VirtualBox、CentOS 6.4、Hadoop、Hive玩起
1 安装VirtualBox:
VirtualBox是一款开源免费的并且非常强大的虚拟机软件,同时支持X86和AMD64/Intel64,可以在多个操作系统平台上运行。与同性质的VMWare和Virtual PC比较,VirtualBox独到之处包括支持远程桌面协议RDP、iSCSI及USB的支持。
在64为旗舰版Window7操作系统下安装VirtualBox,直接点击下载下来的.exe文件,可能会在安装过程中出现一些类似无法写入注册表的错误,不过我在安装过程中幸运地避免了这些错误,因为我在安装之前就搜索到网上的问题,通过他人的经验就避开了这些陷阱。
首先打开命令行窗口:win+R,输入cmd(以管理员身份运行),然后在命令行中输入VirtualBox.exe所在路径后输入-extract。例如我的是
C:\Users\Administrator\Downloads\VirtualBox.exe –extract
然后回车,会弹出提示框指示把VirtualBox解压后的路径:
Files were extracted to C:\User\ADMINI~1\AppData\Local\Temp\VirtualBox
根据提示找到解压后的文件,双击其中的amd64.msi即可安装VirtualBox。
抱歉由于晚上才整理这份文档,因此没有能够及时截图进行说明,只能以文字的形式解释。
2 在VirtualBox上安装CentOS 6.4:
相信网上已经有很多非常详细的教程教导如何在VirtualBox上安装CentOS,我也是按照网上的教程一步一步进行安装和配置的。唯一值得提一下的是,我很二的当启动虚拟机的安装时,直接让安装过程跳到自动登录了,也就是跳过了整个安装界面,这样也可以进入CentOS进行操作,但是这样的操作每次关机后都不会被保存,因为根本没有安装CentOS嘛,但是为什么会不经过安装就会自动登录进去,这个问题需要查一下,请原谅我对CentOS刚上手,都要慢慢熟悉。重点在于需要按Enter进入安装界面!然后就是按照教程配置,最后安装完成后需要Reboot重启。内存我配置了1024MB,虚拟硬盘20G,路径为D:\VirtualBox\CentOS-6.4-64bit.vid。安装CentOS后默认Host key = right Ctrl,用于切换鼠标。
3 CentOS 6.4中Hadoop伪分布模式安装:
Hadoop伪分布模式是在单机上模拟Hadoop分布式,单机上的分布式并不是真正的分布式,而是使用线程模拟分布式。Hadoop本身无法区分伪分布和分布式,两种配置也很相似,唯一不同的是伪分布式是在单机器上配置,数据节点和名字节点均是一个机器。我是在CentOS 6.4上搭建Hadoop1.2.1伪分布模式,搭建环境所需的软件包括:CentOS 6.4、jdk-7u45-linux-x64.rpm、hadoop-1.2.1.tar.gz。
3.1 安装JDK并配置Java环境变量:
由于是64bit的操作系统,注意下载JDK时也是要64bit。
CentOS安装成功后,系统自带OpenJDK,查看相关安装信息:rpm qa | grep java
查看系统自带JDK的版本信息:java –version
卸载系统自带OpenJDK:
rpm –e –nodeps java-1.7.0-openjdk-1.7.0.19-2.3.9.1.el6_4.x86_64(请注意这里删除的OpenJDK就是之前查看得到的OpenJDK的安装信息中所显示的)
rpm –e –nodes java-1.6.0-openjdk-1.6.0.0-1.61.1.11.11.el6_4.x86_64
rpm –e –nodes tzdata –java-2013b-1.el6.noarch
(注意删除时根据实际安装信息进行删除)
然后进入JDK所在路径,安装JDK:rpm –ivh jdk-7u45-linux-x64.rpm,默认情况下jdk会安装在/usr/java目录下。
然后配置环境变量:vi + /etc/profile
在profile文件末尾添加如下内容:
JAVA_HOME=/usr/java/jdk1.7.0_45
JRE_HOME=/usr/java/jdk1.7.0_45/jre
PATH=$PATH:$JAVA_HOME/bin:$JER_HOME/bin(注意:冒号为分隔符)
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
Export JAVA_HOME JRE_HOME PATH CLASSPATH
在vi编辑器增加以上内容后保存退出,并执行以下命令是配置生效:source /etc/profile
配置完成后,输入java –version,如出现以下信息说明java环境安装成功:
java version “1.7.0_45”
Java(TM) SE Runtime Environment(build 1.7.0_45)
Java HotSpot(TM) Server VM(build 1.7.0_45, mixed mode)
查看JAVA_HOME:echo JAVA_HOME
3.2 SSH无密码验证配置:
Hadoop需要使用SSH协议,namenode将使用SSH协议启动namenode和datanode进程,伪分布模式数据节点和名字节点都是本身,因此配置SSH localhost无密码验证登陆就会方便很多。实际上,在Hadoop的安装过程中,是否免密码登陆是无关紧要的,但是如果不配置免密码登陆,每次启动Hadoop都需要输入密码以登陆到每台机器的DataNode上,考虑到一般的Hadoop集群动辄拥有数百或上千台机器= =,因此一般说来都是配置SSH的免密码登陆。
在CentOS中,已经含有SSH的所有需要的套件了,默认情况是不需要再次安装。使用root权限执行以下命令。
1、检查Linux是否安装SSH:rpm –qa | grep ssh(下载安装SSH:yum install ssh)
2、检查ssh服务是否开启:service sshd status(开启ssh服务:service sshd start)
3、查看ssh服务是否开机自动启动:chkconfig –list sshd,如图所示为开机自动启动:
设置开机自动启动ssh服务:chkconfig sshd on
![]()
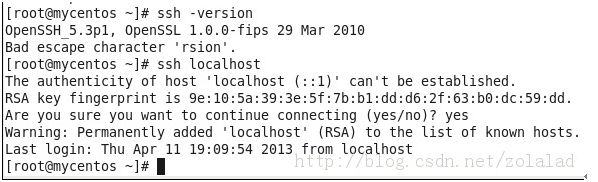
4、配置免密码登陆本机:在root权限进行,查看root文件夹下是否存在.ssh文件夹,这是一个隐藏文件ls –a,一般安装ssh是会自动在当前用户下创建这个隐藏文件夹,如果没有可以手动创建一个。接下来输入命令:注意命令中不是双引号,是两个单引号


这样免密码登陆本机已经配置完成,可以通过ssh本机IP测试是否需要密码登陆,如图所示说明配置免密码登陆成功!
3.3 配置Hadoop:
1、下载hadoop-1.2.1.tar.gz,将其拷贝到/usr/local/hadoop目录下,然后在该目录/usr/local/hadoop下解压安装生成文件/hadoop-1.2.1(即hadoop被安装到/usr/local/hadoop/ hadoop-1.2.1文件夹下):tar –zxvf hadoop-1.2.1.tar.gz
2、配置hadoop的环境变量:
vi /etc/profile
#set hadoop
export HADOOP_HOME=/usr/local/hadoop/hadoop-1.2.1
export PATH=$HADOOP_HOME/bin:$PATH
输入命令source /etc/profile使刚配置的文件生效。
3、进入/usr/local/hadoop/hadoop-1.2.1/conf,配置Hadoop配置文件:
3.1、配置hadoop-env.sh文件:
vi hadoop-env.sh
# set java environment
export JAVA_HOME=/usr/java/jdk1.7.0_45(根据实际情况配置)
qw(编辑后保存退出)
3.2、配置core-site.xml:
vi core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000/</value> 注:9000后面的“/ ”不能少
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-1.2.1/hadooptmp</value> 注:自己在该路径下创建文件夹hadooptmp
</property>
</configuration>
说明:hadoop分布式文件系统的两个重要的目录结构,一个是namenode上名字空间的存放地方,一个是datanode数据块的存放地方,还有一些其他的文件存放地方,这些存放地方都是基于hadoop.tmp.dir目录的,比如namenode的名字空间存放地方就是${hadoop.tmp.dir}/dfs/name, datanode数据块的存放地方就是${hadoop.tmp.dir}/dfs/data,所以设置好hadoop.tmp.dir目录后,其他的重要目录都是在这个目录下面,这是一个根目录。我设置的是/usr/local/hadoop/hadoop-1.2.1/hadooptmp,当然这个目录必须是存在的。
3.3、配置hdfs-site.xml:
vi hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name> (备份的数量)
<value>1</value>
</property>
</configuration>
3.4、配置mapred-site.xml:
vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
3.5、配置masters文件和slaves文件(一般此二文件的默认内容即为下述内容,无需重新配置):
vi masters
localhost
vi slaves
localhost
注:因为在伪分布模式下,作为master的namenode与作为slave的datanode是同一台服务器,所以配置文件中的ip是一样的。
3.6、主机名和IP解析配置:
vi /etc/hosts
编辑主机名:vi /etc/hostname
localhost.localdomain编辑保存后退出
vi /etc/sysconfig/network
注:这三个位置的配置必须一致!
4、启动Hadoop:
4.1、进入/usr/local/hadoop/hadoop-1.2.1/bin目录,格式化namenode:
hadoop namenode –format
4.2、启动Hadoop所有进程,进入/usr/local/hadoop/hadoop-1.2.1/bin目录:start-all.sh
启动完成后,可以用jps命令查看Hadoop进程是否完全启动,正常情况下应该有如下进程:
16890 Jps
14663 TaskTracker
14539 JobTracker
14460 SecondaryNameNode
14239 NameNode
14349 DataNode
说明:
1.secondaryname是namenode的一个备份,里面同样保存了名字空间和文件到文件块的map关系,建议运行在另外一台机器上,这样master死掉之后,还可以通过secondaryname所在的机器找回名字空间,和文件到文件块得map关系数据,恢复namenode。
2.启动之后,在/usr/local/hadoop/hadoop-1.2.1/hadooptmp下的dfs文件夹里会生成data目录,这里面存放的是datanode上的数据块数据,因为是伪分布模式,所以name 和 data都在一个机器上,如果是集群的话,namenode所在的机器上只会有name文件夹,而datanode上只会有data文件夹。
在搭建Hadoop过程中,出现问题:Warning:$HADOOP_HOME is deprecated
经过查看hadoop-1.2.1的hadoop和hadoop-config.sh脚本,发现对于HADDP_HOME做了判断,解决方法如下:
在hadoop-env.sh,添加一个环境变量:export HADOOP_HOME_WARN_SUPPRESS=true
5、查看集群状态:hadoop dfsadmin –report
打开浏览器输入部署Hadoop服务器的IP:
http://localhost:50070
http://localhost:50030
4 CentOS 6.4 Hadoop集成Hive:
1、下载hive-0.12.0.tar.gz,将其拷贝到/usr/local/hive目录下,然后在该目录/usr/local/hive下解压安装生成文件/hive-0.20.0:tar –zxvf hive-0.20.0.tar.gz
2、配置hive的环境变量:
vi /etc/profile
#set hive
export HIVE_HOME=/usr/local/hive/hive-0.20.0
export PATH=$HIVE_HOME/bin:$PATH
输入命令source /etc/profile使刚配置的文件生效
3、进入/usr/local/hive/hive-0.20.0/conf,依据hive-env.sh.template,创建并配置hive-env.sh:
# cp hive-env.sh.template hive-env.sh
# vi hive-env.sh
export HIVE_CONF_DIR=/usr/local/hive/hive-0.20.0/conf //设置hive配置文件的路径
export HADOOP_HOME=/usr/local/hadoop/hadoop-1.2.1 //配置hadoop的路径
4、然后在系统自带的mysql数据库中给Hive配置一个数据库:
# mysql -u root -p
Enter password:
mysql> create database hive;
mysql> grant all on hive.* to hive@'%' identified by 'hive'; //创建hive用户,并授权
mysql> flush privileges;
show databases;
5、接下来配置hive-site.xml:
# cp hive-default.xml.template hive-site.xml
# cp hive-default.xml.template hive-default.xml
# cp hive-log4j.properties.template hive-log4j.properties
# cp hive-exec-log4j.properties.template hive-exec-log4j.properties
# vi hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value></value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/data/hive/warehouse/</value>
</property>
6、最后下载mysql-connector-java-5.1.22-bin.jar并将之copy到hive-0.12.0/lib目录下。现在hive运行环境已经配置好了,可以启动Hive,最终显示如下:
# cd /usr/local/hive/hive-0.12.0/bin
# ./hive
