storm入门 第四章 消息的可靠处理
4.1 简介
storm可以确保spout发送出来的每个消息都会被完整的处理。本章将会描述storm体系是如何达到这个目标的,并将会详述开发者应该如何使用storm的这些机制来实现数据的可靠处理。
4.2 理解消息被完整处理
一个消息(tuple)从spout发送出来,可能会导致成百上千的消息基于此消息被创建。
我们来思考一下流式的“单词统计”的例子:
storm任务从数据源(Kestrel queue)每次读取一个完整的英文句子;将这个句子分解为独立的单词,最后,实时的输出每个单词以及它出现过的次数。
本例中,每个从spout发送出来的消息(每个英文句子)都会触发很多的消息被创建,那些从句子中分隔出来的单词就是被创建出来的新消息。
这些消息构成一个树状结构,我们称之为“tuple tree”,看起来如图1所示:

图1 示例tuple tree
在什么条件下,Storm才会认为一个从spout发送出来的消息被完整处理呢?答案就是下面的条件同时被满足:
- tuple tree不再生长
- 树中的任何消息被标识为“已处理”
如果在指定的时间内,一个消息衍生出来的tuple tree未被完全处理成功,则认为此消息未被完整处理。这个超时值可以通过任务级参数Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS 进行配置,默认超时值为30秒。
4.3 消息的生命周期
如果消息被完整处理或者未被完整处理,Storm会如何进行接下来的操作呢?为了弄清这个问题,我们来研究一下从spout发出来的消息的生命周期。这里列出了spout应该实现的接口:

首先, Storm使用spout实例的nextTuple()方法从spout请求一个消息(tuple)。 收到请求以后,spout使用open方法中提供的SpoutOutputCollector向它的输出流发送一个或多个消息。每发送一个消息,Spout会给这个消息提供一个message ID,它将会被用来标识这个消息。
假设我们从kestrel队列中读取消息,Spout会将kestrel 队列为这个消息设置的ID作为此消息的message ID。 向SpoutOutputCollector中发送消息格式如下:
![]()
接来下,这些消息会被发送到后续业务处理的bolts, 并且Storm会跟踪由此消息产生出来的新消息。当检测到一个消息衍生出来的tuple tree被完整处理后,Storm会调用Spout中的ack方法,并将此消息的messageID作为参数传入。同理,如果某消息处理超时,则此消息对应的Spout的fail方法会被调用,调用时此消息的messageID会被作为参数传入。
注意:一个消息只会由发送它的那个spout任务来调用ack或fail。如果系统中某个spout由多个任务运行,消息也只会由创建它的spout任务来应答(ack或fail),决不会由其他的spout任务来应答。
我们继续使用从kestrel队列中读取消息的例子来阐述高可靠性下spout需要做些什么(假设这个spout的名字是KestrelSpout)。
我们先简述一下kestrel消息队列:
当KestrelSpout从kestrel队列中读取一个消息,表示它“打开”了队列中某个消息。这意味着,此消息并未从队列中真正的删除,而是将此消息设置为“pending”状态,它等待来自客户端的应答,被应答以后,此消息才会被真正的从队列中删除。处于“pending”状态的消息不会被其他的客户端看到。另外,如果一个客户端意外的断开连接,则由此客户端“打开”的所有消息都会被重新加入到队列中。当消息被“打开”的时候,kestrel队列同时会为这个消息提供一个唯一的标识。
KestrelSpout就是使用这个唯一的标识作为这个tuple的messageID的。稍后当ack或fail被调用的时候,KestrelSpout会把ack或者fail连同messageID一起发送给kestrel队列,kestrel会将消息从队列中真正删除或者将它重新放回队列中。
4.4 可靠相关的API
为了使用Storm提供的可靠处理特性,我们需要做两件事情:
- 无论何时在tuple tree中创建了一个新的节点,我们需要明确的通知Storm;
- 当处理完一个单独的消息时,我们需要告诉Storm 这棵tuple tree的变化状态。
通过上面的两步,storm就可以检测到一个tuple tree何时被完全处理了,并且会调用相关的ack或fail方法。Storm提供了简单明了的方法来完成上述两步。
为tuple tree中指定的节点增加一个新的节点,我们称之为锚定(anchoring)。锚定是在我们发送消息的同时进行的。为了更容易说明问题,我们使用下面代码作为例子。本示例的bolt将包含整句话的消息分解为一系列的子消息,每个子消息包含一个单词。
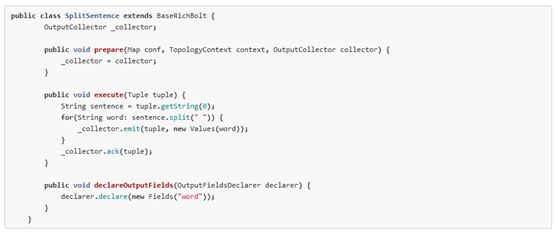
每个消息都通过这种方式被锚定:把输入消息作为emit方法的第一个参数。因为word消息被锚定在了输入消息上,这个输入消息是spout发送过来的tuple tree的根节点,如果任意一个word消息处理失败,派生这个tuple tree那个spout 消息将会被重新发送。
与此相反,我们来看看使用下面的方式emit消息时,Storm会如何处理:
![]()
如果以这种方式发送消息,将会导致这个消息不会被锚定。如果此tuple tree中的消息处理失败,派生此tuple tree的根消息不会被重新发送。根据任务的容错级别,有时候很适合发送一个非锚定的消息。
一个输出消息可以被锚定在一个或者多个输入消息上,这在做join或聚合的时候是很有用的。一个被多重锚定的消息处理失败,会导致与之关联的多个spout消息被重新发送。多重锚定通过在emit方法中指定多个输入消息来实现:

多重锚定会将被锚定的消息加到多棵tuple tree上。
注意:多重绑定可能会破坏传统的树形结构,从而构成一个DAGs(有向无环图),如图2所示:
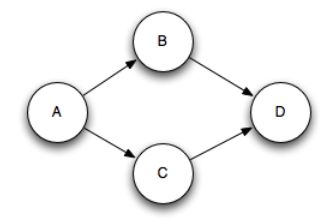
图2 多重锚定构成的钻石型结构
Storm的实现可以像处理树那样来处理DAGs。
锚定表明了如何将一个消息加入到指定的tuple tree中,高可靠处理API的接下来部分将向您描述当处理完tuple tree中一个单独的消息时我们该做些什么。这些是通过OutputCollector 的ack和fail方法来实现的。回头看一下例子SplitSentence,可以发现当所有的word消息被发送完成后,输入的表示句子的消息会被应答(acked)。
每个被处理的消息必须表明成功或失败(acked 或者failed)。Storm是使用内存来跟踪每个消息的处理情况的,如果被处理的消息没有应答的话,迟早内存会被耗尽!>
很多bolt遵循特定的处理流程: 读取一个消息、发送它派生出来的子消息、在execute结尾处应答此消息。一般的过滤器(filter)或者是简单的处理功能都是这类的应用。Storm有一个BasicBolt接口封装了上述的流程。示例SplitSentence可以使用BasicBolt来重写:

使用这种方式,代码比之前稍微简单了一些,但是实现的功能是一样的。发送到BasicOutputCollector的消息会被自动的锚定到输入消息,并且,当execute执行完毕的时候,会自动的应答输入消息。
很多情况下,一个消息需要延迟应答,例如聚合或者是join。只有根据一组输入消息得到一个结果之后,才会应答之前所有的输入消息。并且聚合和join大部分时候对输出消息都是多重锚定。然而,这些特性不是IBasicBolt所能处理的。
4.5 高效的实现tuple tree
Storm 系统中有一组叫做“acker”的特殊的任务,它们负责跟踪DAG(有向无环图)中的每个消息。每当发现一个DAG被完全处理,它就向创建这个根消息的spout任务发送一个信号。拓扑中acker任务的并行度可以通过配置参数Config.TOPOLOGY_ACKERS来设置。默认的acker任务并行度为1,当系统中有大量的消息时,应该适当提高acker任务的并发度。
为了理解Storm可靠性处理机制,我们从研究一个消息的生命周期和tuple tree的管理入手。当一个消息被创建的时候(无论是在spout还是bolt中),系统都为该消息分配一个64bit的随机值作为id。这些随机的id是acker用来跟踪由spout消息派生出来的tuple tree的。
每个消息都知道它所在的tuple tree对应的根消息的id。每当bolt新生成一个消息,对应tuple tree中的根消息的messageId就拷贝到这个消息中。当这个消息被应答的时候,它就把关于tuple tree变化的信息发送给跟踪这棵树的acker。例如,他会告诉acker:本消息已经处理完毕,但是我派生出了一些新的消息,帮忙跟踪一下吧。
举个例子,假设消息D和E是由消息C派生出来的,这里演示了消息C被应答时,tuple tree是如何变化的。

因为在C被从树中移除的同时D和E会被加入到tuple tree中,因此tuple tree不会被过早的认为已完全处理。
关于Storm如何跟踪tuple tree,我们再深入的探讨一下。前面说过系统中可以有任意个数的acker,那么,每当一个消息被创建或应答的时候,它怎么知道应该通知哪个acker呢?
系统使用一种哈希算法来根据spout消息的messageId确定由哪个acker跟踪此消息派生出来的tuple tree。因为每个消息都知道与之对应的根消息的messageId,因此它知道应该与哪个acker通信。
当spout发送一个消息的时候,它就通知对应的acker一个新的根消息产生了,这时acker就会创建一个新的tuple tree。当acker发现这棵树被完全处理之后,他就会通知对应的spout任务。
tuple是如何被跟踪的呢?系统中有成千上万的消息,如果为每个spout发送的消息都构建一棵树的话,很快内存就会耗尽。所以,必须采用不同的策略来跟踪每个消息。由于使用了新的跟踪算法,Storm只需要固定的内存(大约20字节)就可以跟踪一棵树。这个算法是storm正确运行的核心,也是storm最大的突破。
acker任务保存了spout消息id到一对值的映射。第一个值就是spout的任务id,通过这个id,acker就知道消息处理完成时该通知哪个spout任务。第二个值是一个64bit的数字,我们称之为“ack val”, 它是树中所有消息的随机id的异或结果。ack val表示了整棵树的的状态,无论这棵树多大,只需要这个固定大小的数字就可以跟踪整棵树。当消息被创建和被应答的时候都会有相同的消息id发送过来做异或。
每当acker发现一棵树的ack val值为0的时候,它就知道这棵树已经被完全处理了。因为消息的随机ID是一个64bit的值,因此ack val在树处理完之前被置为0的概率非常小。假设你每秒钟发送一万个消息,从概率上说,至少需要50,000,000年才会有机会发生一次错误。即使如此,也只有在这个消息确实处理失败的情况下才会有数据的丢失!
4.6 选择合适的可靠性级别
Acker任务是轻量级的,所以在拓扑中并不需要太多的acker存在。可以通过Storm UI来观察acker任务的吞吐量,如果看上去吞吐量不够的话,说明需要添加额外的acker。
如果你并不要求每个消息必须被处理(你允许在处理过程中丢失一些信息),那么可以关闭消息的可靠处理机制,从而可以获取较好的性能。关闭消息的可靠处理机制意味着系统中的消息数会减半(每个消息不需要应答了)。另外,关闭消息的可靠处理可以减少消息的大小(不需要每个tuple记录它的根id了),从而节省带宽。
有三种方法可以关系消息的可靠处理机制:
- 将参数Config.TOPOLOGY_ACKERS设置为0,通过此方法,当Spout发送一个消息的时候,它的ack方法将立刻被调用;
- 第二个方法是Spout发送一个消息时,不指定此消息的messageID。当需要关闭特定消息可靠性的时候,可以使用此方法;
- 最后,如果你不在意某个消息派生出来的子孙消息的可靠性,则此消息派生出来的子消息在发送时不要做锚定,即在emit方法中不指定输入消息。因为这些子孙消息没有被锚定在任何tuple tree中,因此他们的失败不会引起任何spout重新发送消息。
4.7 集群的各级容错
到现在为止,大家已经理解了Storm的可靠性机制,并且知道了如何选择不同的可靠性级别来满足需求。接下来我们研究一下Storm如何保证在各种情况下确保数据不丢失。
3.7.1 任务级失败
- 因为bolt任务crash引起的消息未被应答。此时,acker中所有与此bolt任务关联的消息都会因为超时而失败,对应spout的fail方法将被调用。
- acker任务失败。如果acker任务本身失败了,它在失败之前持有的所有消息都将会因为超时而失败。Spout的fail方法将被调用。
- Spout任务失败。这种情况下,Spout任务对接的外部设备(如MQ)负责消息的完整性。例如当客户端异常的情况下,kestrel队列会将处于pending状态的所有的消息重新放回到队列中。
4.7.2 任务槽(slot) 故障
- worker失败。每个worker中包含数个bolt(或spout)任务。supervisor负责监控这些任务,当worker失败后,supervisor会尝试在本机重启它。
- supervisor失败。supervisor是无状态的,因此supervisor的失败不会影响当前正在运行的任务,只要及时的将它重新启动即可。supervisor不是自举的,需要外部监控来及时重启。
- nimbus失败。nimbus是无状态的,因此nimbus的失败不会影响当前正在运行的任务(nimbus失败时,无法提交新的任务),只要及时的将它重新启动即可。nimbus不是自举的,需要外部监控来及时重启。
4.7.3. 集群节点(机器)故障
- storm集群中的节点故障。此时nimbus会将此机器上所有正在运行的任务转移到其他可用的机器上运行。
- zookeeper集群中的节点故障。zookeeper保证少于半数的机器宕机仍可正常运行,及时修复故障机器即可。
4.8 小结
本章介绍了storm集群如何实现数据的可靠处理。借助于创新性的tuple tree跟踪技术,storm高效的通过数据的应答机制来保证数据不丢失。
storm集群中除nimbus外,没有单点存在,任何节点都可以出故障而保证数据不会丢失。nimbus被设计为无状态的,只要可以及时重启,就不会影响正在运行的任务。