Understanding Web Internals--The flow of Messages
HTTP messages are the blocks of data sent between HTTP applications.These blocks of data begin with some text meta-information describing the message contents and meaning,followed by optional data.
Messages Commute Inbound to the Origin Server
HTTP uses the terms inbound and outbound to describe transactional direction.Messages travel inbound to the origin server,and when their work is done,they travel outbound back to the user agent.
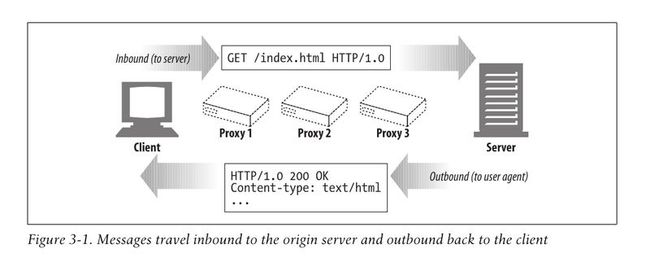
Messages Flow Downstream
HTTP messages flow like rivers.All messages flow downstream,regardless of whether they are request messages or response messages.The sender of any message is upstream of the receiver.
Message syntax
Here's the format for a request message:
<method> <request-URL> <version>
<headers>
<entity-body>
Here's the format for a response message
<version> <status> <reason-phrase>
<headers>
<entity-body>
Here's a quick description of the various parts:
method
the action that the client wants the server to perform on the resource.It is a single word,like "GET","HEAD",or "POST".
Common HTTP methods
Method Description Message body?
GET Get a document from the server No
HEAD Get just the headers for a document from No
the server
POST Send data to the server for processing Yes
PUT Store the body of the request on the server Yes
TRACE Trace the message through proxy servers No
to the server
OPTIONS Determine what methods can operate on a No
server
DELETE Remove a document from the server No
Not all servers implement all seven of the methods above.Furthermore,because HTTP was designed to be easily extensible,other servers may implement their own request methods in addition to these.These additional methods are called extension methods,because they extend the HTTP speicfication.
To be compliant with HTTP Version 1.1,a server need implement only the GET and HEAD methods for its resource.
Even when servers do implement all of these methods,the methods most likely have restricted uses.For example,servers that support DELETE or PUT would not want just anyone to be able to delete or store resources.These restrictions generally are set up in the server's configuration,so they vary from site to site and from server to server.
head method in details
The HEAD method behaves exactly liek the GET method,but the server returns only the headers in the response.No entity body is ever returned.This allows a client to inspect the headers for a resource without having to actually get the resource.Using HEAD,you can:
Find out about a resource (e.g. determine its type) without getting it
See if an object exists,by looking at the status code of the response
Test if the resource has been modified,by looking at the headers
put method in details
The PUT method writes documents to a server,in the inverse of the way that GET reads documents from a server.Some publishing systems let you create web pages and install them directly on a web server using PUT.
The semantics of the PUT method are for the server to take the body of the request and either use it to create a new document named by the requested URL or,if that URL already exists,use the body to replace it.
Because PUT allows you to change content,many web servers require you to log in with a password before you can perform a PUT.You can read more about password authentication.
post method in details
The post method was designed to send input data to the server.In pratice,it is often used to support HTML forms.The data from a filled-in form typically is sent to the server,which then marshals it off to where it needs to go.
options method in details
The option method asks the server to tell us about the various supported capabilities of the web server.You can ask a server about what methods it supports in general or for particular resources.
This provides a means for client applications to determine how best to access various resources without actually having to access them.
delete method in details
The delete method asks the server to delete the resources speicified by the request URL.However,the client application is not guaranteed that the delete is carried out.This is because the HTTP speicification allows the server to override the request without telling the client.
trace method in details
When a client makes a request,that request may have to travel through firewalls,proxies,gateways,or other applications.Each of these has the opportunity to modify the original HTTP request.The TRACE method allows clients to see how its request looks when it finally makes it to the server.
A TRACE request initiates a "loopback" diagnostic at the destination server.The server at the final leg of the trip bounces back a TRACE response, with the virgin
request-URL
A complete URL naming the requested resource,or the path component of the URL.
version
The version of HTTP that the message is using.Its format looks like:
HTTP/<major>.<minor>
where major and minor are intergers.
status-code
As methods tell the server what to do,status code tell the client what happened.
Status codes live in the start lines of responses.
When clients send request messages to an HTTP server,many things can happen.If you are fortunate,the request will complete successfully.You might not always be so lucky.The server may tell you that the resource you requested could not be found,that you don't have permission to access the resource,or perhaps that the resource has moved someplace else.
Status codes are returned in the start line of each response message.Both a numeric and a human-readable status are returned.The numeric code makes errors processing easy for programs,while the reason phrase is easily understood by humans.
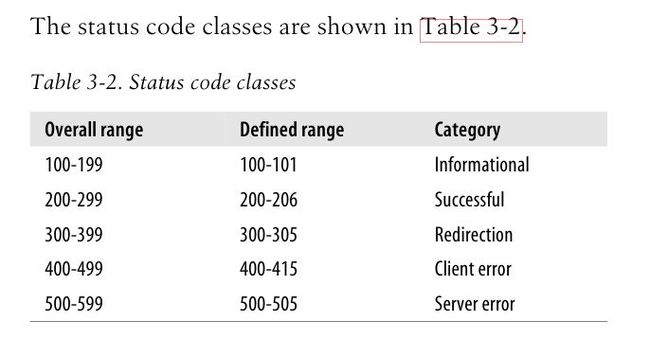
The difference status codes are grouped into classes by their-digit numeric codes.Stauts code between 200 and 299 represent success.Codes between 300 and 399 indicate that the resource has been moved.Codes between 400 and 499 mean that the client did something wrong in the request.Codes between 500 and 599 mean something went awry on the server.
reason-phrase
A human-readable version of the numeric status code,consisting of all the text until the end-of-line sequence.The reason phrase is meant solely for human consumption,so,for example,response lines containing "HTTP/1.0 200 NOT OK" and "HTTP/1.0 200 OK" should be treated as equivalent success indications,despite the reason phrases suggesting otherwise.
headers
Zero or more headers,each of which is a name,followed by a colon(:),followed by optional whitespace,followed by a value,followed by a CRLF.The headers are terminated by a blank line(CRLF),marking the end of the list of headers and the beginning of the entity body.Some versions of HTTP,such as HTTP/1.1,require certain headers to be present for the request or response message to be valid.
header classifications
The HTTP speicification defines serveral header fields.Applications also are free to invent their own home-brewed headers.HTTP headers are classified into:
General headers
Can appear in both request and response messages
Request headers
Provide more information about the request
Response headers
Provide more information about the response
Entity headers
Describe body size and contents,or the resource itself
Extension headers
New headers that are not defined in the specification
Each HTTP header has a simple syntax: a name,followed by a colon(:),followed by optional whitespace,followed by the field value,followed by a CRLF.

Long header lines can be made more readable by breaking them into multiple lines,preceding each extra line with at least one space or tab character.

entitiy-body
The entity body contains a block of arbitrary data.Not all messages contain entity bodies,so sometimes a message terminates with a bare CRLF.