ConcurrentHashMap深入分析
Map体系
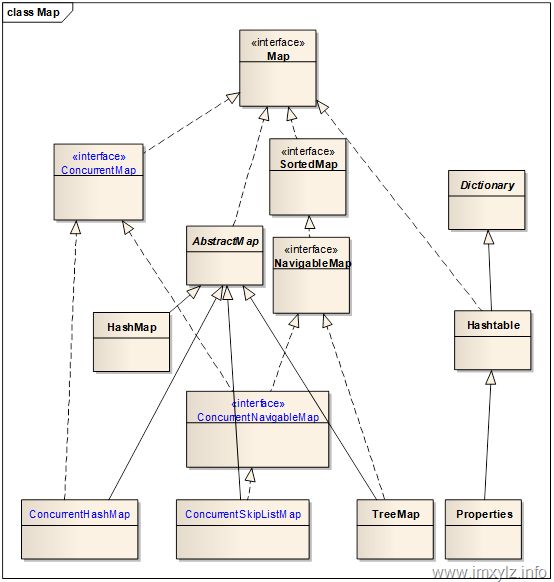
Hashtable是JDK 5之前Map唯一线程安全的内置实现(Collections.synchronizedMap不算)。Hashtable继承的是Dictionary(Hashtable是其唯一公开的子类),并不继承AbstractMap或者HashMap.尽管Hashtable和HashMap的结构非常类似,但是他们之间并没有多大联系。
ConcurrentHashMap是HashMap的线程安全版本,ConcurrentSkipListMap是TreeMap的线程安全版本。
最终可用的线程安全版本Map实现是ConcurrentHashMap、ConcurrentSkipListMap、Hashtable、Properties四个,但是Hashtable是过时的类库,因此如果可以的应该尽可能的使用ConcurrentHashMap和ConcurrentSkipListMap.
简介
ConcurrentHashMap 是 java.util.concurrent 包的重要成员。本文将结合 Java 内存模型,分析 JDK 源代码,探索 ConcurrentHashMap 高并发的具体实现机制。
由于 ConcurrentHashMap 的源代码实现依赖于 Java 内存模型,所以阅读本文需要读者了解 Java 内存模型。同时,ConcurrentHashMap 的源代码会涉及到散列算法和链表数据结构,所以,读者需要对散列算法和基于链表的数据结构有所了解。
Java 内存模型
Java 语言的内存模型由一些规则组成,这些规则确定线程对内存的访问如何排序以及何时可以确保它们对线程是可见的。下面我们将分别介绍 Java 内存模型的重排序,内存可见性和 happens-before 关系。
重排序
内存模型描述了程序的可能行为。具体的编译器实现可以产生任意它喜欢的代码 – 只要所有执行这些代码产生的结果,能够和内存模型预测的结果保持一致。这为编译器实现者提供了很大的自由,包括操作的重排序。
编译器生成指令的次序,可以不同于源代码所暗示的“显然”版本。重排序后的指令,对于优化执行以及成熟的全局寄存器分配算法的使用,都是大有脾益的,它使得程序在计算性能上有了很大的提升。
重排序类型包括:
- 编译器生成指令的次序,可以不同于源代码所暗示的“显然”版本。
- 处理器可以乱序或者并行的执行指令。
- 缓存会改变写入提交到主内存的变量的次序。
内存可见性
由于现代可共享内存的多处理器架构可能导致一个线程无法马上(甚至永远)看到另一个线程操作产生的结果。所以 Java 内存模型规定了 JVM 的一种最小保证:什么时候写入一个变量对其他线程可见。
在现代可共享内存的多处理器体系结构中每个处理器都有自己的缓存,并周期性的与主内存协调一致。假设线程 A 写入一个变量值 V,随后另一个线程 B 读取变量 V 的值,在下列情况下,线程 B 读取的值可能不是线程 A 写入的最新值: - 执行线程 A 的处理器把变量 V 缓存到寄存器中。
- 执行线程 A 的处理器把变量 V 缓存到自己的缓存中,但还没有同步刷新到主内存中去。
- 执行线程 B 的处理器的缓存中有变量 V 的旧值。
Happens-before 关系
happens-before 关系保证:如果线程 A 与线程 B 满足 happens-before 关系,则线程 A 执行动作的结果对于线程 B 是可见的。如果两个操作未按 happens-before 排序,JVM 将可以对他们任意重排序。
下面介绍几个与理解 ConcurrentHashMap 有关的 happens-before 关系法则: - 程序次序法则:如果在程序中,所有动作 A 出现在动作 B 之前,则线程中的每动作 A 都 happens-before 于该线程中的每一个动作 B。
- 监视器锁法则:对一个监视器的解锁 happens-before 于每个后续对同一监视器的加锁。
- Volatile 变量法则:对 Volatile 域的写入操作 happens-before 于每个后续对同一 Volatile 的读操作。
- 传递性:如果 A happens-before 于 B,且 B happens-before C,则 A happens-before C。
ConcurrentHashMap结构分析
通过ConcurrentHashMap的类图来分析ConcurrentHashMap的结构。
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。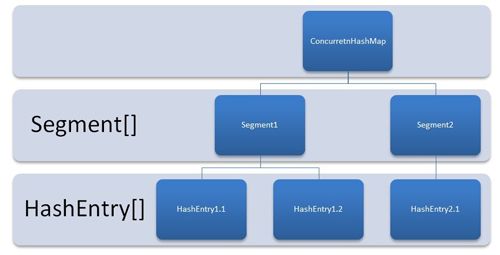
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment.HashEntry 用来封装映射表的键 / 值对;Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。
ConcurrentHashMap原理实现
锁分离 (Lock Stripping)
比如HashTable是一个过时的容器类,通过使用synchronized来保证线程安全,在线程竞争激烈的情况下HashTable的效率非常低下。原因是所有访问HashTable的线程都必须竞争同一把锁。那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。
ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。同样当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。这里"按顺序"是很重要的,否则极有可能出现死锁,在ConcurrentHashMap内部,段数组是final的,并且其成员变量实际上也是final的,但是,仅仅是将数组声明为final的并不保证数组成员也是final的,这需要实现上的保证。这可以确保不会出现死锁,因为获得锁的顺序是固定的。不变性是多线程编程占有很重要的地位,下面还要谈到。
final Segment [] segments;
不变(Immutable)和易变(Volatile)
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。如果使用传统的技术,如HashMap中的实现,如果允许可以在hash链的中间添加或删除元素,读操作不加锁将得到不一致的数据。ConcurrentHashMap实现技术是保证HashEntry几乎是不可变的。HashEntry代表每个hash链中的一个节点,其结构如下所示:
static final class HashEntry<K,V> {
final K key; // 声明 key 为 final 型
final int hash; // 声明 hash 值为 final 型
volatile V value; // 声明 value 为 volatile 型
final HashEntry<K,V> next; // 声明 next 为 final 型
HashEntry(K key, int hash, HashEntry<K,V> next, V value) {
this.key = key;
this.hash = hash;
this.next = next;
this.value = value;
}
}
可以看到除了value不是final的,其它值都是final的,这意味着不能从hash链的中间或尾部添加或删除节点,因为这需要修改next引用值,所有的节点的修改只能从头部开始。对于put操作,可以一律添加到Hash链的头部。但是对于remove操作,可能需要从中间删除一个节点,这就需要将要删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除结点的下一个结点。这在讲解删除操作时还会详述。为了确保读操作能够看到最新的值,将value设置成volatile,这避免了加锁。
ConcurrentHashMap具体实现
ConcurrentHashMap初始化
ConcurrentHashMap初始化方法是通过initialCapacity,loadFactor, concurrencyLevel几个参数来初始化segments数组,段偏移量segmentShift,段掩码segmentMask和每个segment里的HashEntry数组,初始化segments数组。让我们来看一下初始化segmentShift,segmentMask和segments数组的源代码。
http://java.chinaitlab.com/line/914247.html
http://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap
http://www.blogjava.net/DLevin/archive/2013/10/18/405030.html