shared pool分析之结构
shared pool分析
解析SQL语句、生成执行计划、
解析SQL ------------|
|
|---需要考虑访问对象是否存在,权限时候具有等因素
生成执行计划--------|
|
执行SQL语
解析的过程是一个耗费资源的过程,随着用户的并发数量的增加。数据库的性能也会降低的很快。
在mysql中没有绑定变量的概念,在oracle中我们可以使用绑定变量来大幅减少我们的SQL解析次数。
ORCLE对解析的执行
1、ORACLE将SQL语句分成为两个部分
静态部分+动态部分
2、静态部分
SQL 语句的关键词
所涉及的表名称、列名称、等
3、动态部分
字面值(表里面的表数据)
例如 where name=‘ace’
那么where name是静态部分、ace是动态部分
静态部分是有限的、动态部分是无限的
在实际中,不同的SQL语句的静态部分的重复率非常的高、动态部分导致了SQL语句的千变万化
实际上,静态部分对SQL语句的解析的影响可以忽略不计,主要是动态部分
ORCLE将解析过的SQL语句缓存在shared pool中,碰到相同的SQL语句再次执行的时候,ORACLE直接使用已经解析过的执行计划。
Shared pool中缓存的内容包括
1、SQL语句
2、执行计划
3、PL/SQL代码
4、PL/SQL机器码等
通过使用绑定变量,用来提高SQL语句的缓存命中率
declare
v1 varchar2(10);
i1 int(10);
begin
i1:=1;
select name into v1 from dba_team where id=i1;
end;
/
在上面的SQL语句中,使用了绑定变量i1,在解析的时候,使用的绑定变量。执行的时候,将字面值传入语句中。因此这样SQL语句的命中率将会提高。
使用绑定变量是一个很好的思路。
在SQL语句中,更多的使用绑定变量、特别是大型的复杂SQL查询
Shared pool细分
1、库缓存
最近执行的SQL语句、存储过程、函数、解析树、执行计划
最活跃部分
2、数据字典缓存
SQL执行过程中涉及的数据字典
Shared Pool的内存结构(物理结构)
Shared pool由许多的内存块组成,这些内存块称为chunk
1、chunk是shared pool中内存分配的最小单元(类似于extent)
2、一个chunk在内存中是连续的
Chunk的分类
1、free:chunk中没有有效的对象,可以不受限制的分配
如果用于存放和SQL相关的数据,那么chunk就属于 library cache,如果用于存放数据字典,那么这个chunk就属于 dictionary cache
2、recr:recreatable,chunk里面包含的对象可以被临时性的移
走,如果需要,可以重建,例如共享SQL语句.上面例子中的i1解析完后就存放在这里。
3、freeabl:session用过这个trunk,里面存放的对象数据是session在处理过程中产生的,没有办法重建,这点不同于recr。因此这个chunk不能被临时性的移走。但是在合适的时间段(一般在seesion结束)可以被释放。
4、perm:permanent,chunk中包含永久性的对象,但是大型的permanent类型的chunk中可能包含可用空间,需要的时候,这些空间可以被释放。例如v$表的中参数。
查看当前数据库中正在使用的chunk,稍后我会抓取trace文件给大家展示下。
SQL> select count(*),KSMCHCLS from x$ksmsp group by KSMCHCLS;
COUNT(*) KSMCHCLS
---------- --------
14938 freeabl
30131 recr
54 R-freea
23 perm
27 R-free
2777 free
查看当前内存地址在使用哪个chunk
SQL> select ADDR,KSMCHCLS from x$ksmsp where rownum <10;
ADDR
KSMCHCLS
-------- --------
B6E35EAC freeabl
B6E35E74 freeabl
B6E35E3C freeabl
B6E35E04 recr
B6E35DCC recr
B6E35D94 recr
B6E35D5C freeabl
B6E35D24 freeabl
B6E35CEC freeabl
Shared pool中chunk的分配
1、shared pool中的chunk的大小是不一样的,但是肯定是连续的
2、因为chunk是分配的最小单元,因此session需要给对象分配空间的时候,会以chunk为单位进行申请
3、可用的chunk(free)会形成一个链表(free list,这个free list我们通常叫他bucket),便于进行分配的时候,可以通过遍历链表寻找到可用的适合的chunk,链表是chunk进行组织和管理的一种方式
4、一个可用的chunk链表是一个bucket,shared pool中会有很多的bucket,不同的bucket中的chunk的大小不同,一般是随着bucket编号的增加,bucket的大小是增长的
5、当需要从shared pool中寻找chunk的时候,首先会定位一个bucket(这个bucket有点特殊,session会优先定位和符合自己大小的bucket),然后向下遍历bucket,寻找最合适的chunk
如果chunk的空间比需要的空间大,那么这个chunk就拆分成两个,一个被分配、一个成为free,重新挂接到这个bucket上。
6、在寻找chunk的过程中,如果一个bucket中没有合适的chunk,接着寻找另外一个非空的bucket(在每一个bucket上寻找chunk都是从最小chunk开始),如果所有的bucket中都没有合适的chunk,那么就从rec类型的链表中释放一部分的空间。记住只有recreatetable可以被释放。
如果rec中还找不到那就会出现ORA-4013错误。
7、shared pool中所有类型的chunk都是以链表的方式进行管理的
对于上面第4点,我通过抓取trace内存块分析一下,只做简单分析,之后会回trace文件:
alter session set events 'immediate trace name heapdump level 2';
你的转储文件在 udump 目录下.根据日期和时间来查找,也可以根据进程号码来查找.以后再介绍.
这个文件是当前内存的信息,信息量巨大,下面只摘取我们需要的内容。
之前见到的chunk类型分布
HEAP DUMP heap name="sga heap(1,0)" desc=0x2001a948
extent sz=0xfc4 alt=108 het=32767 rec=9 flg=-126 opc=0
parent=(nil) owner=(nil) nex=(nil) xsz=0x400000
EXTENT 0 addr=0x3cc00000
Chunk 3cc00038 sz= 24 R-freeable "reserved stoppe"
Chunk 3cc00050 sz= 212888 R-free " "
Chunk 3cc33fe8 sz= 24 R-freeable "reserved stoppe"
Chunk 3cc34000 sz= 3975024 perm "perm " alo=3975024
Chunk 3cffe770 sz= 4064 perm "perm " alo=4064
Chunk 3cfff750 sz= 2224 free " "
EXTENT 1 addr=0x3d000000
Chunk 3d000038 sz= 24 R-freeable "reserved stoppe"
Chunk 3d000050 sz= 212888 R-free " "
Chunk 3d033fe8 sz= 24 R-freeable "reserved stoppe"
Chunk 3d034000 sz= 2097168 perm "perm " alo=2097168
Chunk 3d234010 sz= 1883412 perm "perm " alo=1883412
Chunk 3d3ffd24 sz= 732 free " "
第4点中我们说到的free list也就是bucket
Total heap size = 50330976
FREE LISTS: ---------千万别把这个FREE LIST和bucket混淆,这个只是trace文件的标示。方便阅读下面有哪个bucket,bucket才是第4点中讲的free list。
Bucket 0 size=16
Bucket 1 size=20
Bucket 2 size=24
Bucket 3 size=28
Bucket 4 size=32
Bucket 5 size=36
Bucket 6 size=40
Bucket 7 size=44
Bucket 8 size=48
Bucket 9 size=52
Bucket 10 size=56
Bucket 11 size=60
Bucket 12 size=64
Bucket 13 size=68
Chunk 3effffbc sz= 68 free " "-----第5点中提到的chunk的拆分
Bucket 14 size=72
Bucket 15 size=76
Bucket 16 size=80
Bucket 17 size=84
Bucket 18 size=88
Bucket 19 size=92
Bucket 20 size=96
Bucket 21 size=100
Bucket 22 size=104
Bucket 23 size=108
Bucket 24 size=112
Bucket 25 size=116
Bucket 26 size=120
Bucket 27 size=124
Bucket 28 size=128
Bucket 29 size=132
Bucket 30 size=136
Bucket 31 size=140
Bucket 32 size=144
Bucket 33 size=148
Bucket 34 size=152
Bucket 35 size=156
Bucket 36 size=160
Bucket 37 size=164
Bucket 38 size=168
Bucket 39 size=172
Bucket 40 size=176
Bucket 41 size=180
Bucket 42 size=184
Bucket 43 size=188
Bucket 44 size=192
Bucket 45 size=196
Bucket 46 size=200
Bucket 47 size=204
Bucket 48 size=208
Bucket 49 size=212
Bucket 50 size=216
Bucket 51 size=220
Bucket 52 size=224
Bucket 53 size=228
Bucket 54 size=232
Bucket 55 size=236
Bucket 56 size=240
Bucket 57 size=244
Bucket 58 size=248
Bucket 59 size=252
Bucket 60 size=256
Bucket 61 size=260
Bucket 62 size=264
Bucket 63 size=268
Bucket 64 size=272
Bucket 65 size=276
Bucket 66 size=280
Bucket 67 size=284
Bucket 68 size=288
Bucket 69 size=292
Bucket 70 size=296
Bucket 71 size=300
Bucket 72 size=304
Bucket 73 size=308
Bucket 74 size=312
Bucket 75 size=316
Chunk 3dfffec4 sz= 316 free " "
Bucket 76 size=320
Bucket 77 size=324
Bucket 78 size=328
Bucket 79 size=332
Bucket 80 size=336
Bucket 81 size=340
Bucket 82 size=344
Bucket 83 size=348
Bucket 84 size=352
Bucket 85 size=356
Bucket 86 size=360
Bucket 87 size=364
Bucket 88 size=368
经典错误赏析:
ORA-4013
当某个chunk正在被使用时(可能是用户正在使用,也可能是使用了dbms_shared_pool包将对象钉在shared pool里),该chunk是不能被移出内存的。
比如某个SQL语句正在执行,那么该SQL语句所对应的游标对象是不能被移出内存的,该SQL语句所引用的表、索引等对象所占用的chunk也是不能被移出内存的。
当shared pool中无法找到足够大小的所需内存时,报ORA-4031错。
当出现4031错的时候,你查询v$sgastat里可用的shared pool空间时,可能会发现name为“free memory”的可用内存还足够大,但是为何还是会报4031错呢?
事实上,在oracle发出4031错之前,已经释放了不少recreatable类型的chunk了,因此会产生不少可用内存。但是这些可用chunk中,没有一个chunk是能够以连续的物理内存提供所需要的内存空间的,从而才会发出4031的错。
shared pool latch的争用问题
只有rec类型的chunk能够被释放空间,即使释放了空间,这些空间可能都不是连续的,都是一些很小的chunk,这样可能形成这样一种情况,shared pool中是大量的非常小的chunk,
这样在寻找chunk的时候,也很难寻找到合适的chunk,同时因为free chunk数量非常的多,因此在分配chunk的时候,就会占用大量的时间,
因为对bucket进行扫描、管理、分配的时候,需要获得shared pool latch,如果小的chunk太多,在扫描free chunk的时候,shared pool latch会被锁定很长的时间,占用太多的时间,自然会发生latch争用的情况,原因就是因为大量的小的free chunk的情况
注意:如果在shared pool中出现了大量的小的free chunk,就会出现share pool latch争用的情况,
而如果增加shared pool尺寸的话,仅仅是延缓shared pool latch的争用,而到最后,就会因为小的free chunks的数量越来越多,争用也会越来越严重。
而到了9i以后,由于大大增加了可用chunk链表(也就是bucket)的数量,同时,每个bucket所管理的可用chunk的尺寸递增的幅度非常小,于是就可以有效的将可用的chunk都均匀的分布在所有的bucket上。这样的结果就是每个bucket上所挂的free类型的chunk都不多,所以在查找可用chunk而持有shared pool latch的时间也可以缩短很多。
shared pool对于大对象的处理
对于非常大的对象,oracle会为它们单独从保留区域里分配空间,而不是从这个可用chunk链表中来分配空间。
这部分空间的大小尺寸就是由初始化参数shared_pool_reserved_size决定的,缺省为shared_pool_size的5%,
这块保留区域与正常的chunk的管理是完全分开的,小的chunk不会进入这块保留区域,而这块保留区域的可用chunk也不会挂在bucket上。
这块保留区域的使用情况可以从视图v$shared_pool_reserved中看到,通常来说,该视图的request_misses字段显示了需要从保留区域的可用链表上上获得大的chunk而不能获得的次数,该字段应该尽量为0, 如果大于零,需要增加此区域大小。
通俗的说这块区域是session全部bucket都找不到以后,被逼急了才来这里找,但是这块空间就想武术里面的七伤拳,每取一次都自伤一次。所以就算加大了这块空间,这只是暂时解决问题,需要从业务逻辑才上可以根本解决问题。
SQL> select REQUEST_MISSES from v$shared_pool_reserved;
REQUEST_MISSES
--------------
0
Shared Pool的内存结构 (逻辑结构)
从一个逻辑层面来看,shared pool由library cache和dictionary cache组成。shared pool中组件之间的关系可以用下图一来表示。
从下面这个图中可以看到,当SQL语句(select object_id,object_name from sharedpool_test)进入library cache时,
oracle会到dictionary cache中去找与sharedpool_test表有关的数据字典信息,比如表名、表的列等,以及用户权限等信息。
如果发现dictionary cache中没有这些信息,则会将system表空间里的数据字典信息调入buffer cache内存,读取内存数据块里的数据字典内容,
然后将这些读取出来的数据字典内容按照行的形式放入dictionary cache里,从而构造出dc_tables之类的对象。
然后,再从dictionary cache中的行数据中取出有关的列信息放入library cache中。

library cache 和dictionary cache概述
library cache最主要的功能就是存放用户提交的SQL语句、SQL语句相关的解析树(解析树也就是对SQL语句中所涉及到的所有对象的展现)、执行计划、用户提交的PL/SQL程序块(包括匿名程序块、存储过程、包、函数等)以及它们转换后能够被oracle执行的代码等。
为了对这些内存结构进行管理,还存放了很多控制结构,包括lock、pin、dependency table(从属表)等。
library cache还存放了很多的数据库对象的信息,包括表、索引等等。有关这些数据库对象的信息都是从dictionary cache中获得的。
如果用户对library cache中的对象信息进行了修改,则这些修改会返回到dictionary cache中。
在library cache中存放的所有的信息单元都叫做对象(object),这些对象可以分成两类:
一类叫存储对象,也就是上面所说的数据库对象。它们是通过显式的SQL语句或PL/SQL程序创建出来的,如果要删除它们,也必须通过显示的SQL命令进行删除。这类对象包括表、视图、索引、包、函数等等;(上图中的黄色区域)
另一类叫做过渡对象,也就是上面所说的用户提交的SQL语句或者提交的PL/SQL程序块等。这些过渡对象是在执行SQL语句或PL/SQL程序的过程中产生的,并缓存在内存里。如果实例关闭则删除,或者由于内存不足而被交换出去,从而被删除。(上图中的红色区域)
父子游标
当用户提交SQL语句或PL/SQL程序块到oracle的shared pool以后,在library cache中生成的一个可执行的对象,这个对象就叫做游标(cursor)。
不要把这里的游标与标准SQL(ANSI SQL)的游标混淆起来了,标准SQL的游标是指返回多条记录的SQL形式,需要定义、打开、关闭。
下面所说到的游标如无特别说明,都是指library cache中的可执行的对象。
游标是可以被所有进程共享的,也就是说如果100个进程都执行相同的SQL语句,那么这100个进程都可以同时使用该SQL语句所产生的游标,从而节省了内存。
每个游标都是由library cache中的两个或多个对象所体现的,至少两个对象。
一个对象叫做父游标(parent cursor),包含游标的名称以及其他独立于提交用户的信息。从v$sqlarea视图里看到的都是有关父游标的信息;v$sqlarea中VERSION_COUNT字段是表示父子关系的子游标v$sql(子游标具体信息)是没有这个字段的
另外一个或多个对象叫做子游标(child cursors),如果SQL文本相同,但是可能提交SQL语句的用户不同,或者用户提交的SQL语句所涉及到的对象为同名词等,都有可能生成不同的子游标。
因为这些SQL语句的文本虽然完全一样,但是上下文环境却不一样,因此这样的SQL语句不是一个可执行的对象,必须细化为多个子游标后才能够执行。子游标含有执行计划或者PL/SQL对象的程序代码块等。
子游标可以通过v$sql查看。
父游标里面包含的信息包括SQL文本和优化目标
session打开该游标以后,就会锁定父游标
所有的session都关闭该游标以后,锁定才能够释放
父游标在被锁定的时候,不能被交换出内存
父游标交换出内存、子游标也会被交换出内存
子游标被交换出内存、父游标可以不被交换出内存
因为一个父游标可能会有多个子游标
子游标包换所有的信息:执行计划、绑定变量等
子游标随时可能被交换出内存
Oracle根据父游标的信息可以构建出一个子游标,这个过程叫reload
Hash 算法
Oracle在内部管理中大量的使用到了hash
1、使用hash的目的就是为了快速查找和定位
对数值进行hash运算,产生一个索引号,然后根据索引号将数值放置到相应的hash bucket中去
根据hash运算的法则,会产生多个索引号,每一个索引号对应一个hash bucket(一个数值列)
我们在寻找数值的时候,将搜寻的数值进行hash,产生一个索引号,那么这个数值一定在这个索引号对应的 hash bucket中,于是直接跳转到这个hash bucket中进行遍历。这样我们定位数据的时候,就能够大大的减少遍历的数量。
举例:
1.假设我们的数值列表最多可以有10个元素,也就是有10个hash buckets,每个元素最多可以包含20个数值。
2.则对应的二维数组就是t[10][20]。我们可以定义hash算法为n MOD 10。
3.通过这种算法,可以将所有进入的数据均匀放在10个hash bucket里面,hash bucket编号从0到9。
4.我们把1到100都通过这个hash函数均匀放到这10个hash bucket里,当查找32在哪里时,只要将32 MOD 10等于2,这样就知道可以到2号hash bucket里去找,也就是到t[2][20]里去找,2号hash bucket里有10个数值,逐个比较2号hash bucket里是否存在32就可以了
库缓存中就是使用hash bucket来管理的
1、首先根据shared_pool_size指定的尺寸来自动计算hash bucket的个数
2、每个hash bucket后面都串连着多个句柄(该句柄叫做library cache object handle),这些句柄描述了library cache里的对象的一些属性,包括名称、标记、指向对象所处的内存地址的指针等。可以用下图来描述library cache的整体结构
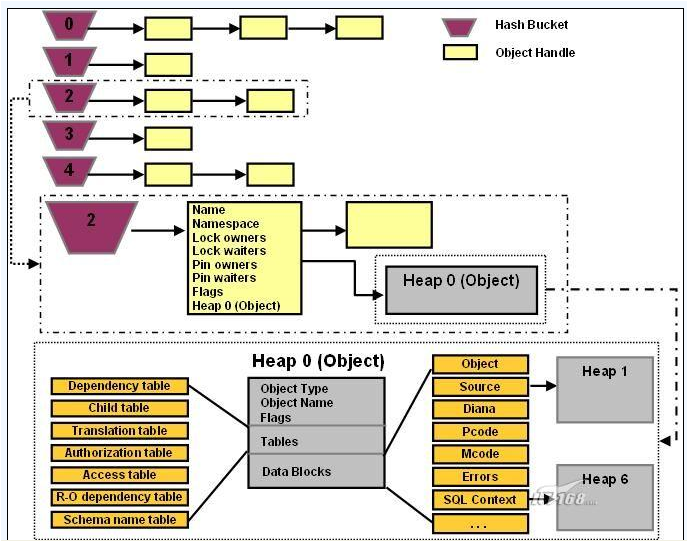
注意:hash bucket就是一个索引号,通过hash bucket对所有的对象进行了分类,分成多个对象链条
在寻找对象的时候,首先根据hash 函数计算出索引号,一定会进入一个hash bucket中
在hash bucket后面是一些句柄,句柄里面是具体的信息,这些信息没有经过hash计算,通过遍历这些句柄,如果对象在这个bucket上,那么就找到,否则说明对象没有在shared pool中,需要创建一个对象,同时将句柄挂接到这个hash bucket上
在寻找对象的时候,可能发现句柄在,但是对象却被换出了内存,怎么办?很简单,将对象重新加载到内存就可以了
可以使用下面的方式来确定reload的比率:
SQL> select 100*sum(RELOADS)/sum(PINS) RELOAD from v$librarycache;
RELOAD
----------
.973957894
我们可以通过查询v$db_object_cache来显示library cache中有哪些对象被缓存,以及这些对象的大小尺寸。
比如,我们可以用下面的SQL语句来显示每个namespace中,大小尺寸排在前3名的对象:
select *
from (select row_number() over(partition by namespace order by sharable_mem desc) size_rank,
namespace,
sharable_mem,
substr(name, 1, 50) name
from v$db_object_cache
order by sharable_mem desc)
where size_rank <= 3
order by namespace, size_rank
/
当一条SQL语句进入library cache的时候,
先将SQL文本转化为对应ASCII数值,然后对该这些ASCII数值进行hash函数的运算,
传入函数的是SQL语句的名称(name,对于SQL语句来说其name就是SQL语句的文本)以及命名空间(namespace,对于SQL语句来说是“SQL AREA”,表示共享游标。可以从视图v$librarycache里找到所有的namespace)。
运用hash函数后得到一个值,该值就是hash bucket的号码,从而该SQL语句被分配到该号的hash bucket里去。
实际上,hash bucket就是通过串连起来的对象句柄才体现出来的,它本身是一个逻辑上的概念,是一个逻辑组,而不像对象是一个具体的实体。
oracle根据shared_pool_size所指定的shared pool尺寸自动计算hash buckets的个数,shared pool越大,则可以挂载的对象句柄就越多。
当某个进程需要处理某个对象时,比如处理一条新进入的SQL语句时,它会对该SQL语句应用hash函数算法,以决定其所在的hash bucket的编号,
然后进入该hash bucket进行扫描并比较。有可能会发生该对象的句柄存在,但是句柄所指向的对象已经被交换出内存的情况出现。
这时对应的对象必须被再次装载(reload)。也可能该对象的句柄都不存在,这时进程必须重新构建一个对象句柄挂到hash bucket上,然后再重新装载对象。
SQL语句相关的对象有很多(最直观的就是SQL语句的文本),这些对象都存放在library cache里,它们都通过句柄来访问。
可以把library cache理解为一本书,而SQL语句的对象就是书中的页,而句柄就是目录,通过目录可以快速定位到指定内容的页。
SQL> select distinct NAMESPACE from v$librarycache;
NAMESPACE
---------------
BODY
JAVA DATA
SQL AREA -----共享游标(包含父子)
OBJECT
PIPE
JAVA RESOURCE
TABLE/PROCEDURE
TRIGGER
INDEX
JAVA SOURCE
CLUSTER
11 rows selected.