处理中文乱码和中文部分乱码
文章转自:http://book.51cto.com/art/201112/306309.htm
在网络操作中,关于中文乱码很多初学者都感到非常困难,如何解决乱码?不要没有目的胡乱转码,笔者访问了几个初学者,他们对于这个问题常用的方法就是一个一个编码去试直到找到为止,但有些情况即使一个一个地去试也不能解决问题。在网络标准接口内容中已经简单解释了一部分,下面用几个例子,对网络操作中的几个典型中文乱码进行讲解。
1.第一种情况
服务器和客户端编码不统一造成中文乱码,当服务器返回数据是UTF-8格式时,客户端在读取输入流时,需要将其转换成UTF-8格式,请看客户端部分代码:
代码中关键代码是,new String(b,"utf-8"),将byte数组转换成UTF-8格式的字符串,结果如图10-17所示。
当改成new String(b,"gb2312")时得到结果如图10-18所示。


如何避免中文乱码问题,首先,不要频繁转码和漫无目的转码,这样转来转去最后自己也不知道转到哪里去了,其次,尽量使客户端程序的编码和服务器编码统一,再次避免用字节的方式去读取中文和操作中文字符串,因为一个汉字占两个字节,稍不注意开发过程中就会出现读取一个字节,造成读取了半个字,就会出现乱码。
2.第二种情况
中文汉字中出现少部分中文乱码。这种现象看起来很怪异,往往在开发过程中,读者都有可能这样操作了,但没有发现。这种现象是怎么造成的呢?先看例子程序。
实例:
读取文件的核心代码如下(为了测试多一些的汉字,本例将把很多汉字写在test.txt里放在assets文件夹下):
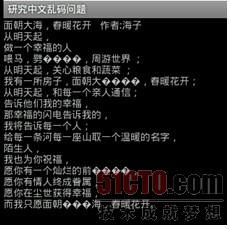
由上述代码产生的效果如图10-19所示。
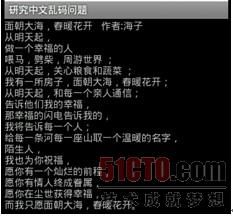
部分乱码的现象出现了,原因我先不讲,先改动代码再看看效果。把byte buffer[] = new byte[100]改成byte buffer[] = new byte[inputStream.available()],运行后得到的效果如图10-20所示。
思考一下:100和inputStream.available()的区别,就会出现中文部分乱码的问题?原因是有可能在读取100个字节的时候正好遇到一个汉字的前半个字节,后100个字节的第一位置的字节也是这个字的后半个字节,半个字节是汉字吗?这样当然会出现乱码了。把字节的数组直接设置成输入流的长度,在读取的时候,一次性读取,那么就不会出现所谓的半个字的现象,当然也不会出现乱码的问题了。
还有一个解决办法,就是不以字节的方式读取文件,以字符的方式读取,一个字符装一个汉字是合法的,看一下代码
得到的结果当然是没有乱码的效果。读者在开发过程中遇到中文乱码问题,要认真分析和思考,总能解决问题的。