使用SPSS Clementine进行社交网络分析
背景知识:社交网络分析、数据挖掘、IBM SPSS Modeler
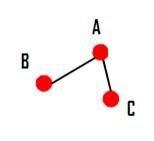
社交网络数据分析是人、组织、计算机或者其他信息或知识处理实体之间的关系和流动信息的映射和测量。图 1 是社交网络的一个示意图,其中的节点表示人、组织、计算机或者其他信息或知识处理实体;连线表示节点之间的关系或信息流动。信息流动的方式有很多,比如邮件,电话,短信,博客,等等。假设 A 经常与 B 和 C 通电话,通过分析 A 的电话 ID 记录,可以构筑出图 1 中的简单社交网络。从此图中我们可以看出 A, B, C, 三人 中,A 具有较强的影响力。如果 A 获得了正面或者负面的消息,这消息会很快传递给 B 和 C。而 B 与 C 之间的影响力是间接的,只能通过 A 来传播。
图 1. 社交网络示意图
随着节点和连线的增加,社交网络的复杂程度迅速提升。图 2 展示了一个较为典型的社交网络。大型和超大型的社交网络的处理是手工分析方式无法完成的。在过去的二十年中,社交网络分析领域的快速发展,很大程度得益于计算机计算能力的提升和各种数据挖掘方法的发展。
图 2. 一个典型的社交网络
数据挖掘 (data mining) 是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。从商业角度去定义,数据挖掘是一种新的商业信息处理技术,其主要特点是对商业数据库中的大量业务数据进行抽取、转换、分析和其他模型化处理,从中提取辅助商业决策的关键性数据。在技术上可以根据它的工作过程分为:数据的抽取、数据的存储和管理、数据的展现等关键技术。
图 3. 数据挖掘
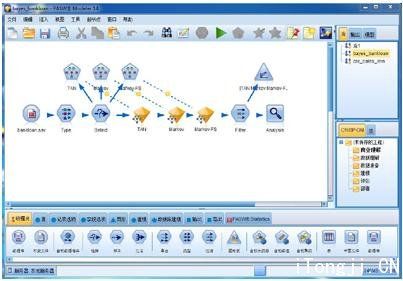
被誉为第一数据挖掘工具的 IBM SPSS Modeler( 原名 Clementine) 是 IBM SPSS 的核心挖掘产品,它拥有直观的操作界面,自动化的数据准备,和成熟的预测分析模型。使用它,企业可以将数据分析和建模技术与特定的商业问题结合起来,找出其他传统数据挖掘工具可能找不出的答案。
图 4. IBM SPSS Modeler 的操作界面
IBM 两种社交网络分析的算法原理
社交网络分析(SNA)是 Modeler 15 增加的一个新功能。目前有两种算法支持这个功能,分别称作 GA 和 DA。GA 全称 Group Analysis, 是一种基于群体的分析方法。DA 全称 Diffusion Analysis,着眼于计算一些人的行为对网络中其他人的冲击强度。在 Modeler 15 中这两个算法以两个源节点的形式出现,如图 5 所示。
图 5. GA 和 DA 在 Modeler 15 中以两个源节点的形式出现
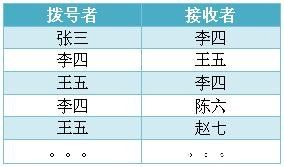
下面我们简单介绍一下两者的算法原理。假设我们有过去半年里某地区的电话清单,数据量在百万到千万条左右。数据记录了打电话的人和接收的人,如图 6 所示。
图 6. GA 和 DA 的输入数据 -- 电话清单举例
GA 收到这些数据后,会进行如下的分析:
- 根据共有邻接节点的数量,量化各个节点(也就是张三、李四、王五。。。)之间联系的强度;
- 保留高强度的联系,去除低强度的联系。进行此步骤后,社交网络会退化成几个内部联系多、外部联系少的次网络,以及很多孤立的节点。每个次网络对应一个群体(group),称为这个群体的核 (kernel);
- 把那些孤立的节点连到距离他们最近的群体去。上一步里暂时去除的低强度的联系,在这一步发挥了主要作用;
- 对各个群体以及群体里的个体进行分析画像,例如评估群体内每个个体的地位,找出“领袖”,计算群体密度,等等。这些特性将用于后继应用中,下一节的实例中会进一步展示。
相比之下,DA 的算法原理要更简单一些。DA 不会将网络分成群体,而是在原网络上进行计算。DA 着眼于计算一些人的行为对网络中其他人的冲击强度。
收到如图 6 的数据后,DA 会构筑一个有向加权网络,如图 7 所示。网络中的节点代表人、组织、计算机或者其他信息或知识处理实体;连线表示节点之间的关系或信息流动;连线的方向表示了关系的主动被动方,或者信息流动的方向(通常为双向,图 7 省略了此内容)。
DA 还需要有行为发生的人的名单。这里的行为可以是从公司辞职,更换手机服务商,试用了某种产品,等等。这些人被称作“初始扩散点”(Initial diffusing seeds),由图 7 中的红色节点表示。接下来,设定初始扩散点的冲击强度,然后采用衰败扩散过程就可以估计出其他节点所受到的冲击大小。
图 7. DA 算法解析

社交网络分析实例:客户流失预警和病毒式营销
客户流失预警
最近二十年中,移动通信成为占主导地位的通信介质。在许多国家,特别是发达国家,市场规模已达到饱和的程度,新客户的获得主要靠从竞争对手那里赢得。同时,公共法规和移动通信的标准化,让客户可以轻松地从一个运营商换到另一个,令市场极不稳定。由于赢得一个新客户的成本远远高于维护一个现有客户的成本,移动运营商更加重视客户保留的问题。因此,客户流失预警已成为一个关键的移动商务智能(BI)应用程序。
传统的客户流失预警解决方案直接采用数据挖掘技术,根据客户的呼叫模式(通常由数百个变量描述)构建客户档案,然后基于某些代表性属性预测客户的流失概率。可用于建模的数据源有很多,包括使用历史,结算,付款,客户服务,应用程序,和信用卡资料。
社会网络分析可以补充和加强传统的解决方案,使运营商能更根据“早期预警”,更有效地找出潜在的流失客户,提高保留率。例如,一个客户的亲密朋友流失,社会网络分析会及时推断出这个客户很可能是潜在的流失目标。而传统的解决方案寻找潜在流失目标时,需要等到这个客户有显著的变化(例如减少支出,预付费卡,不充电等)- 这种时候,她的流失很可能已经无法挽回了。
使用 GA 进行客户流失预警实例分析
图 8 至图 10 演示了一个用 GA 进行客户流失预警的实例。在图 8 中,GA 源节点接收到一个如图 6 所示的 CDR 源文件。为方便起见,我们将 GA 源节点的名字直接显示为 CDR 源文件的名称 Demo_CDR. GA 源节点使用 GA 算法进行群体的划分,并计算出基于群体的各种特性值。完成对源文件的分析计算后,计算结果以数据文件的形式被保留在 Demo_GA_KPI。
图 8. Modeler 流:用 GA 源节点生成特性数据
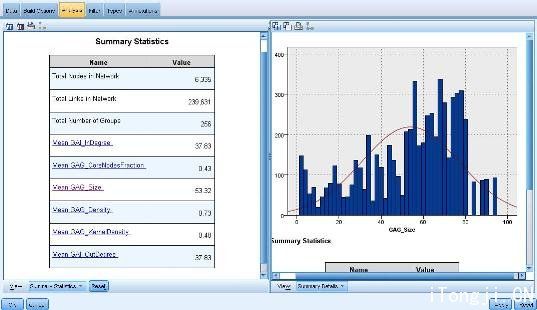
图 9 展示了图 8 中 GA 源节点对其接收到的 CDR 源文件的分析结果。图的左侧是关于群体和个体特征的简单统计信息,而右图给出了对应特征更加详细的统计描述。用户可以据此了解群体分析的结果,从而修改相关参数以实现最理想的群体划分和画像。
图 9. 用 GA 源节点生成的特性数据
在图 10 中,我们将利用 GA 分析结果进行建模,用于预测每个客户所在群体的流失风险。我们用之前由 GA 源节点所产生的数据文件 Demo_GA_KPI 作为源节点。另外,我们还需要一份已流失客户名单 Demo_GA_churner。如果一个组里已流失客户占总客户的比例达到一定程度,我们就认为这个群体为流失高危群体,否则为低危群体。图 10 中左下侧的模型以流失高 / 低危群体作为目标变量,用 Demo_GA_KPI 里所包含的群体特征值,以及通过对个体特征值的处理得到的辅助群体特征为预测变量,采用 CHAID 算法进行建模。
图 10. Modeler 流:用 GA 源节点生成特性数据和已流失客户名单建模,量化预测各个群体的流失风险
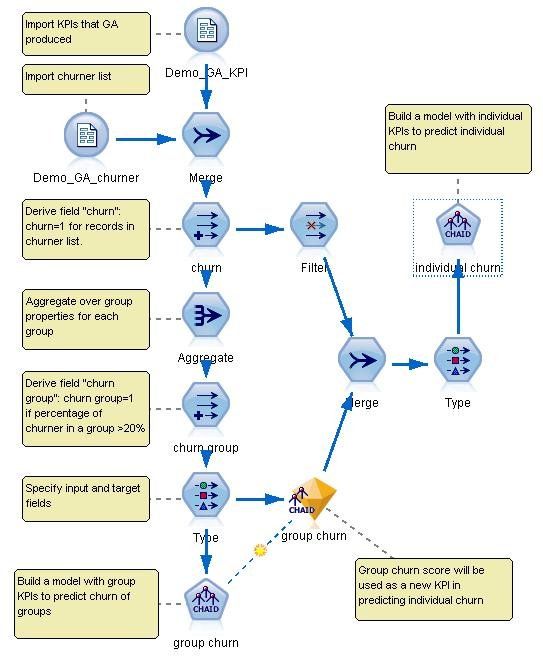
群体的流失风险对于群体中个体的流失与否是一个非常重要的参考因素。另外,个体在群体里的角色,地位,等等因素也在一定程度上影响着个体的流失风险。鉴于此,我们将所有这些因素作为预测个体流失的变量,从而得到预测个体流失的模型,如图 10 右侧的流所示。
需要注意的是,在上述建模过程中我们仅仅使用了用户通话记录和客户流失记录就可以预测群体以及个体的流失风险。然而通常情况下,我们可以有更多的关于用户人口统计学和消费行为的数据,而这些数据将极大的提升客户流失预测的精度。
使用DA进行客户流失预警实例分析
与 GA 不同,DA 源节点不仅需要一个如图 6 所示的 CDR 源文件,还需要一个“初始扩散点”(Initial diffusing seeds) 的文件,也就是流失客户的名单。
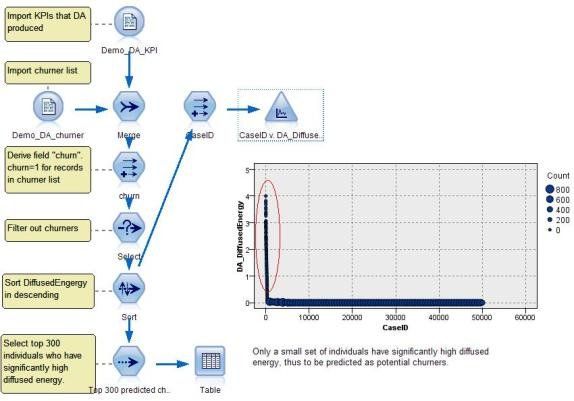
DA 源节点使用 DA 算法进行扩散分析,从而计算出网络中个体受到初始扩散点的冲击强度。冲击强度的大小将直接影响着个体的流失风险。DA 输出的特征以数据文件的形式保存下来,并可在随后应用于生成图表或建立模型。图 12 集中展示了使用 DA 源节点产生的特性文件生成分析图表的一个典型数据流。
图 11. Modeler 流:用 DA 源节点生成的特性数据量化预测客户流失风险
病毒式营销
病毒营销是营销技术的一种。它利用社交网络提升品牌知名度或实现其他目标(如产品销售)。具体的方式是发起人给一些用户发出产品的最初信息,再依靠用户自发的口碑宣传,“让大家告诉大家”,使其广泛传播。因为它的传输策略是利用快速复制的方式将信息传向数以千计、数以百万计的受众,类似于自然病毒和电脑病毒,所以被经济学家称为病毒营销。
采用群体分析和扩散分析技术,我们可以设计出一个更为精致的病毒性营销策略。我们会识别出群体中的“领袖人物”:那些对周围人影响力大的人,将产品信息发布给他们。借助这些人的影响力,产品的信息可以更为有效的在社交网络中传播。我们还可以通过扩散分析技术去量化评估信息传播的效果。比如,takingtaking 推出新产品,我们可以做如下的工作:
- 通过 GA 进行网络分析,发现领袖人物。
- 针对网络中的领袖人物发布产品信息,促使他们支持和推荐新产品。
- 选择网络中的领袖人物作为初始传播种子,通过 DA 进行扩散分析,估算网络中其他个体购买新产品的可能性。
- 针对扩散分析预测出的最有可能购买新产品的客户,营销人员进行进一步的推销工作,使得新产品市场导入成功率明显改善。
总结
本文介绍了 Modeler 中两种 SNA 模块 GA 和 DA 的算法原理 , 并讲解了它们在客户流失预警和病毒式营销两种典型应用。
应用于客户流失预警时,GA 以海量的通话记录为输入,构建出社交网,然后将其分解为群体,计算出包括群体领袖在内的一系列特征值,用于后续建模。DA 则根据海量通话记录和流失客户名单直接在社交网络上对其他客户所收冲击进行分析。
GA 和 DA 可以结合起来应用于病毒式营销的筹划和分析。其中 GA 用于发现社交网络中具有强大影响力的个体,而 DA 用于评估出最有可能购买新产品的客户。
值得一提的是,GA 和 DA 提供的一系列特征可以和传统的特征无缝链接。新特征的引入有助于提高基于传统特征的模型的性能。这一点在我们做过的很多试点项目中得到验证。另外,我们也期待随着社交网络这一新兴事物的发展,GA 和 DA 能够在更多的领域得到应用。