Movie Recommendation with MLlib
参考链接:https://databricks-training.s3.amazonaws.com/movie-recommendation-with-mllib.html
Step 1 背景知识
学习如何使用Spark中的MLlib构建一个推荐系统。MLlib支持基于模型的协同过滤算法,将用户-物品评分矩阵构建成隐语义模型,引入隐含特征向量来预测用户-物品的缺失评分值。MLlib中采用最小二乘法(Alternating Least Squares, ALS)来学习训练隐语义模型中的隐含特征向量。
Step 2 数据集
下载参考链接中的数据集,将目录usb/data/movielens/medium或者usb/data/movielens/large下的movies.dat和ratings.dat数据集上传到hadoop hdfs上去。前面的1051和1052是通过history命令查看历史时的命令的id。
其中movies.dat文件记录电影信息,MovieID::Title::Genres。ratings.dat文件记录用户对电影的评分,UserID::MovieID::Rating::Timestamp。


对目标用户建立训练集,在目录~/jiawen/machine-learning下有personalRatings.txt.template文件,使用vim编辑器对其编辑,其中用户ID为0,是对目标用户特殊的ID号。修改用户0对各部电影的评分,原来填写的是’?’,评分为5分制。
Step 3 程序预览
通过vim machine-learning/python/MovieLensALS.py可以查看代码,暂时还不是完整的代码,之后逐步添加。
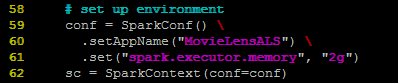
首先我们需要创建SparkConf对象并用其来创建SparkContext对象,即Spark程序入口,SparkContext为Spark应用程序准备运行环境。这里设置应用程序名为MovieLensALS,并为该应用程序的Executor分配内存为2G。Executor是应用程序在worker节点上的一个进程,负责运行某些task,并且负责将数据存在内存或者磁盘上。

然后读取评分数据和电影数据。这里评分数据和电影数据已经被上传到hdfs上,所以从命令行读入的参数sys.argv[1] = hdfs:///user/jiawen/MovieRecommendation/medium/表示这两份数据的位置。join的作用在于将文件所在目录与文件名连接起来,然后映射到parseRating这个函数上。

parseRating()函数如上图所示,产生评分数据的RDD为(long, rating),使用时间戳的最后一位(模10操作嘛)作为键,评分元组(user:int, item:int, rating:float)作为值。

parseMovie()函数如上图所示,产生电影数据的RDD为元组(movieid, title)。使用collect()的作用是以数组的形式返回数据集的所有元素。
Step 4 运行程序
接下来我们对评分数据做一些统计。

vim保存退出之后,使用如下命令运行程序,可以产生正确的结果。
![]()
![]()
Step 5 拆分训练集
我们使用MLlib中的最小二乘法来训练得到一个矩阵因式分解的隐语义模型。我们将评分训练数据集拆分成三个不重合的子集,分别为训练集training、测试集test和验证集validation,主要是根据时间戳的最后一个数字。我们在训练集上训练得到模型,然后基于RMSE在验证集上选择最好的模型参数,最后在测试集上对该模型记性评测。我们将目标用户在personalRatings.txt中的数据添加到训练集中,这样能够对目标用户产生推荐结果。我们将这三个数据集分别记性cache缓存,便于之后多次访问。


在处理训练集时,使用union将训练数据集产生的RDD和目标用户的评分数据产生的RDD做并集操作。Repartition(numPartitions)是将RDD中的所有records平均划分到numPartitions个partition中。然后程序(命令与上面的命令相同),获得如下结果:
![]()
Step 6 使用ALS有监督学习
在这个部分中,我们使用最小二乘法训练多个模型(即多个参数取不同的值),然后选择效果最好的一个模型。主要训练的参数有三个:rank(隐含特征的个数即隐含特征矩阵的维度)、lambda(归一化因子)、iterations(迭代次数)。这里我们测试8种组合,rank分别取值为8和12,lambda分别取值为1.0和10.0,迭代次数分别为10和20。对于每一种组合即是一个模型,我们在验证集上计算RMSE的值,最后选择在验证集上RMSE取得最小值的模型,然后在测试集上计算该模型得到的RMSE值。 其中计算RMSE的函数如下所示:


其中需要搞明白的是ALS.train返回的是什么,是通过训练数据集和三个参数训练得到的隐语义模型,具体ALS.train代码没看,可以看一下其代码框架:

运行程序得到的结果如下:

在运行程序时可能会报如下错误:
![]()
![]()
这是因为driver分配的内存不足,也就是我们写的程序main()(被称之为driver)。在使用spark-submit提交任务时,如果不指定给driver分配内存默认分配的是512M,如果处理的数据量很大则会爆内存出现上面的错误。解决方案是在spark-submit中指定—driver-memory memSize参数设定driver的JVM内存大小。可以通过spark-submit –help查看其它可以设置的参数。
![]()
Step 7 产生推荐结果
最后这一部分我们将为目标用户产生推荐结果,产生(0, movieId)元组,其中movieId是目标用户没有评过分的并且模型预测分数最高的top-k个电影的id。

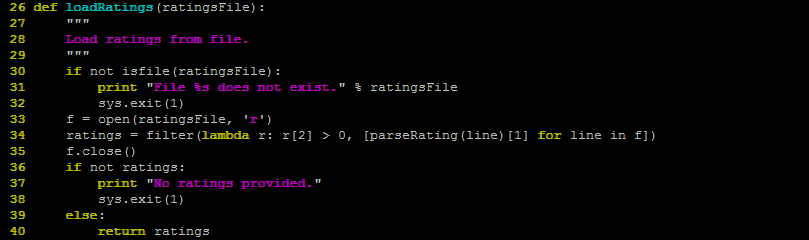

其中loadRatings(ratingsFile)是从本地读取目标用户的评分数据,如下所示:

选择top-10作为推荐结果。

duang~现在我们已经可以在Spark上利用MLlib进行电影推荐了~