[转]ASP.NET乱码深度剖析
http://blog.csdn.net/tomysea/article/details/6714711 写在前面
在Web开发中,乱码应该算一个常客了。今天还好好的一个页面,第二天过来打开一看,中文字符全变“外星文”了。有时为了解决这样的问题,需要花上很长的时间去调试,直至抓狂,笔者也曾经历过这样的时期。有时虽然是“侥幸”解决了,但对其中的原理却一知半解。
为了弄清楚这个问题,今天查了大半天的资料、测试。现把这些点滴记录下来,以激励自己重视基础,同时和大家分享一下,望大家不吝批评指正。
预备知识先介绍一些字符编码方面的基本知识,如果你对这些已经比较了解了,请直接跳过此节。
1. 字符集与字符编码概述
简单来说,字符集就是与特定区域相关的一系列有效字符的有序集合,比如字母、数字、标点符号等。注意关键字“有序”,表明集合中的每一个字符都是具有唯一数字编号(码值)的。不同国家使用的语言文字、符号不一样,相应的字符集必定也不一样。比如中国使用汉字,美国使用英语,韩国使用韩文,等等。
字符集是为了信息交互而设计的,最终还是要转化成计算机的表示法。我们知道,计算机只认识0和1,它对字符集符号不感冒。所以,我们必须想办法把字符转化为0和1的序列。我们知道,计算机最小的存储单位是位(bit),程序中一般使用的最小单位是字节(byte)。为了把字符存储到计算机中,我们就要考虑用几个byte几个bit,考虑每一个bit上是0还是1,考虑存储和读取效率,并且必须兼顾整个字符集,这就是字符编码。
一句话,字符集只关心字符的定义,而字符编码负责字符的存储和读取细节。用三层模式来打比喻的话,字符集是模型层,而字符编码是业务层。注意:一般常说的GB2312、GBK等其实同时包含了这两方面的定义
2. 常用中文字符编码简介
GB2312
GB2312的全称是《信息交换用汉字编码字符集-基本集》,由国家标准总局于1980发布,1981年5月1日施行,中国大陆、新加坡使用此编码。基本集收录了6763个汉字,只能显示简体汉字。
GBK
1995颁布,全称是《汉字编码扩展规范》。在GB2312的其他上,增加了繁体汉字,支持ISO/IEC 10646-1 和GB-13000-1的全部中、日、韩(CJK)字符,共20902个。向下兼容GB2312。
GB18030
全称是《信息交换用汉字编码字符集基本集的扩充》,目前两个版本,分别于2000年和20005年颁布。该字符集收录了70000多个汉字,包括了藏、蒙古、维吾文等少数民族字符,是我国计算机系统必须遵循的基础性标准之一。向下兼容GBK和GB2312。
BIG5
台湾和港台地区使用的汉字编码,俗称“大五码”,共收录了13060个汉字。
UTF-8
这是目前使用最多的一种Unicode编码,是Visual Studio内置的编码,相信大家一定都不陌生。根据字符码值的不同,可能用1、2、3个字节表示。
注意,编码之间一般都不是兼容的。其它编码在此不作介绍,若想进一步了解字符编码,请看我收藏的一篇文章:http://blog.csdn.net/tomysea/article/details/6712344
3. 字符串、字符数组和字节数组
C#中的字符串(string)和字符(char)其实都是对象,他们有相应的类String和Char,string和char只是这两个类的一别名而已,内部都是采用Unicode码值表示。请注意我说的是码值,不是编码。
我们已经知道,Unicode的字符大多是多字节表示的,那么一个char就得用几个byte来表示。这里我要说的重点是,使用不同的编码表示字符串,其对应的byte可能是不一样的。请看下面的代码,注意输出字节数部分。UTF-8编码的字节数是22,而GB2312编码的字节数是16。
view plaincopy to clipboardprint?
- string title = "2012真的来了吗?"; //字符串
- char[] chars = title.ToCharArray(); //字符数组
- byte[] bytes = System.Text.Encoding.UTF8.GetBytes(title);
- Response.Write(chars.Length + " "); //10 (字符数)
- Response.Write(bytes.Length + " "); //22 (UTF-8编码的字节数)
- bytes = System.Text.Encoding.GetEncoding("GB2312").GetBytes(title);
- Response.Write(bytes.Length + " "); //16 (GB2312编码的字节数)
string title = "2012真的来了吗?"; //字符串 char[] chars = title.ToCharArray(); //字符数组 byte[] bytes = System.Text.Encoding.UTF8.GetBytes(title); Response.Write(chars.Length + " "); //10 (字符数) Response.Write(bytes.Length + " "); //22 (UTF-8编码的字节数) bytes = System.Text.Encoding.GetEncoding("GB2312").GetBytes(title); Response.Write(bytes.Length + " "); //16 (GB2312编码的字节数)
从http请求响应模型说起http是一个请求/响应的模型,这个我们大家都知道。http请求可以分为请求头和请求实体两部分,相应地http响应也可以分为响应头和响应实体。请求头或响应头是浏览器与Web服务器通信用的(假定用浏览器访问Web服务器),而实体则是实际发送的数据,比如Form表单的数据、Ajax提交的数据、传回来的html代码等。不管是浏览器还是Web服务器,在发送实体前都会把它转换为字节流。明白这一点很重要,因为涉及字节流就一定会与字符编码有关。
从上面的请求响应模型中我们可以得出一个结论:请求和响应编码必须严格保持一致!为什么呢?这很好理解,浏览器和Web服务器是要通信的,如果编码不一样的话,势必会造成许多“误解”。假设浏览器是中国人(不懂E文),而Web服务器是美国人,他们两个的“编码”(语言)不一致,悲催的结局不言而喻。
ASP.NET中请求响应编码的设置你可以在machine.config或web.config文件指定全局配置,也可以在页面级特别指定。如果你未手动指定且machine.config中也为空,则默认会读取计算机上“区域选项”中的设置。
1. 全局配置
在machine.config或web.config文件(根目录或者子目录都有效)中的system.web节点中配置globalization节点。如果在根目录下的web.config配置,则会响应整个网站,若只是在子目录下配置,则只会响应该目录及其子目录。 详细配置如下:
view plaincopy to clipboardprint?
- <system.web>
- <globalization fileEncoding="utf-8" requestEncoding="utf-8" responseEncoding="utf-8"/>
- <!--按顺序是:文件编码 请求编码 响应编码-->
- <!―-fileEncoding会在后面说到-->
- <!--后面还有其它配置-->
<system.web> <globalization fileEncoding="utf-8" requestEncoding="utf-8" responseEncoding="utf-8"/> <!--按顺序是:文件编码 请求编码 响应编码--> <!―-fileEncoding会在后面说到--> <!--后面还有其它配置-->
2. 页面级的配置
在aspx页面的Page指令中设置响应编码
view plaincopy to clipboardprint?
- <%@ Page Language="C#" AutoEventWireup="true" ResponseEncoding="utf-8"
- CodeBehind="byte.aspx.cs" Inherits="DevKit.Web.test.charset._byte" %>
<%@ Page Language="C#" AutoEventWireup="true" ResponseEncoding="utf-8" CodeBehind="byte.aspx.cs" Inherits="DevKit.Web.test.charset._byte" %>
在aspx页面中手动指定meta标签
view plaincopy to clipboardprint?
- <meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
在后台cs文件中配置
view plaincopy to clipboardprint?
- Request.ContentEncoding = System.Text.Encoding.UTF8; //请求编码
- Response.ContentEncoding = System.Text.Encoding.UTF8; //响应编码
Request.ContentEncoding = System.Text.Encoding.UTF8; //请求编码 Response.ContentEncoding = System.Text.Encoding.UTF8; //响应编码
接下来,我们从几个示例中去体验乱码,从而总结出解决乱码的一般方法。
测试环境操作系统:Windows XP Professional SP3 雨林木风版
开发环境:Visual Studio 2008 专业版 + SP1(.NET 3.5)
Web容器:VS集成的Development Server
浏览器:IE8 、FireFox 5
实例分析与研究实例1 aspx页面提示意外的字符“XXX”,引号里面是乱码
背景
网站配置了在根目录配置了文件、请求、响应编码都为utf-8,页面成功编译,没有任务错误。详细错误见下图:

html代码
view plaincopy to clipboardprint?
- <div>
- aspx页面中的中文
- <br />后台的中文变量:<em><%=汽车%></em>
- </div>
<div> aspx页面中的中文 <br />后台的中文变量:<em><%=汽车%></em> </div>
后台代码
view plaincopy to clipboardprint?
- public partial class _byte : System.Web.UI.Page
- {
- protected string 汽车 = "我是凯迪拉克"; //别怀疑,中文变量是可以的:)
- protected void Page_Load(object sender, EventArgs e)
- {
- //...
- }
- }
public partial class _byte : System.Web.UI.Page { protected string 汽车 = "我是凯迪拉克"; //别怀疑,中文变量是可以的:) protected void Page_Load(object sender, EventArgs e) { //... } }
分析与解决
既然web.config已经配置了一样的请求响应编码,而且页面级别也没设置,可以排除这方面的问题了。注意到文件编码是UTF-8,会不是会文件编码引起的呢?(提示:这里的文件编码指的是保存文件时指定的编码,点击“另存为…”,在弹出的窗口中选择“编码保存”可以看到)。果然,此aspx页面的保存编码为GB2312,与web.config文件不一样,把它修改为UTF-8。
小提示:UTF-8有两种编码:UTF-8(带签名)和UTF-8(无签名)。带签名的UTF-8会在文件的开头写入“EF BB BF”(16进制),以标示自己采用的编码格式,这个标志称为BOM(Byte Order Mark),即字节序。打个比方,UTF-8(带签名)戴了校徽的学生,就算不认识他的人,一看校徽就明白了;而UTF-8(无签名)则是没戴校徽的。这里的校徽就是我们说的BOM,一个能够表明自己身份的标志。

小结
这是因为文件的保存编码与当前网站指定的文件编码不一致引起的,所以最佳实践是:手动在web.config中指定文件编码,并确保所有页面的保存编码与web.config一致。
其实最容易出这种问题的是js和css文件,如果你用其它工具(比如DreamWeaver)来编写这些文件却采用不同的编码保存,一旦文件包含中文就可能出这样的错误,导致js脚本错误,css无效!
实例2 跨页post提交时接收的Form数据变成了乱码
背景
有两个页面,注册页面(register.html)和处理注册的页面(handle.aspx),注册页面的表单信息以post方式提交到handle.aspx。根目录的配置的文件编码、请求编码和响应编码都是UTF-8。
register.html页面的关键html
view plaincopy to clipboardprint?
- <head>
- <title></title>
- <meta http-equiv="Content-Type" content="text/html;charset=gb2312" />
- </head>
- <body>
- <form id="form1" name="form1" action="handle.aspx" method="post">
- <input type="text" id="txtName" name="txtName" />
- <input type="submit" id="btnSubmit" value="Post" />
- </form>
<head> <title></title> <meta http-equiv="Content-Type" content="text/html;charset=gb2312" /> </head> <body> <form id="form1" name="form1" action="handle.aspx" method="post"> <input type="text" id="txtName" name="txtName" /> <input type="submit" id="btnSubmit" value="Post" /> </form>
handle.aspx页面关键后台代码
view plaincopy to clipboardprint?
- protected void Page_Load(object sender, EventArgs e)
- {
- string name = Request.Form["txtName"];
- Response.Write(name);
- }
protected void Page_Load(object sender, EventArgs e) { string name = Request.Form["txtName"]; Response.Write(name); }
错误信息如下
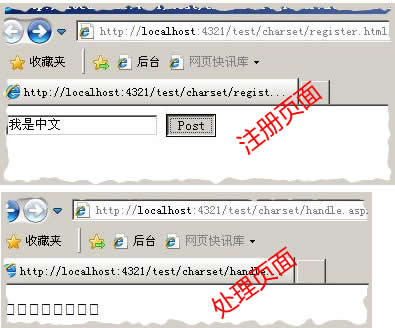
分析与解决
这是在提交表单信息过程产生的乱码,这里就涉及http请求和http响应的编码问题。我们上面说过,在请求时浏览器会把表单信息按指定编码转化成字节流发向Web服务器,在服务器ASP.NET会把这些字节流按指定的编码解码,以取得表单信息。那么我们就要检查这两个页面的编码了。仔细检查之后,发现register.html有这么一行“<meta http-equiv="Content-Type" content="text/html;charset=gb2312" />”,这里手动指定了页面编码为GB2312。问题很有可能就出在这里了,把本行删除之后,handle.aspx页面成功接收到表单信息。
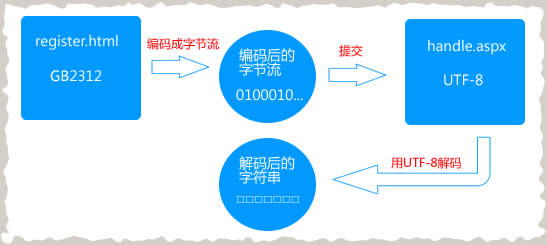
没错,这就是由于两个页面的编码不一样引起。让我们再深入一点,仔细看看问题是怎么一步一步产生的吧。register.html的编码为GB2312,当我们点击了“Post”按钮时,浏览器会把“我是中文”这几个字按GB2312的方式编码成字节流,然后提到到handle.aspx页面。handle.aspx没有手动指定编码,那么他将会采用web.config里面的配置,为UTF-8。它收到请求后,用UTF-8编码解码字符流。由于请求用的是GB2312,而接收用的却是UTF-8,这样就导致乱码的产生。通过下面这幅图可以看到这个过程。
小结
所有的页面(不管是aspx,还是html,或其它)都必须使用相同的编码。如果涉及跨页提交,不管是get还是post,更应该严格保持相关页面编码的一致性。特别是跨站点提交时,更应该注意!
实例3 cookie存取发生乱码
背景
这是一个旧项目,现在决定增加一个自动登录的功能。详细过程是这样的:
在登录页面,用户登录成功后把用户名写到cookie中。这样,当用户再次访问时,就可以根据cookie判定用户是否已登录,从而实现自动登录。
登录成功后cookie是这样保存的
view plaincopy to clipboardprint?
- string userName = "cookie大侠"; //待保存的用户名
- userName = HttpUtility.UrlEncode(userName); //编码特殊字符,如中文
- HttpCookie cookie = new HttpCookie("userName", userName);
- Response.Cookies.Add(cookie);
string userName = "cookie大侠"; //待保存的用户名 userName = HttpUtility.UrlEncode(userName); //编码特殊字符,如中文 HttpCookie cookie = new HttpCookie("userName", userName); Response.Cookies.Add(cookie);
判断用户是否已登录时,代码是这样的
view plaincopy to clipboardprint?
- string userName = Request.Cookies["userName"].Value;
- userName = Server.UrlDecode(userName);
- Response.Write(userName); //总是获取不到cookie,所以决定打印出来看看
string userName = Request.Cookies["userName"].Value; userName = Server.UrlDecode(userName); Response.Write(userName); //总是获取不到cookie,所以决定打印出来看看
结果在测试读取cookie的时候,页面输出了乱码,如下图:

分析与解决
全球化信息是这样配置的
<globalization fileEncoding="utf-8" requestEncoding="gb2312" responseEncoding="gb2312"/>
所有页面的保存编码都为UTF-8,请求响应编码是GB2312。再次声明,这是一个旧项目,任何改动都必须向后兼容。
首先从全球化配置里看到三种编码不一致,初步怀疑是这里引发的问题。尝试把请求、响应编码都修改为UTF-8,再次运行页面,乱码消失了。窃喜,小样,原来问题就在这里。但是,这样一来,在其它很多页面中却莫名其妙出现了乱码。这…,心里好不容易生起的一股小火,却被这样无情的浇灭了。冷静地回忆了下,自己只改了请求响应编码,其它地方没动过啊。于是改回来原来的GB2312,其它页面运行也正常了。如果把编码改为UTF-8的话,就不能兼容以前的页面,且会导致一连串的问题,全部修改将是一个非常艰巨的任务。
仔细检查了几遍所有页面的编码,都没有手动设置过,那应该都是读取配置文件的GB2312。新功能急于上线,交期一秒一秒狠狠地砸着绷紧的神经。怎么办呢?难道是GB2312不支持cookie存取吗?搜索了大量资料后,也没有发现什么端倪,感觉这也不太可能,毕竟中国这么多GB2312的网站…。
现在可以确定的是编码没有任何问题!那问题会出现在哪里呢?是自己写的代码有问题吗?仔细检查了之后,就发现了一点:
userName = HttpUtility.UrlEncode(userName); //编码特殊字符,如中文
userName = Server.UrlDecode(userName);
红色部分不一样,从智能提示中可以看到这样的说明。

原来,两个调用的是不同类的方法。一个是HttpUtility的方法,另一个是HttpServerUtility的方法,不小心还真看不出来。于是把Server.UrlEncode()换成了HttpUtility.UrlEncode(),重新运行测试页面,页面正常显示。既然都已经到这里了,我们不防看看这两个方法的实现细节有哪些差异吧。打开Reflector,找到System.Web.HttpUtility中的UrlEecode方法。嘿嘿,终于被我发现了这样一个片段(我把反射后的代码加上了注释):
view plaincopy to clipboardprint?
- //这是HttpUtility的UrlEncode方法
- public static string UrlEncode(string str)
- {
- if (str == null)
- {
- return null;
- }
- return UrlEncode(str, Encoding.UTF8); //默认采用UTF-8编码
- }
//这是HttpUtility的UrlEncode方法 public static string UrlEncode(string str) { if (str == null) { return null; } return UrlEncode(str, Encoding.UTF8); //默认采用UTF-8编码 }
接着看看HttpServerUtility.UrlDecode()方法, Page.Server其实是HttpServerUtility的一个实例,但它并不是在Page类中实例化的,而是在HttpContext中。
view plaincopy to clipboardprint?
- //HttpServerUtility中的UrlDecode方法
- public string UrlDecode(string s)
- {
- //注意这里的差异,会优先使用context中的编码,
- //也就是我们配置了的GB2312
- Encoding e = (this._context != null) ?
- this._context.Request.ContentEncoding : Encoding.UTF8;
- return HttpUtility.UrlDecode(s, e);
- }
//HttpServerUtility中的UrlDecode方法 public string UrlDecode(string s) { //注意这里的差异,会优先使用context中的编码, //也就是我们配置了的GB2312 Encoding e = (this._context != null) ? this._context.Request.ContentEncoding : Encoding.UTF8; return HttpUtility.UrlDecode(s, e); }
这下总算明白为什么了,存cookie时调用的是HttpUtility.Encode()方法,将以UTF-8编码。而读取时调用的是HttpServerUtility的Decode()方法,它会根据当前上下文采用GB2312方法,自然无法正确解析UTF-8编码的字符串了。
小结
在调用方法时,要成对调用。比如编码时调用的是HttpUtility.UrlEncode(),那么在解码时你就必须调用HttpUtility.UrlDecode(),保持这种一致性,有利于减少错误的发生。
必须充分考虑代码的向后兼容性。
如果你有兴趣,去看看微软是怎么实现这些方法的吧,这样对你的帮助会很大。
实例4 jQuery Ajax请求传中文参数导致乱码
背景
老项目(实例3提到的)的需求又来了,大致要求是这样的:在前台页面中,要根据当前商品的名称去异步获取它的详细说明(当然了,一般是按id等主键获取的,这里我只是做一个假设),当用户点击时就显示。于是决定用jQuery 的Ajax去做,简单方便且功能强大。由于jQuery的易用性,代码一下子就写好了,后台采用ashx处理ajax请求,先看看是怎么实现的吧。
前台页面的代码
view plaincopy to clipboardprint?
- <head runat="server">
- <title>产品列表页</title>
- <script src=\'#\'" /../js/jquery-1.4.2.js" type="text/javascript"></script>
- <script type="text/javascript">
- $(function() {
- $('#product').click(function() {
- var productName = this.innerHTML; //产品名称
- $.get('getInfo.ashx', { name: productName }, function(description) {
- alert(description); //显示详细说明
- });
- });
- });
- </script>
- </head>
- <body>
- <form id="form1" runat="server">
- <div>
- <a id="product" href="javascript:void(0);">奋斗牌牙膏</a>
- </div>
- </form>
- </body>
<head runat="server"> <title>产品列表页</title> <script src=\'#\'" /../js/jquery-1.4.2.js" type="text/javascript"></script> <script type="text/javascript"> $(function() { $('#product').click(function() { var productName = this.innerHTML; //产品名称 $.get('getInfo.ashx', { name: productName }, function(description) { alert(description); //显示详细说明 }); }); }); </script> </head> <body> <form id="form1" runat="server"> <div> <a id="product" href="javascript:void(0);">奋斗牌牙膏</a> </div> </form> </body>
ashx的关键处理代码
view plaincopy to clipboardprint?
- string name = context.Request.QueryString["name"];
- context.Response.Write(name + ": "); //调试用,看参数传递是否正确
- if (name != null && name.Trim() == "奋斗牌牙膏")
- {
- context.Response.Write("奋斗牌,你懂的!\n每天一点点,强身健体,天气再冷,牙也不颤!");
- }
string name = context.Request.QueryString["name"]; context.Response.Write(name + ": "); //调试用,看参数传递是否正确 if (name != null && name.Trim() == "奋斗牌牙膏") { context.Response.Write("奋斗牌,你懂的!\n每天一点点,强身健体,天气再冷,牙也不颤!"); }
但不幸的是,运行页面时又出乱码了,无法正确获取产品名称。

分析与解决
项目的所有配置还是和例3一样,请求响应编码都是GB2312。首先也是尝试把web.config文件的请求编码改为UTF-8,运行页面,可以正常显示。但这样改肯定是不行的,必须考虑其它页面的兼容性。有了例3的经验,现在已经知道问题出现在哪个部分了。必定是请求的编码和解析请求的编码不一致产生的!现在的重点是找出产生这个不一致的原因。
仔细检查了产品页面的编码,没任何任何与编码相关的设置,所以这个页面肯定也是用web.config中的请求编码GB2312。在ashx中也没有设置,它肯定也是用GB2312来解析请求。理论上应该不会出现乱码的啊。
为了能看清楚细节,打开抓包工具Fiddler,监测Ajax请求,看到的请求头是这样的。
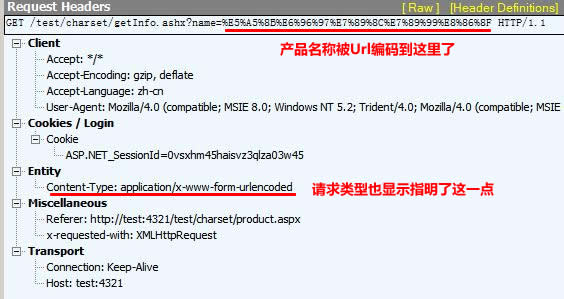
可以看到,$.get()方法自动把请求参数附加到url里,并且实施了url编码。所以我们就得$.get()这个方法入手,看看请求参数是如何被附加到url中的。打开jquery.1.4.2.js,一步一步查找,发现了这样一个方法:
view plaincopy to clipboardprint?
- function add( key, value ) {
- // If value is a function, invoke it and return its value
- value = jQuery.isFunction(value) ? value() : value;
- s[ s.length ] = encodeURIComponent(key) + "=" + encodeURIComponent(value);
- }
function add( key, value ) { // If value is a function, invoke it and return its value value = jQuery.isFunction(value) ? value() : value; s[ s.length ] = encodeURIComponent(key) + "=" + encodeURIComponent(value); }
原来是对参数调用了encodeURIComponent()方法来进行url编码的,但这个方法的实现细节是看不到的,不像.NET里可以反编译。在网上搜索了很多资料,但很少有资料提到它的工作细节。
好吧,我们就自己实践一下吧。还是用“奋斗牌牙膏”这几个字来测试,先看看用不同的字符编码来对它实行url编码后产生的字符串是什么吧。下面是我的测试结果:

把这些结果和Fiddler的抓包结果对比一下(看url中的参数),发现当采用UTF-8进行UrlEncode时,两者的结果是一致的。
可以确定encodeURIComponent()是采用UTF-8编码来进行url编码的。不仅仅是get方法,jQuery实现的所有ajax方法都是一样的,采用UTF-8字符编码对参数进行url编码。到这里,问题产生的原因已经很明朗了,请求的字节流采用了UTF-8编码,而服务器端的ASP.NET却采用GB2312来解析,肯定解析不到了。
因此,我们可以在ASP.NET中手动指明解析请求的编码。修改后的ashx代码如下:
view plaincopy to clipboardprint?
- context.Request.ContentEncoding = System.Text.Encoding.UTF8; //指明Request使用的编码是UTF-8
- string name = context.Request.QueryString["name"];
- context.Response.Write(name + ": "); //调试用,看参数传递是否正确
- if (name != null && name.Trim() == "奋斗牌牙膏")
- {
- context.Response.Write("奋斗牌,你懂的!\n每天一点点,强身健体,天气再冷,牙也不颤!");
- }
context.Request.ContentEncoding = System.Text.Encoding.UTF8; //指明Request使用的编码是UTF-8 string name = context.Request.QueryString["name"]; context.Response.Write(name + ": "); //调试用,看参数传递是否正确 if (name != null && name.Trim() == "奋斗牌牙膏") { context.Response.Write("奋斗牌,你懂的!\n每天一点点,强身健体,天气再冷,牙也不颤!"); }
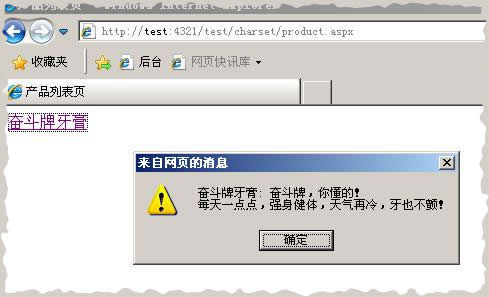
再次点击页面,成功返回所需的内容。
总结
使用jQuery的ajax方法时,一定要记得它是采用UTF-8编码数据的。
把http的请求响应过程弄清楚。
通过上面4个例子,你应该对乱码产生的原因有所了解了吧。记住一点,最根本的原因是字符编码不一致产生的。然后顺着这条线索,顺藤摸瓜,一步一步把确切的原因找出来。方法很重要,你不应该为了得到了答案而高兴,而应该真正弄懂问题产生的原因,这样你才能真正成长。这时体会一下“授人以鱼不如授人以渔”这句话的魅力吧。
后记其实问题真的不可怕,适当地来些问题,来些压力,会让你更好地成长。不要只是想得到答案,更重要的是积累获得答案的方法。
写这篇文章的过程中,遇到了不少问题,感谢那么多的前辈们分享了他们的经验,让我得以站在他们的肩膀上。
参考资料:
字符集与字符编码简介 http://blog.csdn.net/gogor/article/details/5323599
HTTP 请求报头详解 http://kuangbaoxu.iteye.com/blog/193352
encodeURIComponent()导致乱码解决 http://www.cnblogs.com/ahhi/archive/2009/09/30/1577118.html
unicode编码 http://baike.baidu.com/view/40801.htm