvs, compactionKVMax);
for (KeyValue kv : kvs) {
Writer.append(kv);
flushed += this.memstore.heapSizeChange(kv, true);
}
kvs.clear();
}while(hasMore);
} finally {
flushLock.unlock();
}
}
//如果配置了布隆过滤器这里也会创建,最后调用
//HFileWriterV2将数据写入
StoreFile$Writer#append(final KeyValue kv) {
appendGeneralBloomfilter(kv);
appendDeleteFamilyBloomFilter(kv);
HFileWriterV2#append(kv);
trackTimestamps(kv);
}
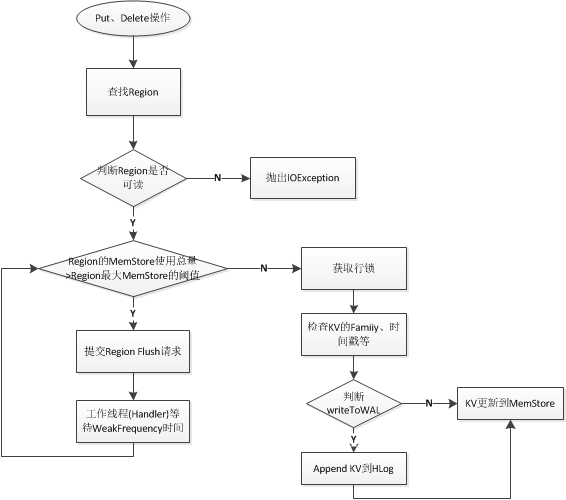
单个多个put和多个delete的过程
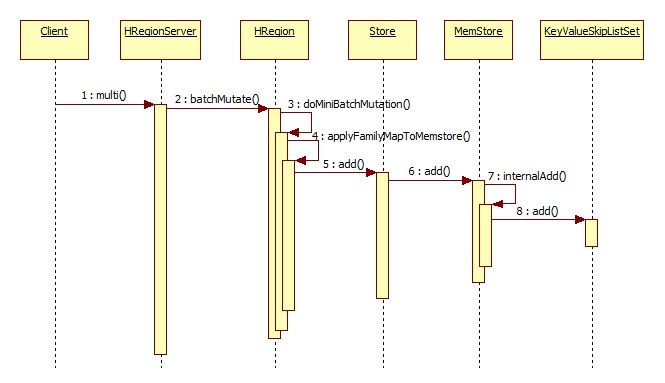
最终是将KeyValue存到KeyValueSkipListSet中,这个类内部是采用ConcurrentSkipListMap实现的
服务端是接收到客户端发来的multi请求
注意只有put操作(单个put和批量put操作)以及批量的delete操作才会执行上面的调用逻辑
incr和单个delete采用了不同的处理逻辑
简化的核心处理函数如下:
//对put和delete操作,都会进到这个函数里面
HRegion#doMiniBatchMutation() {
//1.试着获取锁
//2.更新时间戳
lock(this.updatesLock.readLock(), numReadyToWrite);
//3.写入到memstore中
long addedSize = 0;
for (int i = firstIndex; i < lastIndexExclusive; i++) {
addedSize += applyFamilyMapToMemstore(familyMaps[i], w);
}
//4.写入到WALEdit中
addFamilyMapToWALEdit(familyMaps[i], walEdit);
//5.写入到HLog中(不做sync)
HLog.appendNoSync(regionInfo, this.htableDescriptor.getName(),
walEdit, first.getClusterId(), now, this.htableDescriptor);
//6.释放锁
this.updatesLock.readLock().unlock();
//7.同步WALEdit
//8.mvcc相关
mvcc.completeMemstoreInsert(w);
//9.执行coprocessor hook
}
这里没有memstore满了判断逻辑,而是由单独的一个线程(cacheFlusher)出处理的
写入到memstore的判断逻辑图
incr的过程
核心处理逻辑如下
HRegion#increment() {
Map<Store, List<KeyValue>> tempMemstore = new HashMap<Store, List<KeyValue>>();
try {
Integer lid = getLock(lockid, row, true);
lock(this.updatesLock.readLock());
byte [] row = increment.getRow();
Get get = new Get(row);
List<KeyValue> results = get(get, false);
for(KeyValue kv : results) {
KeyValue kv = results.get();
if(kv.getValueLength() == Bytes.SIZEOF_LONG) {
amount += Bytes.toLong(kv.getBuffer(), kv.getValueOffset(), Bytes.SIZEOF_LONG);
} else {
throw new DoNotRetryIOException("Attempted to increment field that isn't 64 bits wide");
}
}
if (writeToWAL) {
walEdits.add(newKV);
}
tempMemstore.put(store, kvs);
//将WALEdit sync到HLog中
size = this.addAndGetGlobalMemstoreSize(size);
flush = isFlushSize(size);
if (flush) {
requestFlush();
}
} finally {
this.updatesLock.readLock().unlock();
releaseRowLock(lid);
}
}
可以看到incrment的执行流程是先根据row创建Get对象,然后获取这个值,再对这个值做++操作
并将结果放到临时缓存中,如果缓存已满就做刷新
从获取数据到,再做++操作,最后写入缓存(可能还要做刷新处理)这么一段过程都是需要加锁处理的,加锁只是一个行锁
单个delete的过程
主要处理简化逻辑如下
HRegion#delete(){
try {
lid = getLock(lockid, row, true);
internalDelete()
} finally {
releaseRowLock(lid);
}
}
HRegion#internalDelete() {
try {
updatesLock.readLock().lock();
//将KeyValue写入到WALEdit中
for(family : 获取delete关联的所有famliy) {
Store store = getStore(family);
for (KeyValue kv: edits) {
kv.setMemstoreTS(localizedWriteEntry.getWriteNumber());
addedSize += store.add(kv);
}
}
flush = isFlushSize(this.addAndGetGlobalMemstoreSize(addedSize));
if (flush) {
requestFlush();
}
} finally {
updatesLock.readLock().unlock();
}
}
delete是将所有的column famliy都遍历一遍然后删除和这个key相关的所有famliy,并写入缓存中,如果缓存满了就做刷新处理,同时在删除的时候会有更新锁。
get的过程
下面是核心处理逻辑,可以看到get最后是通过scan来处理的,也就是简单的将scan包装了一下
HRegion#get() {
List<KeyValue> results = new ArrayList<KeyValue>();
Scan scan = new Scan(get);
RegionScanner scanner = getScanner(scan);
List<KeyValue> list = scanner.next(results, SchemaMetrics.METRIC_GETSIZE);
return Result(list);
}
scan过程
scan是最复杂的操作,其中包含了getClosestRowBefore,openScanner,next三个操作
第一个是对用于对META和ROOT表操作的,第二个用于创建一个scan对象,第三个用于做遍历操作
首先看第一个closestRowBefore的时序图
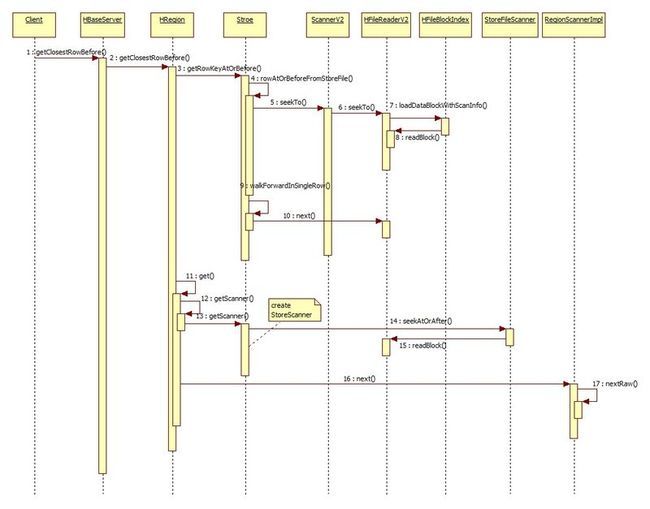
这里简单来说有这么几步操作
1.通过Store调用HFileReaderV2,这里主要用于打开一个HFile文件,然后定位到指定的key前面或者后面。
这步操作是用于在ROOT表中获取特定的KeyValue,info:server这个KeyValue,然后将这个值封装成
Get对象再去查询META表
2.调用get函数对数据进行获取,get内部又是调用scan函数的,所以实际会创建一个StroeScanner对象
3.StoreScanner也就是对底层的HFileScanner的简单封装
4.之后调用next()获取一段数据,这里还会有嵌入了filter的执行逻辑
5.最后返回给用户的是Result结果,这里就是META表中的一条记录
getClosestRowBefore的调用栈如下

scan操作的类图如下

Store是核心的类,这个类中包含了若干个StoreFile,每个StoreFile类中又有一个Reader和Writer内部类。
通过Reader内部类可以返回一个StroeFileScanner对象
而最终上层在做scan的时候,是通过RegionScannerImpl去做的,这里就包含了filter的过滤逻辑。
执行逻辑如下
//定位到一个具体的Store后,然后在这个Sotre中查找最接近指定key的KeyValue
//再根据这个KeyValue做一次get查询
//简单来说就是根据特定的key直接从HFile中查找最接近的KeyValue
//然后封装成Get操作,从META表中查询出List<KeyValue>并返回
HRegion#getClosestRowBefore() {
startRegionOperation();
Store store = getStore(family);
KeyValue key = store.getRowKeyAtOrBefore(row);
if (key != null) {
Get get = new Get(key.getRow());
get.addFamily(family);
result = get(get, null);
}
}
//先从memstore中查找最匹配的key,然后再遍历当前Store下的所有的HFile
//找到最匹配的那个key
//比如客户端发起查询.META.,test,,99999999999999,99999999999999
//实际找到key为(返回info:server那个KeyValue)
//.META.,,1/info:server/1423222815731/Put/vlen=23/ts=0
Store#getRowKeyAtOrBefore() {
this.memstore.getRowKeyAtOrBefore(state);
for (StoreFile sf : Lists.reverse(storefiles)) {
rowAtOrBeforeFromStoreFile(sf, state);
}
}
//这里是定位到-ROOT-表中的info:server 这一个KeyValue并返回
Store#rowAtOrBeforeFromStoreFile() {
HFileScanner scanner = r.getScanner(true, true, false);
if (!seekToScanner(scanner, firstOnRow, firstKV)) return;
if (walkForwardInSingleRow(scanner, firstOnRow, state)) return;
while (scanner.seekBefore(firstOnRow.getBuffer(), firstOnRow.getKeyOffset(),firstOnRow.getKeyLength())) {
KeyValue kv = scanner.getKeyValue();
if (!state.isTargetTable(kv)) break;
if (!state.isBetterCandidate(kv)) break;
// Make new first on row.
firstOnRow = new KeyValue(kv.getRow(), HConstants.LATEST_TIMESTAMP);
// Seek scanner. If can't seek it, break.
if (!seekToScanner(scanner, firstOnRow, firstKV)) break;
// If we find something, break;
if (walkForwardInSingleRow(scanner, firstOnRow, state)) break;
}
}
//先是在缓存中查找,如果找到就返回
//否则就在HFile中查找,找到后再放到缓存中
//这里读取的是一个data block
HFileReaderV2#readBlock() {
BlockCacheKey cacheKey = new BlockCacheKey(name, dataBlockOffset,
dataBlockEncoder.getEffectiveEncodingInCache(isCompaction),
expectedBlockType);
HFileBlock cachedBlock = (HFileBlock)cacheConf.getBlockCache().
getBlock(cacheKey, cacheBlock, useLock);
if (cachedBlock != null) {
return cachedBlock;
}
HFileBlock hfileBlock = fsBlockReader.readBlockData(dataBlockOffset,onDiskBlockSize, -1, pread);
cacheConf.getBlockCache().cacheBlock(cacheKey, hfileBlock,cacheConf.isInMemory());
}
//执行到这里的时候已经获取到key在META表中的接近key了
//然后在执行get操作根据META表的key再从META表中获取一条数据返回
//nextRaw最后会调用nextInternal做处理
HRegion$RegionScannerImpl#nextRaw() {
if (outResults.isEmpty()) {
// Usually outResults is empty. This is true when next is called
// to handle scan or get operation.
returnResult = nextInternal(outResults, limit, metric);
} else {
List<KeyValue> tmpList = new ArrayList<KeyValue>();
returnResult = nextInternal(tmpList, limit, metric);
outResults.addAll(tmpList);
}
}
//这个函数通过KeyValueHeap获取一条KeyValue
//KeyValueHeap是调用StoreScanner#next()
//而StoreScanner最终会调用HFileReaderv2$ScannerV2#next()
//获取一条KeyValue,最后返回一个List<KeyValue>,也就是Result
//返回结果为
//[.META.,,1/info:regioninfo/1423222781931/Put/vlen=34/ts=0,
//.META.,,1/info:server/1423222815731/Put/vlen=23/ts=0,
//.META.,,1/info:serverstartcode/1423222815731/Put/vlen=8/ts=0,
//.META.,,1/info:v/1423222781931/Put/vlen=2/ts=0]
HRegion$RegionScannerImpl#nextInternal() {
// Let's see what we have in the storeHeap.
KeyValue current = this.storeHeap.peek();
//之后再做一些filter操作,判断是否需要终止后续逻辑
}
openscanner的执行过程
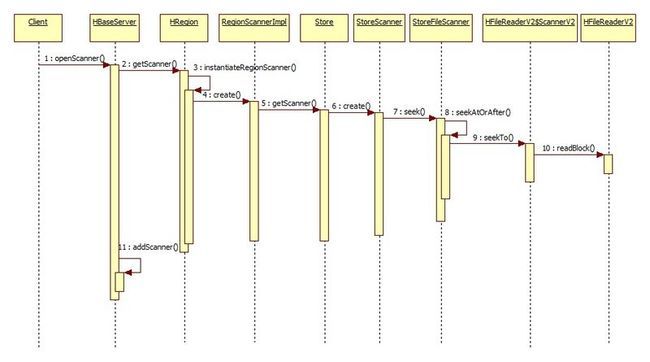
执行逻辑如下
//这里的逻辑是创建一个RegionScanner对象,这个对象内部是封装了RegionScannerImpl
//最终是调用HFileReaderV2定位到一个具体的data block附近,然后将这个scann对象缓存起来
//并创建一个scannID,将id和scan对象放到map中,并将scannID返回给用户
//之后用户就根据这个scanID去做scan操作
HRegionServer#openScanner() {
HRegion r = getRegion(regionName);
RegionScanner s = r.getScanner(scan);
return addScanner(s);
}
//创建RegionScannerImpl待以后使用
HRegion#instantiateRegionScanner() {
//返回类型为RegionScanner
return new RegionScannerImpl(scan, additionalScanners, this);
}
//RegionScannerImpl的构造函数
//此时会创建一个StoreScanner对象
//并调用StoreFileScanner#seek()
RegionScannerImpl#init() {
for (Map.Entry<byte[], NavigableSet<byte[]>> entry :scan.getFamilyMap().entrySet()) {
Store store = stores.get(entry.getKey());
//这里会创建一个StoreScanner对象
KeyValueScanner scanner = store.getScanner(scan, entry.getValue());
scanners.add(scanner);
}
}
StoreFileScanner#seek() {
//1.定位到指定的key附近
seekAtOrAfter()
}
//生成一个scannID,放到map中(map的key是scannID,value是RegionScannerImpl)
//最后再创建一个租借时间的监听器
HRegionServer#addScanner() {
scannerId = rand.nextLong();
String scannerName = String.valueOf(scannerId);
scanners.put(scannerName, s);
this.leases.createLease(scannerName, new ScannerListener(scannerName));
}
next的执行过程

执行逻辑如下
//首先根据scannID获取scan对象
//然后使用这个scan对象获取数据
//最后返回Result[] 数组给客户端
HRegionServer#next() {
RegionScanner s = this.scanners.get(scannID);
this.leases.cancelLease(scannID);
HRegion region = getRegion(s.getRegionInfo().getRegionName());
List<Result> results = new ArrayList<Result>(nbRows);
boolean moreRows = s.nextRaw(values, SchemaMetrics.METRIC_NEXTSIZE);
results.add(new Result(values));
this.leases.addLease(lease);
//最终返回Result[] 数组
}
//使用RegionScannerImpl这个内部类来抓取数据
HRegion$RegionScannerImpl#nextRaw() {
if (outResults.isEmpty()) {
// Usually outResults is empty. This is true when next is called
// to handle scan or get operation.
returnResult = nextInternal(outResults, limit, metric);
} else {
List<KeyValue> tmpList = new ArrayList<KeyValue>();
returnResult = nextInternal(tmpList, limit, metric);
outResults.addAll(tmpList);
}
}
//populateResult函数中调用KeyValueHeap#next()获取一条KeyValue
HRegion$RegionScannerImpl#nextInternal() {
boolean stopRow = isStopRow(currentRow, offset, length);
KeyValue nextKv = populateResult(results, this.storeHeap, limit, currentRow, offset,
length, metric);
//一系列的filter,过滤一些东西,看是否需要结束
}
//批量抓取一些KeyValue
KeyValueHeap#next() {
InternalScanner currentAsInternal = (InternalScanner)this.current;
boolean mayContainMoreRows = currentAsInternal.next(result, limit, metric);
KeyValue pee = this.current.peek();
}
//这里有很复杂的switch判断,主要给filter使用的
//根据不同的情况可能会出现重现定位reseek()
StoreScanner#next() {
switch(code) {
case SEEK_NEXT_ROW: {
reseek(matcher.getKeyForNextRow(kv)); break;
}
case SEEK_NEXT_COL: {
reseek(matcher.getKeyForNextColumn(kv)); break;
}
case SKIP: {
KeyValueHeap.next();
}
//......
}
}
//调用HFileReaderV2定位具体的data block
StoreFileScanner#reseek() {
if (!reseekAtOrAfter(hfs, key)) {
close();
return false;
}
cur = HFileReaderV2$ScannerV2.getKeyValue();
}