C++ 内存管理分析
C++ 内存管理分析:
1.memcache
memcache是一套分布式的高速缓存系统,由LiveJournal的Brad Fitzpatrick开发,但目前被许多网站使用
以提升网站的访问速度,尤其对于一些大型的、需要频繁访问数据库的网站访问速度提升效果十分显著[1] 。这是一套开放源代码软件,以BSD license授权发布。
MemCache的工作流程如下:先检查客户端的请求数据是否在memcached中,如有,直接把请求数据返回,不再对数据库进行任何操作;如果请求的数据不在memcached中,就去查数据库,把从数据库中获取的数据返回给客户端,同时把数据缓存一份到memcached中(memcached客户端不负责,需要程序明确实现);每次更新数据库的同时更新memcached中的数据,保证一致性;当分配给memcached内存空间用完之后,会使用LRU(Least Recently Used,最近最少使用)策略加上到期失效策略,失效数据首先被替换,然后再替换掉最近未使用的数据。
Memcahce不适合缓存大数据,超过1MB的数据,可以考虑在客户端压缩或拆分到多个key中。大的数据在进行load和uppack到内存的时候需要花很长时间,从而降低服务器的性能。最新的memchche 会自动压缩,100M的数据可以压缩至100k,所以解决了这个问题。
memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题.
简单的分析组织了一下memcached的知识点,主要是为了引入slab Allocator 对象缓存分配机制,在介绍这个机制前,我们先分析一下malloc 和 free ,以及 new 与 delete这几个函数的性能
2. malloc 与 free 的性能对比:
malloc函数的实质体现在,它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表。调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块。然后,将该内存块一分为二(一块的大小与用户请求的大小相等,另一块的大小就是剩下的字节)。接下来,将分配给用户的那块内存传给用户,并将剩下的那块(如果有的话)返回到连接表上。调用free函数时,它将用户释放的内存块连接到空闲链上。到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。于是,malloc函数请求延时,并开始在空闲链上翻箱倒柜地检查各内存片段,对它们进行整理,将相邻的小空闲块合并成较大的内存块。
malloc() 的实现有很多,这些实现各有优点与缺点。在设计一个分配程序时,要面临许多需要折衷的选择,其中包括:
分配的速度。
回收的速度。
有线程的环境的行为。
内存将要被用光时的行为。
局部缓存。
簿记(Bookkeeping)内存开销。
虚拟内存环境中的行为。
小的或者大的对象。
实时保证。
每一个实现都有其自身的优缺点集合。在我们的简单的分配程序中,分配非常慢,而回收非常快。另外,由于它在使用虚拟内存系统方面较差,所以它最适于处理大的对象。
最关键的问题:
多次调用malloc()后空闲内存被切成很多的小内存片段,这就使得用户在申请内存使用时,由于找不到足够大的内存空间,malloc ()需要进行内存整理,使得函数的性能越来越低。聪明的程序员通过总是分配大小为2的幂的内存块,而最大限度地降低潜在的malloc性能丧失。也就是说,所分配的内存块大小为4字节、8字节、16字节、18446744073709551616字节,等等。这样做最大限度地减少了进入空闲链的怪异片段(各种尺寸的小片段都有)的数量。尽管看起来这好像浪费了空间,但也容易看出浪费的空间永远不会超过50%。
delete 性能消耗与malloc相比比较小,这里不讨论
3. new 与 delete 性能对比:
new是C++中引入的概念,其中
Memory Pool的设计哲学和无痛运用
2.Memcached 内存管理
http://shaomeng95.iteye.com/blog/1142015
Memcached是一个高效的分布式内存cache,了解memcached的内存管理机制,便于我们理解memcached,让我们可以针对我们数据特点进行调优,让其更好的为我所用。这里简单谈一下我对 memcached的内存管理的一些认识,在没有特别注明的情况下,这里谈到的memcached是1.2版本,1.1和1.2版本有一些差异。
基本概念:Slab和chunk
在Memcached内存结构中有两个非常重要的概念:slab 和 chunk,我们先从下图中对这两个概念有一个感性的认识:
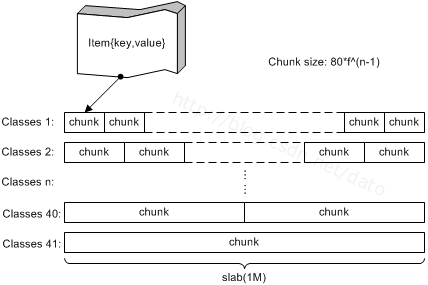
图 1 memcached内存结构
Slab是一个内存块,它是memcached一次申请内存的最小单位。在启动memcached的时候一般会使用参数-m指定其可用内存,但是并不是在启动的那一刻所有的内存就全部分配出去了,只有在需要的时候才会去申请,而且每次申请一定是一个slab。Slab的大小固定为1M(1048576 Byte),一个slab由若干个大小相等的chunk组成。每个chunk中都保存了一个item结构体、一对key和value。
虽然在同一个slab中chunk的大小相等的,但是在不同的slab中chunk的大小并不一定相等,在memcached中按照chunk的大小不同,可以把slab分为很多种类(class)。在启动memcached的时候可以通过-vv来查看slab的种类:
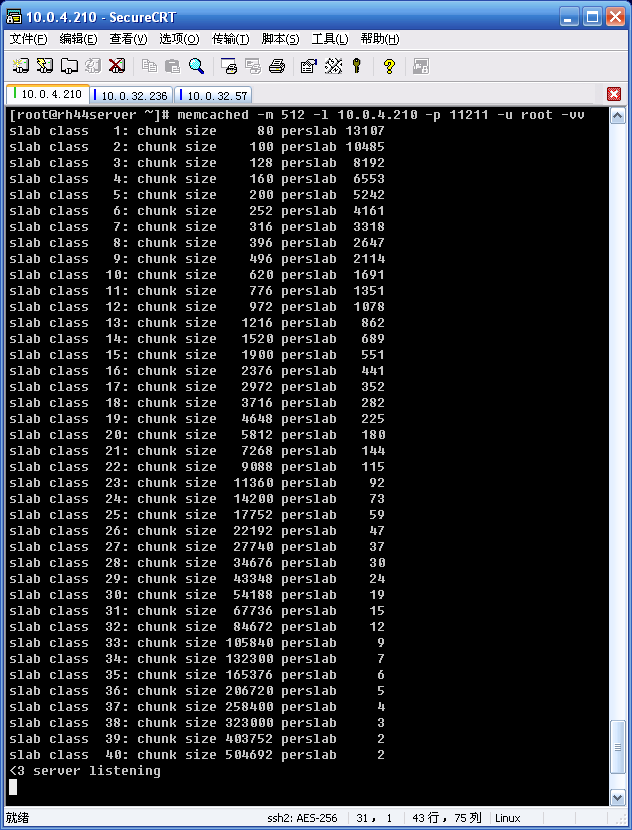
图2 slab分组信息
从上图可以看到,默认情况下memcached把slab分为40类(class1~class40),在class 1中,chunk的大小为80字节,由于一个slab的大小是固定的1048576字节(1M),因此在class1中最多可以有13107个chunk:
13107×80 + 16 = 1048576
在class1中,剩余的16字节因为不够一个chunk的大小(80byte),因此会被浪费掉。每类chunk的大小有一定的计算公式的,假定i代表分类,class i的计算公式如下:
chunk size(class i) : (default_size+item_size)*f^(i-1)+ CHUNK_ALIGN_BYTES
default_size: 默认大小为48字节,也就是memcached默认的key+value的大小为48字节,可以通过-n参数来调节其大小;
item_size: item结构体的长度,固定为32字节。default_size大小为48字节,item_size为32,因此class1的chunk大小为48+32=80字节;
f为factor,是chunk变化大小的因素,默认值为1.25,调节f可以影响chunk的步进大小,在启动时可以使用-f来指定;
CHUNK_ALIGN_BYTES是一个修正值,用来保证chunk的大小是某个值的整数倍(在32位机器上要求chunk的大小是4的整数倍)。
从上面的分析可以看到,我们实际可以调节的参数有-f、-n,在memcached的实际运行中,我们还需要观察我们的数据特征,合理的调节f,n的值,使我们的内存得到充分的利用减少浪费。
内存申请分配
Memcached内存管理采取预分配、分组管理的方式,分组管理就是我们上面提到的slab class,按照chunk的大小slab被分为很多种类。下面解释一下memcached的内存预分配过程。
向memcached添加一个item时候,memcached首先会根据 item的大小,来选择最合适的slab class:例如item的大小为190字节,默认情况下class 4的chunk大小为160字节显然不合适,class 5的chunk大小为200字节,大于190字节,因此该item将放在class 5中(显然这里会有10字节的浪费是不可避免的),计算好所要放入的chunk之后,memcached会去检查该类大小的chunk还有没有空闲的,如果没有,将会申请1M(1个slab)的空间并划分为该种类chunk。例如我们第一次向memcached中放入一个190字节的item 时,memcached会产生一个slab class 2(也叫一个page),并会用去一个chunk,剩余5241个chunk供下次有适合大小item时使用,当我们用完这所有的5242个chunk之后,下次再有一个在160~200字节之间的item添加进来时,memcached会再次产生一个class 5的slab(这样就存在了2个pages)。查看slab的使用情况,我们可以telnet ip port,然后输入命令 stats slabs即可:
例如:telnet 10.0.4.210 11211
stats slabs STAT 5:chunk_size 200 STAT 5:chunks_per_page 5242 STAT 5:total_pages 1 STAT 5:total_chunks 5242 STAT 5:used_chunks 5242 STAT 5:free_chunks 0 STAT 5:free_chunks_end 5241 STAT active_slabs 1 STAT total_malloced 1048400 |
slab内存分配
http://ju.outofmemory.cn/entry/8014
Memcached在启动时通过-m指定最大使用内存,但是这个不会一启动就占用,是随着需要逐步分配给各slab的。
如果一个新的缓存数据要被存放,memcached首先选择一个合适的slab,然后查看该slab是否还有空闲的chunk,如果有则直接存放进去;如 果没有则要进行申请。slab申请内存时以page为单位,所以在放入第一个数据,无论大小为多少,都会有1M大小的page被分配给该slab。申请到 page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk的数组,在从这个chunk数组中选择一个用于存储 数据。如下图,slab 1和slab 2都分配了一个page,并按各自的大小切分成chunk数组。

Memcached内存分配策略
memcached的内存分配策略就是:按slab需求分配page,各slab按需使用chunk存储。
这里有几个特点要注意,
Memcached分配出去的page不会被回收或者重新分配
Memcached申请的内存不会被释放
slab空闲的chunk不会借给任何其他slab使用
新版本中Page可以调配给其它的Slab,shell> memcached -o slab_reassign,slab_automove
Memcached的LRU机制
为了规避内存碎片问题,Memcached采用了名为SlabAllocator的内存分配机制。内存以Page为单位来分配,每个Page分给一个特定长度的Slab来使用,每个Slab包含若干个特定长度的Chunk。实际保存数据时,会根据数据的大小选择一个最贴切的Slab,并把数据保存在对应的Chunk中。如果某个Slab没有剩余的Chunk了,系统便会给这个Slab分配一个新的Page以供使用,如果没有Page可用,系统就会触发LRU机制,通过删除冷数据来为新数据腾出空间,这里有一点需要注意的是:LRU不是全局的,而是针对Slab而言的。
slab内存结构图:二维数组链表

slab内存分配实例

Item内存分配(chunk中的实际数据)

3.Slab Allocator(对象缓存分配)
http://www.ibm.com/developerworks/cn/linux/l-linux-slab-allocator/
The fundamental idea behind slab allocation technique is based on the observation that some kernel data objects are frequently created and destroyed after they are not needed anymore. This implies that for each allocation of memory for these data objects, some time is spent to find the best fit for that data object. Moreover, deallocation of the memory after destruction of the object contributes to fragmentation of the memory, which burdens the kernel some more to rearrange the memory.Slab 算法的发现是基于内核中内存使用的一些特点:一些需要频繁使用的同样大小数据经常在使用后不久又再次被用到;找到合适大小的内存所消耗的时间远远大于释放内存所需要的时间。所以Slab算法的发明人认为内存对象在使用之后不是立即释放给系统而是将它们用链表之类的数据结构管理起来以备将来使用,频繁分配和释放的内存对象应该用缓存管理起来。Linux的slab分配器就是基于这样的想法实现的,这个算法在空间和时间上都有很高的效率。
动态内存管理
内存管理的目标是提供一种方法,为实现各种目的而在各个用户之间实现内存共享。内存管理方法应该实现以下两个功能:
最小化管理内存所需的时间
最大化用于一般应用的可用内存(最小化管理开销)
内存管理实际上是一种关于权衡的零和游戏。您可以开发一种使用少量内存进行管理的算法,但是要花费更多时间来管理可用内存。也可以开发一个算法来有效地管理内存,但却要使用更多的内存。最终,特定应用程序的需求将促使对这种权衡作出选择。
每个内存管理器都使用了一种基于堆的分配策略。在这种方法中,大块内存(称为 堆)用来为用户定义的目的提供内存。当用户需要一块内存时,就请求给自己分配一定大小的内存。堆管理器会查看可用内存的情况(使用特定算法)并返回一块内存。搜索过程中使用的一些算法有first-fit(在堆中搜索到的第一个满足请求的内存块 )和 best-fit(使用堆中满足请求的最合适的内存块)。当用户使用完内存后,就将内存返回给堆。
这种基于堆的分配策略的根本问题是碎片(fragmentation)。当内存块被分配后,它们会以不同的顺序在不同的时间返回。这样会在堆中留下一些洞,需要花一些时间才能有效地管理空闲内存。这种算法通常具有较高的内存使用效率(分配需要的内存),但是却需要花费更多时间来对堆进行管理。
另外一种方法称为 buddy memory allocation,是一种更快的内存分配技术,它将内存划分为 2 的幂次方个分区,并使用 best-fit 方法来分配内存请求。当用户释放内存时,就会检查 buddy 块,查看其相邻的内存块是否也已经被释放。如果是的话,将合并内存块以最小化内存碎片。这个算法的时间效率更高,但是由于使用 best-fit 方法的缘故,会产生内存浪费。
本文将着重介绍 Linux 内核的内存管理,尤其是 slab 分配提供的机制。
slab 缓存
Linux 所使用的 slab 分配器的基础是 Jeff Bonwick 为 SunOS 操作系统首次引入的一种算法。Jeff 的分配器是围绕对象缓存进行的。在内核中,会为有限的对象集(例如文件描述符和其他常见结构)分配大量内存。Jeff 发现对内核中普通对象进行初始化所需的时间超过了对其进行分配和释放所需的时间。因此他的结论是不应该将内存释放回一个全局的内存池,而是将内存保持为针对特定目而初始化的状态。例如,如果内存被分配给了一个互斥锁,那么只需在为互斥锁首次分配内存时执行一次互斥锁初始化函数(mutex_init)即可。后续的内存分配不需要执行这个初始化函数,因为从上次释放和调用析构之后,它已经处于所需的状态中了。
Linux slab 分配器使用了这种思想和其他一些思想来构建一个在空间和时间上都具有高效性的内存分配器。
图 1 给出了 slab 结构的高层组织结构。在最高层是 cache_chain,这是一个 slab 缓存的链接列表。这对于 best-fit 算法非常有用,可以用来查找最适合所需要的分配大小的缓存(遍历列表)。cache_chain 的每个元素都是一个 kmem_cache 结构的引用(称为一个 cache)。它定义了一个要管理的给定大小的对象池。
图 1. slab 分配器的主要结构
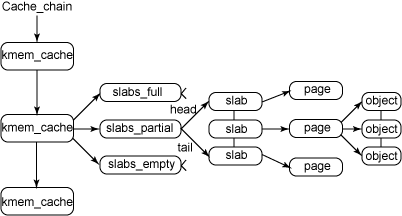
每个缓存都包含了一个 slabs 列表,这是一段连续的内存块(通常都是页面)。存在 3 种 slab:
slabs_full完全分配的 slab
slabs_partial部分分配的 slab
slabs_empty空 slab,或者没有对象被分配
注意 slabs_empty 列表中的 slab 是进行回收(reaping)的主要备选对象。正是通过此过程,slab 所使用的内存被返回给操作系统供其他用户使用。
slab 列表中的每个 slab 都是一个连续的内存块(一个或多个连续页),它们被划分成一个个对象。这些对象是从特定缓存中进行分配和释放的基本元素。注意 slab 是 slab 分配器进行操作的最小分配单位,因此如果需要对 slab 进行扩展,这也就是所扩展的最小值。通常来说,每个 slab 被分配为多个对象。
由于对象是从 slab 中进行分配和释放的,因此单个 slab 可以在 slab 列表之间进行移动。例如,当一个 slab 中的所有对象都被使用完时,就从slabs_partial 列表中移动到 slabs_full 列表中。当一个 slab 完全被分配并且有对象被释放后,就从 slabs_full 列表中移动到slabs_partial 列表中。当所有对象都被释放之后,就从 slabs_partial 列表移动到 slabs_empty 列表中。
slab 背后的动机
与传统的内存管理模式相比, slab 缓存分配器提供了很多优点。首先,内核通常依赖于对小对象的分配,它们会在系统生命周期内进行无数次分配。slab 缓存分配器通过对类似大小的对象进行缓存而提供这种功能,从而避免了常见的碎片问题。slab 分配器还支持通用对象的初始化,从而避免了为同一目而对一个对象重复进行初始化。最后,slab 分配器还可以支持硬件缓存对齐和着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能。