基于Mahout的电影推荐系统
目录(?)[+]
源代码下载地址:http://download.csdn.net/detail/huhui_bj/5248056
1 Mahout介绍
Apache Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。经典算法包括聚类、分类、协同过滤、进化编程等等,并且,在 Mahout 中还加入了对Apache Hadoop的支持,使这些算法可以更高效的运行在云计算环境中。
2 环境部署
- Ubuntu
- JDK1.6.0_21
- MySQL
- apache-tomcat-6.0.35
- mahout-0.3
- MyEclipse 8.0
2.1 JDK1.6.0_21的安装
jdk的下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html我所用的版本是jdk-6u21-linux-i586.bin。安装步骤:
1.打开终端,进入放置jdk安装文件的目录cd /home/huhui/develop
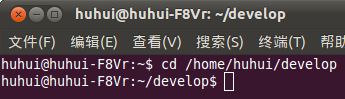
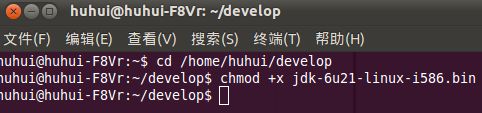
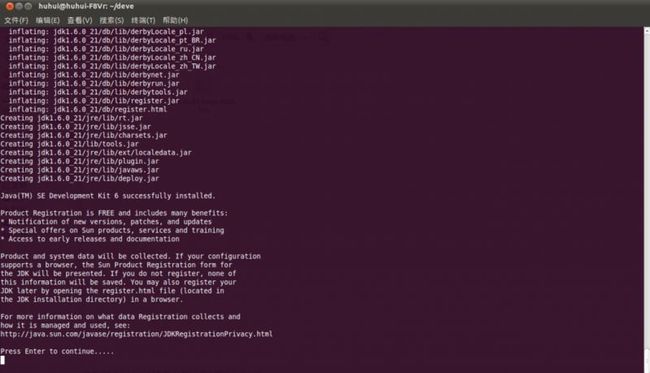
JDK自动安装到/home/huhui/develop/jdk1.6.0_21目录下。这个目录下,在终端输入java -version可以看到jdk的版本信息:

4.安装完JDK之后,接下来需要配置环境变量,在终端中输入命令sudo gedit /etc/profile,此时会弹出如下对话框:
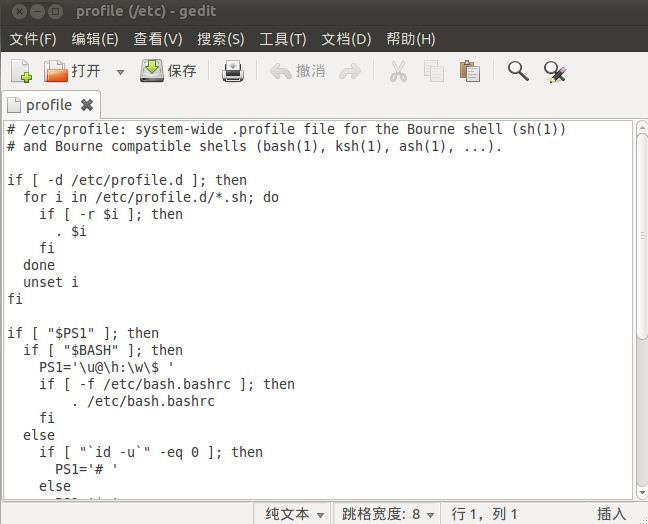
#set java environment
JAVA_HOME=/home/huhui/develop/jdk1.6.0_21
export JRE_HOME=/home/huhui/develop/jdk1.6.0_21/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
保存并关闭文件,至此,jdk的安装与配置就完成了。
2.2 MySQL的安装
MySQL的安装过程比较简单,在终端输入sudo apt-get install mysql-server my-client即可:
到这里,要求用户输入Y或者N,此时选择Y,会弹出一个界面,要求输入mysql的root的密码,这里一定输入,省得安装后再设密码了。
2.3 Tomcat的安装
软件下载地址:http://archive.apache.org/dist/tomcat/tomcat-6/ 我下载的版本是apache-tomcat-6.0.35.tar.gz1.解压文件
复制安装文件到hom/huhui/develop目录下,在终端输入sudo tar -zxvf apache-tomcat-6.0.35.tar.gz,将安装包解压至apache-tomcat-6.0.35目录下
2.配置startup.sh文件
在终端输入sudo gedit home/huhui/develop/apache-tomcat-6.0.35/bin/startup.sh
在startup.sh文件的末尾加入一下内容,加入的内容即为jdk的环境变量:
JAVA_HOME=/home/huhui/develop/jdk1.6.0_21
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
TOMCAT_HOME=/home/huhui/develop/apache-tomcat-6.0.35
3.启动tomcat
进入/usr/local/apache-tomcat-6.0.35/bin/目录,输入sudo ./startup.sh,若出现下图信息,则说明tomcat安装成功。
2.4 Mahout安装
1.Mahout可以从http://mirror.bit.edu.cn/apache/mahout/下载,我下载的版本是mahout-0.3.tar.gz2.将下载下来的压缩文件解压缩,将lib文件夹下的jar文件全部拷贝出,为以后的工作做准备。doc目录下的mahout-core文件夹下是mahout的API,供开发时查阅。
2.5 MyEclipse8.0安装
MyEclipse的安装简单,基本和windows下安装一样,此处不再赘述。MyEclipse安装完成之后,将前面安装好的tomcat关联到MyEclipse下。至此,已经完成了对环境的部署,下面进入开发阶段。
3 工程开发
3.1 推荐引擎简介
推荐引擎利用特殊的信息过滤(IF,Information Filtering)技术,将不同的内容(例如电影、音乐、书籍、新闻、图片、网页等)推荐给可能感兴趣的用户。通常情况下,推荐引擎的实现是通过将用户的个人喜好与特定的参考特征进行比较,并试图预测用户对一些未评分项目的喜好程度。参考特征的选取可能是从项目本身的信息中提取的,或是基于用户所在的社会或社团环境。根据如何抽取参考特征,我们可以将推荐引擎分为以下四大类:
• 基于内容的推荐引擎:它将计算得到并推荐给用户一些与该用户已选择过的项目相似的内容。例如,当你在网上购书时,你总是购买与历史相关的书籍,那么基于内容的推荐引擎就会给你推荐一些热门的历史方面的书籍。
• 基于协同过滤的推荐引擎:它将推荐给用户一些与该用户品味相似的其他用户喜欢的内容。例如,当你在网上买衣服时,基于协同过滤的推荐引擎会根据你的历史购买记录或是浏览记录,分析出你的穿衣品位,并找到与你品味相似的一些用户,将他们浏览和购买的衣服推荐给你。
• 基于关联规则的推荐引擎:它将推荐给用户一些采用关联规则发现算法计算出的内容。关联规则的发现算法有很多,如 Apriori、AprioriTid、DHP、FP-tree 等。
• 混合推荐引擎:结合以上各种,得到一个更加全面的推荐效果。
3.2 Taste简介
Taste 是 Apache Mahout 提供的一个协同过滤算法的高效实现,它是一个基于 Java 实现的可扩展的,高效的推荐引擎。Taste 既实现了最基本的基于用户的和基于内容的推荐算法,同时也提供了扩展接口,使用户可以方便的定义和实现自己的推荐算法。同时,Taste 不仅仅只适用于 Java 应用程序,它可以作为内部服务器的一个组件以 HTTP 和 Web Service 的形式向外界提供推荐的逻辑。
3.3 Taste工作原理
Taste 由以下五个主要的组件组成:- DataModel:DataModel 是用户喜好信息的抽象接口,它的具体实现支持从任意类型的数据源抽取用户喜好信息。Taste 默认提供 JDBCDataModel 和 FileDataModel,分别支持从数据库和文件中读取用户的喜好信息。
- UserSimilarity 和 ItemSimilarity:UserSimilarity 用于定义两个用户间的相似度,它是基于协同过滤的推荐引擎的核心部分,可以用来计算用户的“邻居”,这里我们将与当前用户口味相似的用户称为他的邻居。ItemSimilarity 类似的,计算内容之间的相似度。
- UserNeighborhood:用于基于用户相似度的推荐方法中,推荐的内容是基于找到与当前用户喜好相似的“邻居用户”的方式产生的。UserNeighborhood 定义了确定邻居用户的方法,具体实现一般是基于 UserSimilarity 计算得到的。
- Recommender:Recommender 是推荐引擎的抽象接口,Taste 中的核心组件。程序中,为它提供一个 DataModel,它可以计算出对不同用户的推荐内容。实际应用中,主要使用它的实现类 GenericUserBasedRecommender 或者 GenericItemBasedRecommender,分别实现基于用户相似度的推荐引擎或者基于内容的推荐引擎。
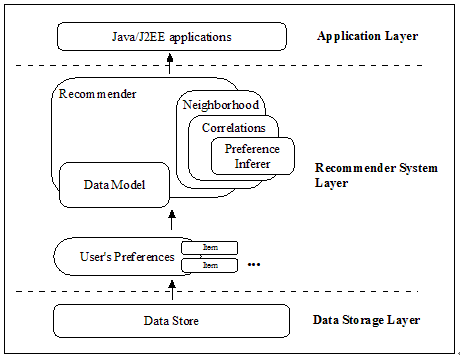
图1 Taste的主要组件图
3.4 基于Taste构建电影推荐引擎
3.4.1 数据下载
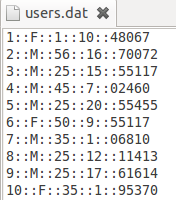
本工程所用到的数据来源于此处: http://www.grouplens.org/node/12,下载数据“MovieLens 1M - Consists of 1 million ratings from 6000 users on 4000 movies.”这个数据文件夹下有三个文件:movies.dat,ratings.dat和users.dat,数据形式如下三个图所示:
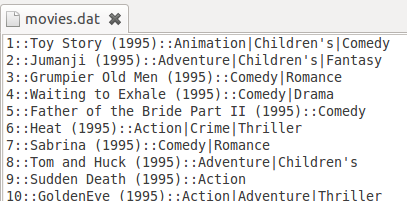
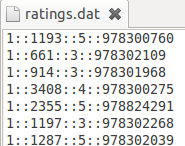
ratings.dat的文件描述是 用户编号::电影编号::电影评分::时间戳
users.dat的文件描述是 用户编号::性别::年龄::职业::Zip-code
这些文件包含来自6040个MovieLens用户在2000年对约3900部电影的1000209个匿名评分信息。
3.4.2 构造数据库
构建推荐引擎,可以直接使用movie.dat文件作为数据源,也可以使用数据库中的数据作为数据源,本实验中,这两种方式都实现了,所以下面介绍利用dat文件建立数据库。构建数据库的SQL语句如下:
- CREATE DATABASE movie;
- USE movie;
- CREATE TABLE movies ( // 保存电影相关的信息。
- id INTEGER NOT NULL AUTO_INCREMENT,
- name varchar(100) NOT NULL,
- published_year varchar(4) default NULL,
- type varchar(100) default NULL,
- PRIMARY KEY (id)
- );
- CREATE TABLE movie_preferences ( // 保存用户对电影的评分,即喜好程度
- userID INTEGER NOT NULL,
- movieID INTEGER NOT NULL,
- preference INTEGER NOT NULL DEFAULT 0,
- timestamp INTEGER not null default 0,
- FOREIGN KEY (movieID) REFERENCES movies(id) ON DELETE CASCADE
- );
•Movie Reference:表示某个用户对某个电影的喜好程度,包含用户编号、电影编号、用户的评分以及评分的时间。
至于如何将dat文件中的内容导入到MySQL数据库中,分别由本工程目录文件下的ImportMovies.java和ImportRatings.java文件实现。
MySQL数据库中的数据如下图:
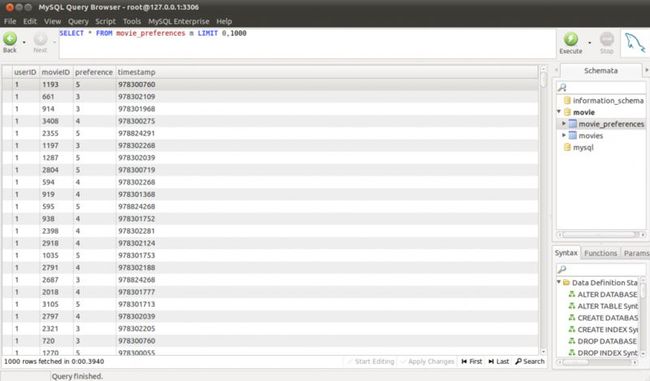
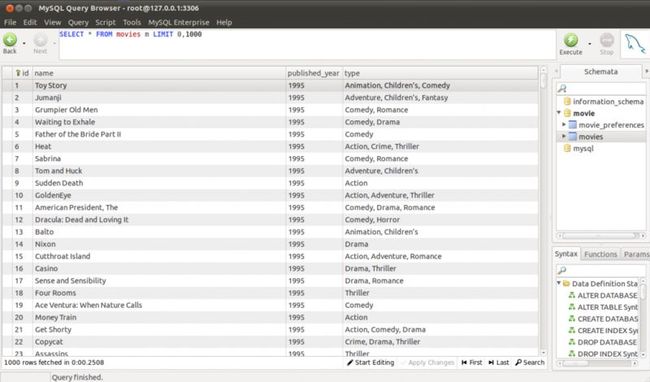
图三 movies表记录
3.4.3 推荐引擎实现
在本工程中,我实现了三种方式的推荐引擎:基于用户相似度的推荐引擎,基于内容相似度的推荐引擎,以及基于Slope One 的推荐引擎。在这些推荐引擎中,我分别使用了三种DataModel,即Database-based DataModel,File-based DataModel和In-memory DataModel。a) 基于用户相似度的推荐引擎
- public class MyUserBasedRecommender {
- public List<RecommendedItem> userBasedRecommender(long userID,int size) {
- // step:1 构建模型 2 计算相似度 3 查找k紧邻 4 构造推荐引擎
- List<RecommendedItem> recommendations = null;
- try {
- DataModel model = MyDataModel.myDataModel();//构造数据模型,Database-based
- UserSimilarity similarity = new PearsonCorrelationSimilarity(model);//用PearsonCorrelation 算法计算用户相似度
- UserNeighborhood neighborhood = new NearestNUserNeighborhood(3, similarity, model);//计算用户的“邻居”,这里将与该用户最近距离为 3 的用户设置为该用户的“邻居”。
- Recommender recommender = new CachingRecommender(new GenericUserBasedRecommender(model, neighborhood, similarity));//构造推荐引擎,采用 CachingRecommender 为 RecommendationItem 进行缓存
- recommendations = recommender.recommend(userID, size);//得到推荐的结果,size是推荐接过的数目
- } catch (Exception e) {
- // TODO: handle exception
- e.printStackTrace();
- }
- return recommendations;
- }
- public static void main(String args[]) throws Exception {
- }
- }
在这个推荐引擎中,由于使用的是MySQLJDBCDataModel和JNDI,所以需要在tomcat的server.xml文件中添加如下信息:
- <Context path="/MyRecommender" docBase="/home/huhui/develop/apache-tomcat-6.0.35/webapps/MyRecommender" debug="0" reloadable="true">
- <Resource name="jdbc/movie" auth="Container" type="javax.sql.DataSource"
- username="root"
- password="***"
- driverClassName="com.mysql.jdbc.Driver"
- url="jdbc:mysql://localhost:3306/movie"
- maxActive="15"
- maxIdle="7"
- defaultTransactionIsolation="READ_COMMITTED"
- validationQuery="Select 1" />
- </Context>
Mahout 中提供了基本的相似度的计算,它们都实现了 UserSimilarity 这个接口,以实现用户相似度的计算,包括下面这些常用的:
•PearsonCorrelationSimilarity:基于皮尔逊相关系数计算相似度 (它表示两个数列对应数字一起增大或一起减小的可能性。是两个序列协方差与二者方差乘积的比值)
•EuclideanDistanceSimilarity:基于欧几里德距离计算相似度
•TanimotoCoefficientSimilarity:基于 Tanimoto 系数计算相似度
根据建立的相似度计算方法,找到邻居用户。这里找邻居用户的方法根据前面我们介绍的,也包括两种:“固定数量的邻居”和“相似度门槛邻居”计算方法,Mahout 提供对应的实现:
•NearestNUserNeighborhood:对每个用户取固定数量 N 的最近邻居
•ThresholdUserNeighborhood:对每个用户基于一定的限制,取落在相似度门限内的所有用户为邻居。
基于 DataModel,UserNeighborhood 和 UserSimilarity 构建 GenericUserBasedRecommender,从而实现基于用户的推荐策略。
b) 基于内容相似度的推荐引擎
理解了基于用户相似读的推荐引擎,基于内容相似读的推荐引擎类似,甚至更加简单。
- public class MyItemBasedRecommender {
- public List<RecommendedItem> myItemBasedRecommender(long userID,int size){
- List<RecommendedItem> recommendations = null;
- try {
- DataModel model = new FileDataModel(new File("/home/huhui/movie_preferences.txt"));//构造数据模型,File-based
- ItemSimilarity similarity = new PearsonCorrelationSimilarity(model);//计算内容相似度
- Recommender recommender = new GenericItemBasedRecommender(model, similarity);//构造推荐引擎
- recommendations = recommender.recommend(userID, size);//得到推荐接过
- } catch (Exception e) {
- // TODO: handle exception
- e.printStackTrace();
- }
- return recommendations;
- }
- }
在这个推荐引擎中,使用的是File-based Datamodel,数据文件格式如下图所示:
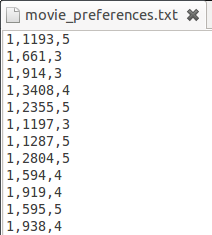
每一行都是一个简单的三元组< 用户 ID, 物品 ID, 用户偏好 >。
基于用户和基于内容是最常用最容易理解的两种推荐策略,但在大数据量时,它们的计算量会很大,从而导致推荐效率较差。因此 Mahout 还提供了一种更加轻量级的 CF 推荐策略:Slope One。
Slope One 是有 Daniel Lemire 和 Anna Maclachlan 在 2005 年提出的一种对基于评分的协同过滤推荐引擎的改进方法,下面简单介绍一下它的基本思想。
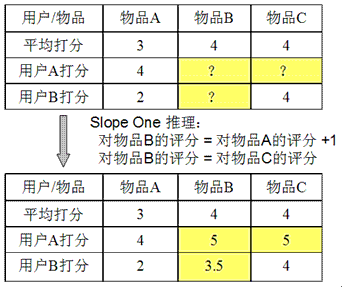
假设系统对于物品 A,物品 B 和物品 C 的平均评分分别是 3,4 和 4。基于 Slope One 的方法会得到以下规律:
•用户对物品 B 的评分 = 用户对物品 A 的评分 + 1
•用户对物品 B 的评分 = 用户对物品 C 的评分
基于以上的规律,我们可以对用户 A 和用户 B 的打分进行预测:
•对用户 A,他给物品 A 打分 4,那么我们可以推测他对物品 B 的评分是 5,对物品 C 的打分也是 5。
•对用户 B,他给物品 A 打分 2,给物品 C 打分 4,根据第一条规律,我们可以推断他对物品 B 的评分是 3;而根据第二条规律,推断出评分是 4。当出现冲突时,我们可以对各种规则得到的推断进行就平均,所以给出的推断是 3.5。
这就是 Slope One 推荐的基本原理,它将用户的评分之间的关系看作简单的线性关系:
Y = mX + b;
当 m = 1 时就是 Slope One,也就是我们刚刚展示的例子。
- public class MySlopeOneRecommender {
- public List<RecommendedItem> mySlopeOneRecommender(long userID,int size){
- List<RecommendedItem> recommendations = null;
- try {
- DataModel model = new FileDataModel(new File("/home/huhui/movie_preferences.txt"));//构造数据模型
- Recommender recommender = new CachingRecommender(new SlopeOneRecommender(model));//构造推荐引擎
- recommendations = recommender.recommend(userID, size);//得到推荐结果
- } catch (Exception e) {
- // TODO: handle exception
- e.printStackTrace();
- }
- return recommendations;
- }
- }
d) 对数据模型的优化——In-memory DataModel
上面所叙述的三种推荐引擎,输入的都是用户的历史偏好信息,在 Mahout 里它被建模为 Preference(接口),一个 Preference 就是一个简单的三元组 < 用户 ID, 物品 ID, 用户偏好 >,它的实现类是 GenericPreference,可以通过以下语句创建一个 GenericPreference:
- GenericPreference preference = new GenericPreference(1, 101, 4.0f);
- FastByIDMap<PreferenceArray> preferences = new FastByIDMap<PreferenceArray>();
- PreferenceArray prefsForUser1 = new GenericUserPreferenceArray(3);// 注意这里的数字
- // 这里是用来存储一个用户的元数据,这些元数据通常来自日志文件,比如浏览历史,等等,不同的业务场合,它的业务语义是不一样
- prefsForUser1.setUserID(0, 1);
- prefsForUser1.setItemID(0, 101);
- prefsForUser1.setValue(0, 5.0f);//<1, 101, 5.0f> < 用户 ID, 物品 ID, 用户偏好 >
- prefsForUser1.setItemID(1, 102);
- prefsForUser1.setValue(1, 3.0f);//<1, 102, 3.0f>
- prefsForUser1.setItemID(2, 103);
- prefsForUser1.setValue(2, 2.5f);//<1, 103, 2.5f>
- preferences.put(1l, prefsForUser1);// 在这里添加数据,userID作为key
- ........
由于代码比较长,此处就不全部贴出来,详见工程文件中的RecommenderIntro.java文件。
4 程序演示
这个项目工程是B/S模式的,基于MVC开发模式开发的,开发环境是Ubuntu,IDE是MyEclipse8.0,工程文件目录如下图: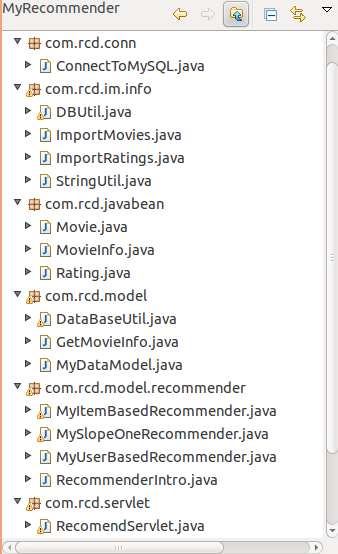
图四 工程文件目录
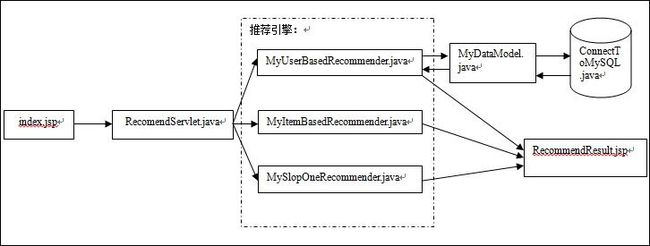
主要类文件之间的关系
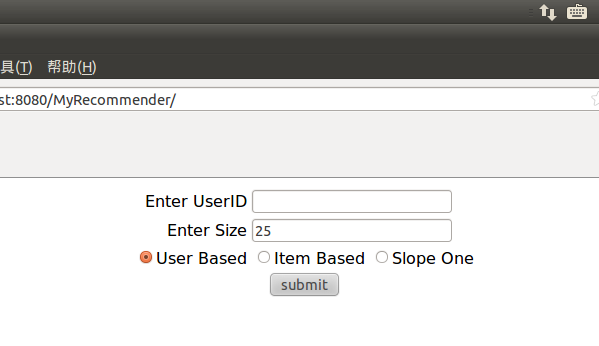
项目首页提供三个输入:用户id,推荐电影的数目(默认为25),推荐策略。
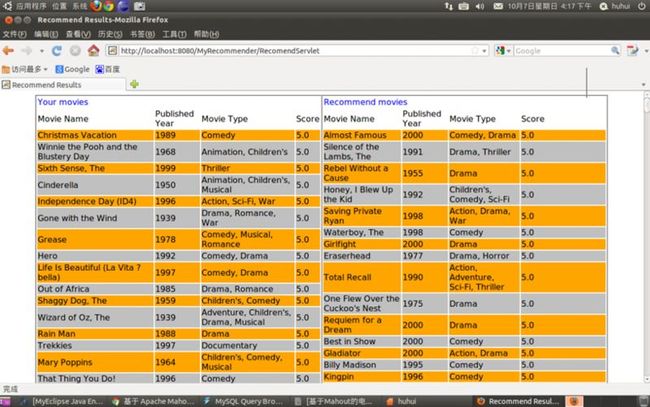
图七 编号为10的用户,基于内容相似度的推荐结果
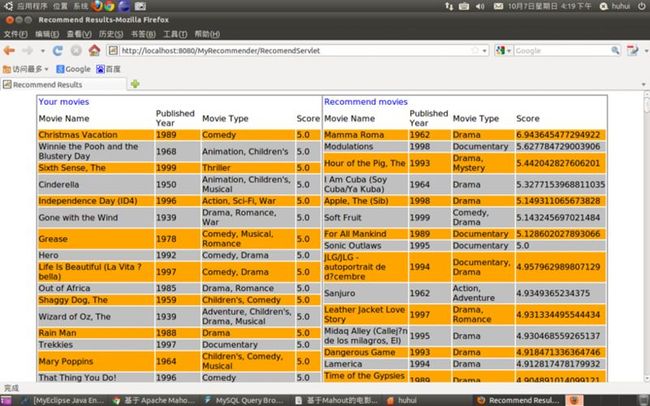
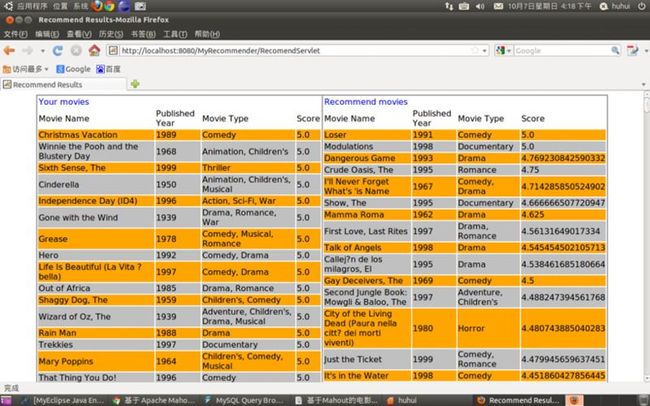
图八 编号为10的用户,基于SlopOne的推荐结果