RAC学习笔记(2)-DB2和Oracle体系结构
阅读RAC和DB2的区别(资料来源为Oracle方面,所以可能有偏颇,我会再去Ibm那里找Db2与Oracle的对比,呵呵)
几个体系结构
Shared Nothing 结构
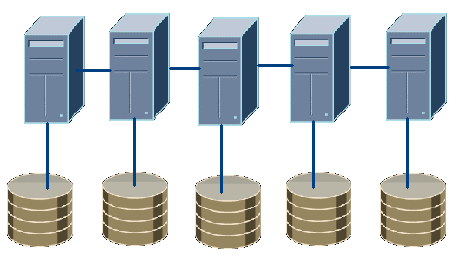
数据库被分区到集群的每个节点上。每个节点都有一个数据的唯一子集(保存着所有数据的一部分),所有访问这些数据的都要到这个节点。数据并行操作的性能,取决于数据被合理的分区。每个分区被各自的处理器进行管理。
系统可以使用双磁盘子系统,保留一个物理备份,来防止某个节点错误影响系统可用性。不过此时依然会显著的降低整体性能。
DB2的Shared-Nothing
DB2不是纯粹的Shared_Nothing, 它为了可用性,使用了Shared-Disk的数据库,它的Shared-Nothing指的是在运行期间对数据的所有权,而不是物理上的关系。如果某个子集使用的皮率很高,则会降低整个系统的吞吐量和性能。
Orace 的RAC则让磁盘可以被所有的节点链接来解决这个问题。
Shared Disk 结构
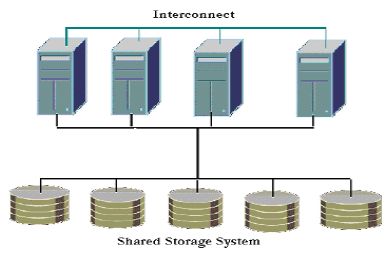
数据库文件在所有的节点间逻辑共享。每个实例都可以访问所有的数据。共享磁盘访问可以通过硬件链接或者操作系统层提供一个所有节点上设备的单一视图。如果多个节点同时链接相同的数据块,事务共享磁盘数据库系统使用磁盘I/O来同步多个节点的数据访问,比如通过一个写入块的锁来防止其他节点访问同样的数据块。
磁盘可以进行分区管理,不过如果没有很好的分区,则会显著的影响性能,并增加维护连续数据缓冲区的开销。
RAC的Shared-Cache结构
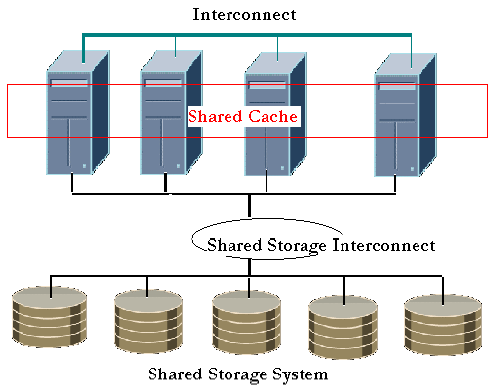
RAC使用了Cache Fusionb, 一个共享一致性缓冲技术d的技术,通过高速的内部连接的来维持共享一致性缓冲。Cache Fusion利用了集群里面所有节点的缓冲来服务于数据库事务。
在RAC里更新操作不需要磁盘I/O来同步数据,引文本地节点可以从集群的别的节点缓冲里获得需要的数据。
部署
Oracle不仅提供了一个单一的标准的Oracle数据库给用户,也包括维护工具和把单个数据库的经验用到真个集群里面。所有的标准备份还原操作适用于RAC.所有的SQL操作,包括DDL语言和完整性检查,都适用于单个实例或者集群配置。
从一个单一的实例可以通过EM(Enterprise Manager 11g)工具简单的融合进入一个已经创建,并且RAC已经安装的系统。数据文件无需修改。增加或者删除一个节点,不需要任何的数据修改或者分区。
DB2则复杂的多,需要在一个新增的几点上移动数据。所有数据需要先卸载然后在在每个逻辑节点上重新加载。每次在集群增加一个节点都需要分区。
DB2的分区
分区指逻辑的节点和他拥有的数据。每个分区有自己的缓冲池(Buffer pool), 包缓冲(oackage cache)等。 一个分区只能直接访问数据的一个子集。
给一个拥有上千的表格的应用进行分区是一个复杂的任务。而且应用可能经常变化。为了保证负载在集群环境所有节点的均衡,经常需要重新分区。
DB2的节点组(nodegroups)
每个节点、分区被指派一个节点组。每个表空间(Tablespace)被指派一个节点组。当表格创建后,将直白一个由一个或多个列组合成的分区关键字。所有插入到表格的数据,数据行的分区值被Hash到一个Hash Table里面。然后根据当前的分区映射指派一个分区。默认的分区映射在一个节点组的各分区间均分数据。
尽管DB2在没有指定分区关键字(Key)是,会自动根据主键或者第一个不是很长的字段进行分区,必须为一个访问量大的表格检测一个最佳的分区关键字的情况依然可能在几个竞争参数时发生。
分区关键字需要均匀的在所偶的逻辑节点上分布数据。这需要熟悉表格的定义和列的使用方法。在某些情况下,及时熟悉也不可能做到均匀分布。
在关联(Join)字段,你需要小心的选择分区关键字,来实现(co-located) Join,也就是可以在同一个节点执行而不需要其它的内部分区的通讯。 Co-locate 是 DB2的性能关键。在一些情况下,不能Co-locate所有的关联数据。虽然现在的告诉内部数据链接加少了其重要性,但减少信息的流通量依然对于居群数据库性能非常重要。
存取分区数据,(比如表格大小,经常查询用到的),需要检测分区关键字,如果没有合适的 co-location 列,你可以在每个节点创建一个备份。当然更新所有复制的数据将导致性能降低。
所有的唯一键和主键,是分区关键字的超集(SuperSet).也就意味着,如果你的强制唯一约束的列不是分区列,你的应用需要改变。
DB2提供了 Design Advisor 在创建数据库或者合并非分区数据库到分区数据库时如何分区的推荐和建议。不过最后还是得DBA手工进行实现。提供的建议也需要DBA根据负载情况进行调整,避免数据倾斜和热点区域,他们都影响性能。
几个体系结构
Shared Nothing 结构
数据库被分区到集群的每个节点上。每个节点都有一个数据的唯一子集(保存着所有数据的一部分),所有访问这些数据的都要到这个节点。数据并行操作的性能,取决于数据被合理的分区。每个分区被各自的处理器进行管理。
系统可以使用双磁盘子系统,保留一个物理备份,来防止某个节点错误影响系统可用性。不过此时依然会显著的降低整体性能。
DB2的Shared-Nothing
DB2不是纯粹的Shared_Nothing, 它为了可用性,使用了Shared-Disk的数据库,它的Shared-Nothing指的是在运行期间对数据的所有权,而不是物理上的关系。如果某个子集使用的皮率很高,则会降低整个系统的吞吐量和性能。
Orace 的RAC则让磁盘可以被所有的节点链接来解决这个问题。
Shared Disk 结构
数据库文件在所有的节点间逻辑共享。每个实例都可以访问所有的数据。共享磁盘访问可以通过硬件链接或者操作系统层提供一个所有节点上设备的单一视图。如果多个节点同时链接相同的数据块,事务共享磁盘数据库系统使用磁盘I/O来同步多个节点的数据访问,比如通过一个写入块的锁来防止其他节点访问同样的数据块。
磁盘可以进行分区管理,不过如果没有很好的分区,则会显著的影响性能,并增加维护连续数据缓冲区的开销。
RAC的Shared-Cache结构
RAC使用了Cache Fusionb, 一个共享一致性缓冲技术d的技术,通过高速的内部连接的来维持共享一致性缓冲。Cache Fusion利用了集群里面所有节点的缓冲来服务于数据库事务。
在RAC里更新操作不需要磁盘I/O来同步数据,引文本地节点可以从集群的别的节点缓冲里获得需要的数据。
部署
Oracle不仅提供了一个单一的标准的Oracle数据库给用户,也包括维护工具和把单个数据库的经验用到真个集群里面。所有的标准备份还原操作适用于RAC.所有的SQL操作,包括DDL语言和完整性检查,都适用于单个实例或者集群配置。
从一个单一的实例可以通过EM(Enterprise Manager 11g)工具简单的融合进入一个已经创建,并且RAC已经安装的系统。数据文件无需修改。增加或者删除一个节点,不需要任何的数据修改或者分区。
DB2则复杂的多,需要在一个新增的几点上移动数据。所有数据需要先卸载然后在在每个逻辑节点上重新加载。每次在集群增加一个节点都需要分区。
DB2的分区
分区指逻辑的节点和他拥有的数据。每个分区有自己的缓冲池(Buffer pool), 包缓冲(oackage cache)等。 一个分区只能直接访问数据的一个子集。
给一个拥有上千的表格的应用进行分区是一个复杂的任务。而且应用可能经常变化。为了保证负载在集群环境所有节点的均衡,经常需要重新分区。
DB2的节点组(nodegroups)
每个节点、分区被指派一个节点组。每个表空间(Tablespace)被指派一个节点组。当表格创建后,将直白一个由一个或多个列组合成的分区关键字。所有插入到表格的数据,数据行的分区值被Hash到一个Hash Table里面。然后根据当前的分区映射指派一个分区。默认的分区映射在一个节点组的各分区间均分数据。
尽管DB2在没有指定分区关键字(Key)是,会自动根据主键或者第一个不是很长的字段进行分区,必须为一个访问量大的表格检测一个最佳的分区关键字的情况依然可能在几个竞争参数时发生。
分区关键字需要均匀的在所偶的逻辑节点上分布数据。这需要熟悉表格的定义和列的使用方法。在某些情况下,及时熟悉也不可能做到均匀分布。
在关联(Join)字段,你需要小心的选择分区关键字,来实现(co-located) Join,也就是可以在同一个节点执行而不需要其它的内部分区的通讯。 Co-locate 是 DB2的性能关键。在一些情况下,不能Co-locate所有的关联数据。虽然现在的告诉内部数据链接加少了其重要性,但减少信息的流通量依然对于居群数据库性能非常重要。
存取分区数据,(比如表格大小,经常查询用到的),需要检测分区关键字,如果没有合适的 co-location 列,你可以在每个节点创建一个备份。当然更新所有复制的数据将导致性能降低。
所有的唯一键和主键,是分区关键字的超集(SuperSet).也就意味着,如果你的强制唯一约束的列不是分区列,你的应用需要改变。
DB2提供了 Design Advisor 在创建数据库或者合并非分区数据库到分区数据库时如何分区的推荐和建议。不过最后还是得DBA手工进行实现。提供的建议也需要DBA根据负载情况进行调整,避免数据倾斜和热点区域,他们都影响性能。