腾讯后台开发技术总监浅谈过载保护 小心雪崩效应
摘要: 每个系统,都有自己的最大处理能力,后台技术人员对此必须很清楚,且要注意自我保护,不然就会被雪球压垮,出现雪崩。
雪球:
对于时延敏感的服务,当外部请求超过系统处理能力,如果系统没有做相应保护,可能导致历史累计的超时请求达到一定规模,像雪球一样形成恶性循环。由于系统处理的每个请求都因为超时而无效,系统对外呈现的服务能力为0,且这种情况下不能自动恢复。
腾讯后台开发技术总监bison,给大家分享了非常精彩的过载保护,其看似简单,但是要做好并不容易。这里用两个曾经经历的反面案例,给出过载保护的直观展现,并附上一点感想。
案例一 基本情况
如下图,进程A是一个单进程系统,通过udp套接字接收前端请求进行处理。在处理过程中,需要访问后端系统B,是同步的方式访问后端系统B,根据后端系统B的SLA,超时时间设置是100ms。前端用户请求的超时时间是1s。
进程A的时序是:
Step1: 从socket接收缓冲区接收用户请求
Step2: 进行本地逻辑处理
Step3: 发送请求到后端系统B
Step4: 等待后端系统B返回
Step5: 接收后端系统B的应答
Step6: 应答前端用户,回到step1处理下一个请求

正常情况下的负载
正常情况下:
1、前端请求报文大小约100Bytes。前端请求的峰值每分钟1800次,即峰值每秒30次。
2、后端系统B并行能力较高,每秒可以处理10000次以上,绝大多数请求处理时延在20ms内。
3、进程A在处理请求的时候,主要时延是在等待后端系统B,其他本地运算耗时非常少,小于1ms
这个时候,我们可以看出,系统工作良好,因为处理时延在20ms内,每秒进程A每秒中可以处理50个请求,足以将用户每秒峰值30个请求及时处理完。
导火索
某天,后端系统B进行了新特性发布,由于内部逻辑变复杂,导致每个请求处理时延从20ms延长至50ms,根据sla的100ms超时时间,这个时延仍然在正常范围内。当用户请求达到峰值时间点时,灾难出现了,用户每次操作都是“服务器超时无响应”,整个服务不可用。
过载分析
当后端系统B处理时延延长至50ms的时候,进程A每秒只能处理20个请求(1s / 50ms = 20 )。小于正常情况下的用户请求峰值30次/s。这个时候操作失败的用户往往会重试,我们观察到前端用户请求增加了6倍以上,达到200次/s,是进程A最 大处理能力(20次/s)的10倍!
这个时候为什么所有用户发现操作都是失败的呢? 为什么不是1/10的用户发现操作能成功呢? 因为请求量和处理能力之间巨大的差异使得5.6s内就迅速填满了socket接收缓冲区(平均能缓存1000个请 求,1000/(200-20)=5.6s),并且该缓冲区将一直保持满的状态。这意味着,一个请求被追加到缓冲区里后,要等待50s(缓存1000个请 求,每秒处理20个,需要50s)后才能被进程A 取出来处理,这个时候用户早就看到操作超时了。换句话说,进程A每次处理的请求,都已经是50s以前产生的,进程A一直在做无用功。雪球产生了。
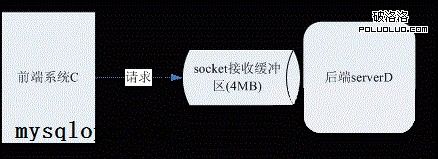
案例二 基本情况
前端系统C通过udp访问后端serverD,后端server D的udp套接字缓冲区为4MB,每个请求大小约400字节。后端serverD偶尔处理超时情况下,前端系统C会重试,最多重试2次。
正常情况下的负载
正常情况,后端serverD单机收到请求峰值为300次/s,后端serverD单机处理能力是每秒1500次,时延10ms左右。这个时候工作正常。
导火索
由于产品特性(例如提前通知大量用户,未来某某时刻将进行一项秒杀活动;类似奥运门票,大量用户提前得知信息:某日开始发售门票),大量的用户聚集 在同 一时刻发起了大量请求,超出了后台serverD的最大负载能力。操作响应失败的用户又重试, 中间系统的重试,进一步带来了更大量的请求(正常情况下的9倍)。导致所有用户操作都是失败的。
过载分析
只是导火索不一样,同案例一,巨大的请求和处理能力之间的鸿沟,导致后端serverD的4M大小的接收缓冲区迅速填满(4秒就填满),且过载时间 内, 接收缓冲区一直都是满的。而处理完缓冲区内的请求,ServerD需要6秒以上(4MB / 400 / 1500 = 6.7S)。所以serverD处理的请求都是6s之前放入缓冲区的,而该请求在最前端早已经超时。雪球形成了。
启示
1、 每 个系统,自己的最大处理能力是多少要做到清清楚楚。例如案例一中的前端进程A,他的最大处理能力不是50次/s,也不是20次/S,而是10次/S。因为 它是单进程同步的访问后端B, 且访问后端B的超时时间是100ms,所以他的处理能力就是1S/100ms=10次/S。而平时处理能力表现为50次/S,只是运气好。
2、 每个系统要做好自我保护,量力而为,而不是尽力而为。对于超出自己处理能力范围的请求,要勇于拒绝。
3、 每个系统要有能力发现哪些是有效的请求,哪些是无效的请求。上面两个案例中,过载的系统都不具备这中慧眼,逮着请求做死的处理,雪球时其实是做无用功。
4、 前端系统有保护后端系统的义务,sla中承诺多大的能力,就只给到后端多大的压力。这就要求每一个前后端接口的地方,都有明确的负载约定,
一环扣一环。
5、 当过载发生时,该拒绝的请求(1、超出整个系统处理能力范围的;2、已经超时的无效请求)越早拒绝越好。就像上海机场到市区的高速上,刚出机场就有电子公示牌显示,进入市区某某路段拥堵,请绕行。
6、 对于用户的重试行为,要适当的延缓。例如登录发现后端响应失败,再重新展现登录页面前,可以适当延时几秒钟,并展现进度条等友好界面。当多次重试还失败的情况下,要安抚用户。
7、 产品特性设计和发布上,要尽量避免某个时刻导致大量用户集体触发某些请求的设计。发布的时候注意灰度。
8、 中间层server对后端发送请求,重试机制要慎用,一定要用的话要有严格频率控制。
9、 当雪球发生了,直接清空雪球队列(例如重启进程可以清空socket 缓冲区)可能是快速恢复的有效方法。
10、过载保护很重要的一点,不是说要加强系统性能、容量,成功应答所有请求,而是保证在高压下,系统的服务能力不要陡降到0,而是顽强的对外展现最大有效处理能力。
对于“每个系统要有能力发现哪些是有效的请求,哪些是雪球无效的请求”,这里推荐一种方案:在该系统每个机器上新增一个进程:interface进 程。 Interface进程能够快速的从socket缓冲区中取得请求,打上当前时间戳,压入channel。业务处理进程从channel中获取请求和该请 求的时间戳,如果发现时间戳早于当前时间减去超时时间(即已经超时,处理也没有意义),就直接丢弃该请求,或者应答一个失败报文。
Channel是一个先进先出的通信方式,可以是socket,也可以是共享内存、消息队列、或者管道,不限。
Socket缓冲区要设置合理,如果过大,导致及时interface进程都需要处理长时间才能清空该队列,就不合适了。建议的大小上限是:缓存住超时时间内interface进程能够处理掉的请求个数(注意考虑网络通讯中的元数据)。
