SQL语句 删除表user 中字段name 内容重复的记录,A表 ,B表 字段相同 有关联关系的表 对表两个表中的数据
今天去面试!我给大意了,直接写了个删除语句!又中招了。。。
在网上找了半天也没找到合适的代码!
回来想了想才知道自已太大意了!想了良久,想出了这么个办法,
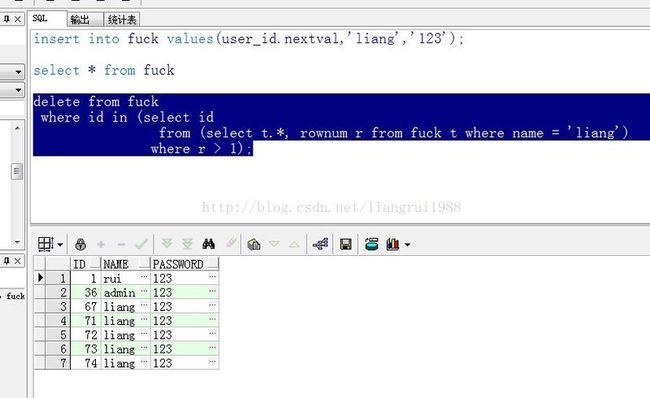
insert into fuck values(user_id.nextval,'liang','123');
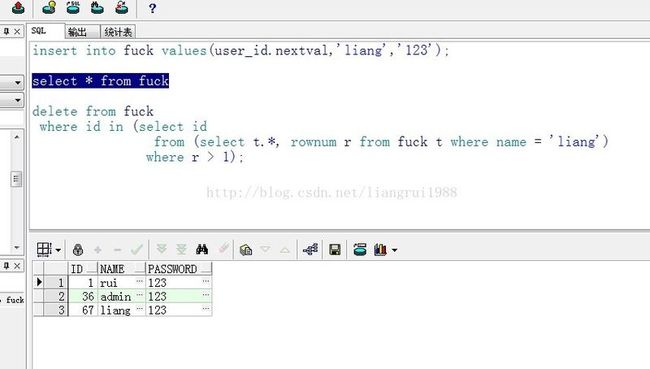
select * from fuck
delete from fuck
where id in (select id
from (select t.*, rownum r from fuck t where name = 'liang')
where r > 1);
今天又想了想,还是不行呀!只能指定值!一不做二不休,又是几个小时的研究,他奶奶的,功夫不负有心上,终于思考出一个思路,并成功!也许有更简单的写法,
就是用第三张临时表,没有测试过,还有一种是很复杂的查询语句,方法很多种吧
declare
v_sql varchar2(500);
v_tempName varchar2(30);
cursor t_name is/*提取有重得的名字*/
select name from fuck group by name having count(name) >1;
begin
v_sql:='delete from fuck
where id in (select id
from (select t.*, rownum r from fuck t where name = :1)
where r > 1) ';
for t_names in t_name loop /*循环读取并删除*/
execute immediate v_sql using t_names.name;
dbms_output.put_line('成功删除重复数据: '||t_names.name);
end loop;
end;
方式二:
insert into fucks(id,name) values(1,'aa'); insert into fucks(id,name) values(1,'aa'); insert into fucks(id,name) values(2,'aa'); insert into fucks(id,name) values(2,'aa'); insert into fucks(id,name) values(3,'vv'); insert into fucks(id,name) values(3,'vv'); insert into fucks(id,name) values(8,'bbb'); /***********创建临时表 并查询出数据不重复的字段***************/ create global temporary table tempTable on commit preserve rows as select distinct id,name from fucks; /***********删除原有的表***************/ drop table fucks; /***********把监时表插入到 新建原有表***************/ create table fucks as select * from tempTable; drop table tempTable;--需要重新登陆才能删除临时表 select * from fucks; select * from tempTable; --方式三 delete from fucks f1 where rowid not in (select min(rowid) from fucks f2 where f1.id = f2.id and f1.name = f2.name) /***********************************字段相同 有关联关系的表 对表两个表中的数据***********************/ create table newfucks as select * from fucks select * from newfucks; select * from newfucks a join fucks b on a.id=b.id; select * from newfucks a join fucks b on a.id=b.id and a.name=b.name; insert into newfucks(id,name) values(8,'hdddd'); /***********************************查询a表 条件 a和b表不相同的数据***********************/ select * from newfucks a where a.id not in (select id from fucks) or a.name not in (select name from fucks); --方试二 进行优化 select * from newfucks a where not exists (select 1 from fucks b where a.name=b.name and a.id=b.id)
--去掉重复数据 保留最后插入id 方法很多,还得学习呀...
--按名称分组 之后 按id 排序 再以每个组生成序列号 select id,name,row_number() over(partition by name order by id desc) fn from fucks --取第一个序号 最后生成的id select * from ( select id,name,row_number() over(partition by name order by id desc) fn from fucks ) where fn=1; --savepoint a1; --delete delete from fucks where id not in( select id from ( select id,name,row_number() over(partition by name order by id desc) fn from fucks ) where fn=1 );