Log4j性能调优,及原理
问题背景
证券的交易系统,整个系统使用SEDA并发架构。最近为系统添加了新模块,合规风控。由于是新模块,且需求刚起步,为了追求开发速度,开发初期并没有太注意编程细节。在做性能测试的时候,发现合规系统一个线程每秒只能处理10个订单。这跟单线程每秒1000个订单的距离相差遥远。
SEDA并发架构在吞吐上没有任何问题,但编程细节不注意,也会对性能造成致命影响。所以,我需要对合规系统做Profiling,找到性能瓶颈,并加以改进。
并发模型以及Logger对其影响
Thread-Based-Concurrency(TBC)
Event-Driven-Concurrency(EDC)
Staged-Event-Driven-Architecture(SEDA)
Actor
LMAX Disruptor
TBC最常见的就是BIO的web server,如BIO的tomcat。每一个HTTP请求都是一个线程。TBC的优点是处理大型复杂事务。比如事务中存在大量阻塞IO。Logger的性能对TBC的吞吐和延迟影响并不大。但线程创建开销大,线程的上下文切换开销也大,对共享内存编程的技术要求比较高,很容易出错。
TBC后面的几个模型均属于Event-Sourcing类型。一个非典型场景是NIO的web server,比如Jetty,NIO tomcat。NIO的web server在socket处理上使用了事件驱动模型,但对http request还是使用thread模型。典型场景则是很多交易系统所用的SEDA模型。事件驱动模型的特点是将任何的请求或状态变化均变为event,并将event分为几种状态,每种状态的event用少量的线程甚至是单线程去处理,线程和线程之间会传送处理好的event。
事件驱动模型在互联网高并发设计中非常火。而SEDA和Actor则是不相上下的最优方案。而Disruptor的核心优势是线程之间的消息传递机制,跟BlockingQueue相比,其吞吐是BQ的6倍左右,而延迟是BQ的0.16%. 具体比较见https://github.com/LMAX-Exchange/disruptor/wiki/Performance-Results 。所以,生产者消费者模式的消息传递使用Disruptor是一个很好的方案。
因为事件驱动模型中线程数量是有限的,所以需要让线程充分利用CPU,让CPU满负荷跑动起来,任何的IO阻塞,Logger的性能,均会影响系统的吞吐和延迟。例如在事件驱动模型中,假设一个线程一秒钟可以处理100万个单子,也就是一秒钟处理100万个事件,如果每个事件处理过程中,发生了IO阻塞或者Logger开销,即使是1us的开销,100万个事件合在一起就是1s,这使得系统的吞吐立马下降到50万每秒,性能缩水一半。所以,事件驱动模型的事件处理线程中,要消除跟业务计算无关的CPU消耗,比如IO,Logger。
合规系统调优
系统说明
此合规系统是SEDA中的某一个stage处理系统,Java编写,单线程,跟其它线程消息传递使用LinkedBlockingQueue,使用log4j 1.2.7打日志。在logger调优之前,已经做了去IO的优化。接下来的调优可以使用Disruptor替换BQ。这部分并不打算在本文中阐述。本文主要关注的是Logger的调优。
Log4j调优前
log4j的配置:
log4j.appender.dailyRolling=org.apache.log4j.DailyRollingFileAppender
log4j.appender.dailyRolling.ImmediateFlush=true
log4j.appender.dailyRolling.File=/datayes/trading/compliance/log/ComplianceServer.log
log4j.appender.dailyRolling.layout=org.apache.log4j.PatternLayout
log4j.appender.dailyRolling.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] [%-5p] %c - %m %n
使用jvisualvm做profiling, 得出的结果:
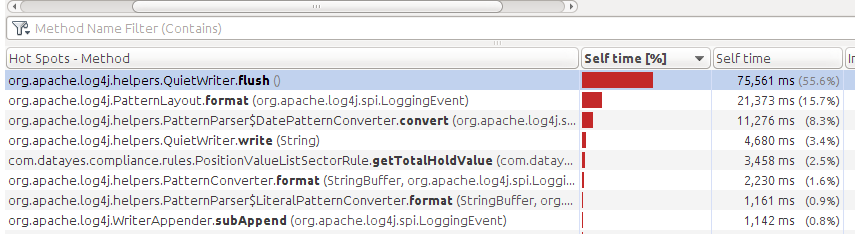
通过上图可以看到,logger的CPU开销占到了当前线程总CPU开销的90%以上。主要原因是因为log4j使用了ImmediateFlush和同步IO。
增加IO Buffer
首先想到的改进方法是给Logger增加IO Buffer,并开启flush cache。
log4j.appender.dailyRolling=org.apache.log4j.DailyRollingFileAppender
log4j.appender.dailyRolling.ImmediateFlush=false
log4j.appender.dailyRolling.BufferedIO=ture
log4j.appender.dailyRolling.BufferSize=8192
log4j.appender.dailyRolling.File=/datayes/trading/compliance/log/ComplianceServer.log
log4j.appender.dailyRolling.layout=org.apache.log4j.PatternLayout
log4j.appender.dailyRolling.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] [%-5p] %c - %m %n
Flush cache控制logger的缓存,logger待缓存满了,再一次性提交给appender。 BufferedIO控制Appender的缓存,appender待缓存满了,才一次性写入硬盘。

经过优化以后,log4j的开销下降到线程CPU开销的80%左右。还是不理想。
升级log4j2
上面的优化并不理想,现在的突破口就是讲logger的运算变为异步,放入另一个线程处理,从而净化业务逻辑运算线程。log4j 1.2.7存在AsyncAppender,可以将Appender写硬盘变为异步。但经过调研,发现在log4j2中,出现了AsyncLogger,可以将logger变为异步。这样连logger的运算也可以踢出本线程。
此外,AsyncLogger使用的线程通信是Disruptor,而AsyncAppender使用的是BlockingQueue,所以AsyncLogger性能又高了一大截。
AsyncLogger的性能比较可以查看 https://logging.apache.org/log4j/2.x/manual/async.html
使用AsyncLogger
log4j2的配置为:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="info">
<Appenders>
<RollingFile name="dailyRolling" fileName="/datayes/trading/compliance/log/ComplianceServer.log"
filePattern="/datayes/trading/compliance/log/ComplianceServer.log.%d{yyyy-MM-dd}">
<PatternLayout>
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] [%-5p] %c - %m %n</Pattern>
</PatternLayout>
<Policies>
<TimeBasedTriggeringPolicy />
</Policies>
</RollingFile>
</Appenders>
<Loggers>
<asyncRoot level="info" includeLocation="true">
<AppenderRef ref="dailyRolling" level="info"/>
</asyncRoot>
</Loggers>
</Configuration>
java初始化log4j2,使用非classpath下的xml。
public static void config(String configXmlPath) {
if (configXmlPath==null) return;
try {
LoggerContext ctx = (LoggerContext) LogManager.getContext(false);
ctx.setConfigLocation(new File(configXmlPath).toURI());
ctx.reconfigure();
} catch (Exception e) {
System.out.println("Can not initialize log4j2 with config "+ configXmlPath);
e.printStackTrace();
System.exit(1);
}
}
优化后的结果:
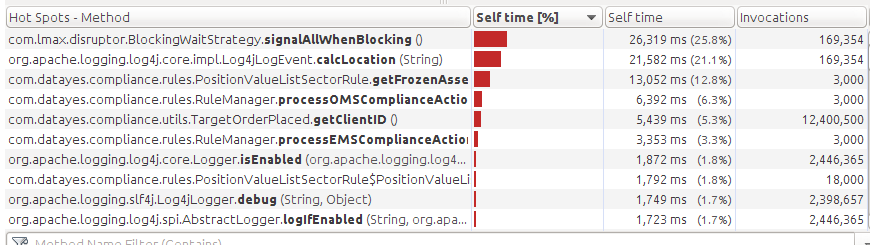
Log4j的开销降到了线程CPU时间的50%左右。最大的开销是disruptor的锁机制。
优化Disruptor
Disruptor比BQ快的原因有以下这么几点:
去锁。使用CAS。锁竞争会使CPU跳出当前线程,回归到操作系统层面来判断锁的赢家,这导致大量上下文切换,上下文切换也会导致CPU cache失效。所以锁是一个开销很大的机制。Java中CAS的实现在Atomic包里。
使用RingBuffer数据结构,避免Q的动态分配,垃圾回收。
避免多核CPU内存伪共享问题。
具体请参考https://lmax-exchange.github.io/disruptor/
从前面的优化结果可以看到,系统已经在使用AsyncLogger和Disruptor,但却还在使用锁机制。这是因为Disruptor提供了3种等待机制:Block,Sleep,Yield。而AsyncLogger默认使用的是Block策略。Block还是用的锁机制。三种等待策略的解释:https://github.com/LMAX-Exchange/disruptor/wiki/Getting-Started#basic-tuning-options
修改Disruptor等待机制:
public static void config(String configXmlPath) {
String strategy = System.getProperty("AsyncLoggerConfig.WaitStrategy");
if (!("Sleep".equalsIgnoreCase(strategy) || "Block".equalsIgnoreCase(strategy) || "Yield".equalsIgnoreCase(strategy))) {
System.out.println("Set disruptor wait strategy to sleep");
System.setProperty("AsyncLoggerConfig.WaitStrategy", "Sleep");
}
if (configXmlPath==null) return;
try {
LoggerContext ctx = (LoggerContext) LogManager.getContext(false);
ctx.setConfigLocation(new File(configXmlPath).toURI());
ctx.reconfigure();
} catch (Exception e) {
System.out.println("Can not initialize log4j2 with config "+ configXmlPath);
e.printStackTrace();
System.exit(1);
}
}
修改以后的结果:
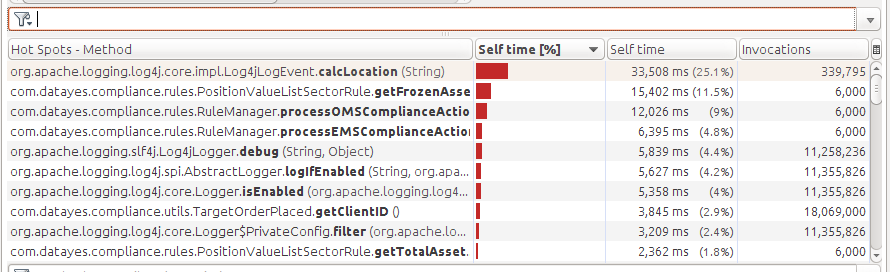
锁等待策略的开销没有了。但calcLocation的时间还是很高。
关闭CalcLocation
任何一个logger的计算location开销都不容忽视。计算location是将当前栈信息做快照,然后计算找到info,debug等方法的具体调用位置。详细内容:https://logging.apache.org/log4j/2.x/manual/async.html#Location
在我的日志中,并不需要栈信息,只需要打印一个类全名,不需要calcLocation。将includeLocation改为false。最后测试:
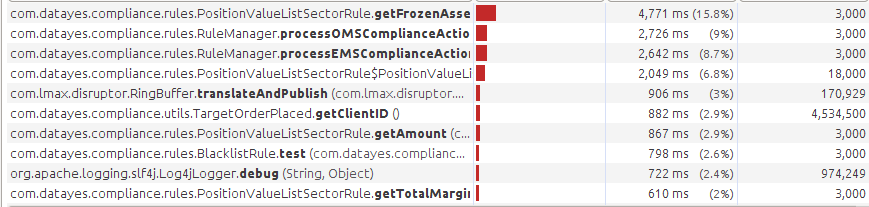
log4j的开销已经不足6%了。
到此,logger的优化完成。
Logger的几个调用方法优化
| 坏性能 | 好性能 |
| logger.info(“Hi “+user+”, where is “+other); | logger.info(“Hi {}, where is {}”, user, other); |
| logger.error(exception.toString()); | logger.error(“”, exception); |
| logger.debug(String.format(“The number is %d”, num)); | logger.debug(“The number is {}”, num); |
左边的劣势有2:
在本线程中做message的计算。增加额外开销。
如果没有开启debug,logger.debug也会调用String.format方法,浪费时间。
右边的好处是将参数封装以后提交给Appender,appender会对消息做format。