shell脚本实现系统监视统计与数据备份
知识内容:
*管理统计信息
*执行备份
*管理用户
对于linux SA来说,没啥比shell脚本编程更有用的了。linux系统每天都有很多任务需要做好,从监视系统
磁盘空间、系统用户到备份系统重要文件。通过shell脚本可以使得工作变得非常轻松和高效!
1、监视系统统计信息
确保系统的正常运行是linux SA的核心任务之一,这就需要通过创建shell脚本来监视多种不同的系统的统计信息,甚至不需要人工干预、半夜三更执行系统脚本。
1.1、必须函数
要自动监视系统的磁盘空间,首先要使用可以显示磁盘空间使用情况的命令df:
[root@wzp ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda3 7033724 4463456 2207200 67% /
/dev/sda1 101086 11301 84566 12% /boot
tmpfs 257700 0 257700 0% /dev/shm
这里头我主要提取根目录磁盘使用率即可,即67%这个数据。
这样一来,我们就需要使用shell来灵活提取这个数据了:
首先我们必须把第二行提取出来,之后再提取67%这个数据,所以我们一步一步来分析。
由于磁盘空间使用情况的数据都是变化的,唯独不变的就是文件系统/dev/sda3和最后的/,所以我们有两种方式提取出这一行:
[root@wzp ~]# df | sed -n '/\/dev\/sda3/p'
/dev/sda3 7033724 4463456 2207200 67% /
要知道,对于正斜杠需要通过转义的,把含有/dev/sda3文本匹配行输出到STDOUT
[root@wzp ~]# df | sed -n '/\/$/p'
/dev/sda3 7033724 4463456 2207200 67% /
我们知道这一行唯独以根(/)符号结尾,所以可以把以根(/)符号结尾的行提取出来
通过如上任意一种方法,我们都做好了第一步的准备,接着就是把67%提取出来,要知道,这个67的数据可以一直处于改变之中,所以不可以使用67这个关键数据。很明显,对于这个数据放置第五位,所以通过$5很容易就把数据提取出来了:
[root@wzp ~]# df | sed -n '/\/$/p' | gawk '{print $5}'
67%
[root@wzp ~]# df | sed -n '/\/dev\/sda3/p' | gawk '{print $5}'
67%
通过借用gawk把第五位置的数据提取,到了这里应该不难处理了,就是去掉%符号:
[root@wzp ~]# df | sed -n '/\/$/p' | gawk '{print $5}' | sed 's/%//'
67
[root@wzp ~]# df | sed -n '/\/dev\/sda3/p' | gawk '{print $5}' | sed 's/%//'
67
OK了,到这里已经实现了我们的要求,可以动态提取根目录磁盘使用情况了。
1.2、创建脚本
上面已经知道如何获取磁盘空间使用情况数据,接下来就是创建脚本了
[root@wzp ~]# cat diskmonitor
#!/bin/bash
# monitor available disk space
space=`df | sed -n '/\/dev\/sda3/p' | gawk '{print $5}' | sed 's/%//'`
if [ $space -gt 90 ];then
echo "Disk space on root at $space% used" | mail -s "Disk warning"
else
echo "The disk space is used $space%" | mail -s "Disk space is enought"
fi
通过此脚本实现当根目录磁盘使用率超过90%的时候自动发报警邮件信息给root
1.3、运行脚本
[root@wzp ~]# chmod +x diskmonitor
通过给脚本赋予执行权限,然后借用crontab计划任务实现脚本定时运行
[root@wzp ~]# crontab -l
30 0,12 * * * /root/diskmonitor
实现脚本每天凌晨12点30分和中午12点30分分别执行一次脚本
2、监控磁盘资源
2.1、必须函数
如果说linux服务器上有许多用户,特别是一些文件服务器(ftp、samba),就必须对磁盘资源做好监控。
默认情况下,系统用户一般只对自家目录有存放资源的权限,所以就必须对/home目录下做数据统计:
首先可以联想到的命令应该是du了:
[root@wzp ~]# du -s /home/*
7100 /home/51cto
18684 /home/mysql
90236 /home/www
通过du命令可以很清楚的了解到各个用户自家目录磁盘使用情况(前面的数据单位是KB)
如果说/home目录下有lost+found的话可以通过grep -v lost+found来过滤掉。
接下来我们主要是提取数据和用户名,也就是说可以把/home/给去掉,做法很简单:
[root@wzp ~]# du -s /home/* | sed 's/\/home\///'
7100 51cto
18684 mysql
90236 www
为了更好的显示磁盘资源使用情况的报表,可以先对数据结果做一个排序:
[root@wzp ~]# du -s /home/* | sed 's/\/home\///' | sort -g -r
90236 www
18684 mysql
7100 51cto
通过sort -g -r(-g表示将所有数据排序;-r表示按照降序排序)实现所占磁盘空间从大到小排序。对了,还有一条就是所有用户所占磁盘总量:
[root@wzp ~]# du -s /home
116028 /home
2.2、创建脚本
通过借用临时目录创建的临时文件,将数据报表以头部、报告主体、尾部的形式显示:
[root@wzp ~]# cat diskuse
#!/bin/bash
# calculate disk usage and report per user
TEMP=`mktemp -t tmp.XXXXXX`
du -s /home/* | sed 's/\/home\///' | sort -g -r > $TEMP
total=`du -s /home | gawk '{print $1}'`
cat $TEMP | gawk -v n="$total" '
BEGIN {
print "total disk usage by user";
print "user\tspace\tpercent"
}
{
printf "%s\t%d\t%6.2f%\n", $2, $1, ($1/n)*100
}
END {
print "-------------------";
printf "total\t%d\n", n
}'
rm -f $temp
[root@wzp ~]# ./diskuse
total disk usage by user
user space percent
www 90236 77.77%
mysql 18684 16.10%
51cto 7100 6.12%
-------------------
total 116028
3、监视CPU和内存使用情况
通过编写shell脚本实现对PU和内存使用情况的监控
3.1、必需函数
linux下有几个命令可以从系统中提取出CPU或内存的使用情况,如top、uptime、free等
[root@wzp ~]# uptime
12:45:02 up 1:29, 1 user, load average: 0.00, 0.00, 0.00
uptime命令可以给出一些信息点:
* 当前时间
* 系统已经运行的时间
* 当前已经登录到系统的用户个数
* 1、5和15分钟的系统负载平均值
另一个提取系统信息的命令vmstat:
[root@wzp ~]# vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 419176 22980 46652 0 0 23 5 554 16 0 1 98 1 0
如上显示为上次重新引导的平均值,如果要获取当前统计信息,可以使用vmstat 1 2 :
[root@wzp ~]# vmstat 1 2
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 419176 22980 46652 0 0 23 5 554 16 0 1 98 1 0
0 0 0 419176 22980 46652 0 0 0 0 1064 16 0 0 100 0 0
第二行包含linux系统的当前统计信息,如果是vmstat 1则一直动态显示系统当前信息。
对于如上的符号做一个简单介绍:
r: 等待CPU时间的进程数
b: 不间断休眠中的进程数
swpd: 使用的虚拟内存量(以MB为单位)
free: 未使用的物理内存量(以MB为单位)
buff: 用作缓存空间的内存量(以MB为单位)
cache: 用作高速缓存空间的内存量(以MB为单位)
si: 从磁盘交换的内存量(以MB为单位)
so: 交换到磁盘的内存量(以MB为单位)
bi: 从块设备收到的块数
bo: 发送到块设备的块数
in: 每秒CPU的中断数
cs: 每秒CPU的上下文交换数
us: CPU消耗在运行非内核代码上的时间百分比
sy: CPU消耗在运行内核代码上的时间百分比
id: CPU空间的时间百分比
wa: CPU消耗的在等待I/O上的时间百分比
st: 从虚拟机窃取的CPU时间百分比
接下来通过vmstat 1 2 和 uptime命令,从中提取相关参数来编写获取数据的脚本:
[root@wzp ~]# touch capstats
[root@wzp ~]# cat capstats
#!/bin/bash
# script to capture system statistics
OUTFILE=/root/capstats.csv
DATE=`date +%Y/%d/%m`
TIME=`date +%k:%M:%S`
TIMEOUT=`uptime`
USERS=`echo $TIMEOUT | gawk '{print $4}'`
LOAD=`echo $TIMEOUT | gawk '{print $9}' | sed 's/,//'`
FREE=`vmstat 1 2 | sed -n '4p' | gawk '{print $4}'`
IDLE=`vmstat 1 2 | sed -n '4p' | gawk '{print $15}'`
echo "$DATE,$TIME,$USERS,$LOAD,$FREE,$IDLE" >> $OUTFILE
如上脚本主要提取vmstat 1 2 和 uptime命令中的相关数据,还有系统的当前时间
[root@wzp ~]# date +%Y/%d/%m
2011/11/05
[root@wzp ~]# date +%k:%M:%S
22:15:47
如上通过date命令来获取时间,具体时间的格式可以通过date --help来了解
echo $TIMEOUT | gawk '{print $4}'可以获取当前登录到系统的用户个数
echo $TIMEOUT | gawk '{print $9}' | sed 's/,//'可以获取当前系统5分钟内的平均负载
vmstat 1 2 | sed -n '4p' | gawk '{print $15}'可以获取系统未使用的物理内存量
vmstat 1 2 | sed -n '4p' | gawk '{print $15}'可以获取系统CPU空间的时间百分比
然后把获取到的数据重定向到/root/capstats.csv中,实现对系统CPU和内存使用情况的获取
然后赋予脚本可执行 权限:
[root@wzp ~]# chmod +x capstats
通过计划任务实现系统每分钟获取一次数据:
[root@wzp ~]# crontab -l
*/1 * * * * /root/capstats
[root@wzp ~]# cat capstats.csv
2011/11/05,22:10:01,2,0.01,319224,92
2011/11/05,22:11:01,2,0.00,319100,98
2011/11/05,22:12:01,2,0.00,319224,99
2011/11/05,22:13:01,2,0.00,319100,99
......
可以看到该文件一直收集着系统CPU和内存使用情况的数据。
3.2、生成报告脚本
上面已经通过脚本capstats生成了数据文件capstats.csv,接下来就是通过这个数据文件capstats.csv来生
成index.html页面了,这里头就需要一点html基础了,看如下脚本:
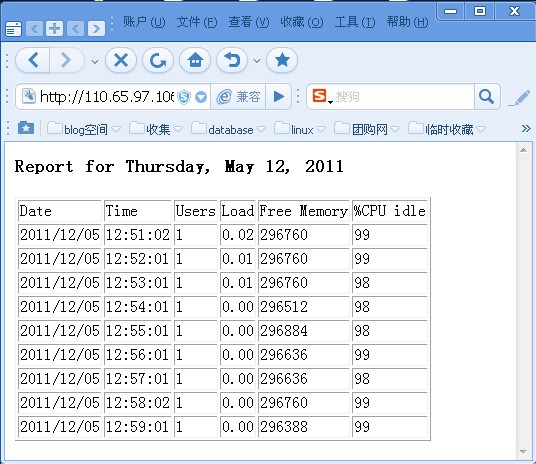
[root@wzp ~]# cat report
#!/bin/bash
# parse capstats data into daily report
FILE=/root/capstats.csv
TEMP=/usr/local/nginx/server4/index.html
DATE=`date +"%A, %B %d, %Y"`
echo "<html><body><h3>Report for $DATE</h3>" > $TEMP
echo "<tableborder=\"1\">" >> $TEMP
echo "<tr><td>Date</td><td>Time</td><td>Users</td>" >> $TEMP
echo "<td>Load</td><td>Free Memory</td><td>%CPU idle</td></tr>" >> $TEMP
cat $FILE | gawk -F, '{
printf "<tr><td>%s</td><td>%s</td><td>%s</td>", $1, $2, $3;
printf "<td>%s</td><td>%s</td><td>%s</td>\n</tr>\n", $4, $5, $6;
}' >> $TEMP
echo "</table></body></html>" >> $TEMP
通过该脚本把从capstats.csv收集到的数据处理成静态页面,然后通过Nginx服务来预览。
[root@wzp ~]# date +"%A, %B %d, %Y"
Thursday, May 12, 2011
这里点跟上面一致,获取指定格式的当前日期。
对于echo部分,主要就是生成静态页面的标准格式,对于这部分:
cat $FILE | gawk -F, '{
printf "<tr><td>%s</td><td>%s</td><td>%s</td>", $1, $2, $3;
printf "<td>%s</td><td>%s</td><td>%s</td>\n</tr>\n", $4, $5, $6;
}' >> $TEMP
这是最为关键的地方,表示从数据文件capstats.csv中提取数据,然后把$1,$2,$3,$4,$5,$6逐一替代指定位
置的%s,实际上这两行可以写成一行的!
再往下就是通过计划任务实现每15分钟处理一次数据,然后生成静态页面,即可用浏览器预览了。
[root@wzp ~]# crontab -l
*/15 * * * * /root/report
再者启动Nginx服务:
[root@wzp ~]# /usr/local/nginx/sbin/nginx
然后通过浏览器浏览,在linux下:
[root@wzp ~]# links http://110.65.97.106/
即可看到生成的关于系统性能的数据。
4、执行备份
备份本身是一个很大的概念,涉及到的东西也是非常多。对于这一部分内容仅仅对系统文件的备份,主要通过脚本实现对系统文件的自动化增量备份。还有一个就是将备份文件依旧放置原系统磁盘文件上,简单实现防止文件被破坏或意外删除的风险。
4.1、必需函数
在linux下,归档数据时最常用的命令是tar,对其具体的用法可以tar --help了解,下面举个例子:
[root@wzp ~]# du -s backdir/
744 backdir/
[root@wzp ~]# tar -cf back.tar backdir/
[root@wzp ~]# ll back.tar
-rw-r--r-- 1 root root 757760 May 12 21:30 back.tar
如上把backdir目录归档成一个.tar压缩文件
接下来就是要对生成的归档文件做数据压缩了,linux下常用的gzip命令
[root@wzp ~]# gzip back.tar
[root@wzp ~]# ll back
backdir/ back.tar.gz
[root@wzp ~]# ll back.tar.gz
-rw-r--r-- 1 root root 748514 May 12 21:30 back.tar.gz
通过如上的tar和gzip命令实现对一个目录做了归档和数据压缩,最终形成.tar.gz后缀的压缩文件对于.tar.gz后缀的压缩文件可以通过tar zxvf解压缩
(z表解压gz包;x表解压缩;v表显示过程;f表解压文件;-C表解压到指定的目录下)
[root@wzp ~]# tar zxvf back.tar.gz -C /home/www/
backdir/
backdir/imagick-3.0.0.tgz
backdir/nginx-1.0.0.tar.gz
[root@wzp ~]# du -s /home/www/backdir/
744 /home/www/backdir/
通过上面实现归档数据和压缩的方法,往下就可以编写脚本实现自动化了
4.2、创建日常归档脚本
[root@wzp ~]# cat backupscript
#!/bin/bash
# archive a working directory
DAY=`date +%d`
MONTH=`date +%m`
TIME=`date +%H%M`
SOURCE=/root/etc/httpd
DESTDIR=/tmp
mkdir -p $DESTDIR/$MONTH/$DAY
DESTINATION=$DESTDIR/$MONTH/$DAY/archive$TIME
tar -czvPf $DESTDIR/$MONTH/$DAY/archive$TIME.tar.gz $SOURCE
对于如上脚本,主要实现把/root/etc/httpd该目录进行定期的压缩备份,并且通过指定具体时间的目录名称
,方便后期的数据整理和查看。
[root@wzp ~]# chmod +x backupscript
[root@wzp ~]# ./backupscript
/root/etc/httpd/
/root/etc/httpd/logs
/root/etc/httpd/conf/
/root/etc/httpd/conf/httpd.conf
/root/etc/httpd/conf/magic
/root/etc/httpd/run
/root/etc/httpd/conf.d/
/root/etc/httpd/conf.d/README
/root/etc/httpd/conf.d/proxy_ajp.conf
/root/etc/httpd/conf.d/welcome.conf
/root/etc/httpd/conf.d/python.conf
/root/etc/httpd/conf.d/php.conf
/root/etc/httpd/conf.d/perl.conf
/root/etc/httpd/conf.d/manual.conf
/root/etc/httpd/conf.d/squid.conf
/root/etc/httpd/conf.d/webalizer.conf
/root/etc/httpd/conf.d/ssl.conf
/root/etc/httpd/modules
如果不显示归档过程可以把-v去掉。
[root@wzp ~]# date
Mon May 16 13:39:10 CST 2011
[root@wzp ~]# ll /tmp/05/16/
total 48
-rw-r--r-- 1 root root 47805 May 16 13:39 archive1339.tar.gz
由此我们可以很方便的通过日期寻找指定时间的备份文件
接下来对该备份文件进行解压:
[root@wzp 16]# pwd
/tmp/05/16
[root@wzp 16]# tar zxvf archive1339.tar.gz
/root/etc/httpd/
tar: Removing leading `/' from member names
/root/etc/httpd/logs
/root/etc/httpd/conf/
/root/etc/httpd/conf/httpd.conf
/root/etc/httpd/conf/magic
/root/etc/httpd/archive1333.tar.gz
/root/etc/httpd/run
/root/etc/httpd/conf.d/
/root/etc/httpd/conf.d/README
/root/etc/httpd/conf.d/proxy_ajp.conf
/root/etc/httpd/conf.d/welcome.conf
/root/etc/httpd/conf.d/python.conf
/root/etc/httpd/conf.d/php.conf
/root/etc/httpd/conf.d/perl.conf
/root/etc/httpd/conf.d/manual.conf
/root/etc/httpd/conf.d/squid.conf
/root/etc/httpd/conf.d/webalizer.conf
/root/etc/httpd/conf.d/ssl.conf
/root/etc/httpd/modules
这里你会发现出现了一行报错信息:
tar: Removing leading `/' from member names
说是移除了/,不过之所以这么做主要是为了安全起见(理解不了就百度)
因为对于备份文件需要解压回来使用的时候,会放置于原来的位置而覆盖原目录下所有内容。通过拿掉根目
录使得压缩后采用了相对路径,避免旧的文件覆盖的新的文件
[root@wzp 16]# ll
total 52
-rw-r--r-- 1 root root 47805 May 16 13:39 archive1339.tar.gz
drwxr-xr-x 3 root root 4096 May 16 13:40 root
从这里我们也看到了我们备份的原目录是/root/etc/httpd
解压后被去掉了第一个/就变成了root
[root@wzp 16]# tree root/
root/
`-- etc
`-- httpd
|-- archive1333.tar.gz
|-- conf
| |-- httpd.conf
| `-- magic
|-- conf.d
| |-- README
| |-- manual.conf
| |-- perl.conf
| |-- php.conf
| |-- proxy_ajp.conf
| |-- python.conf
| |-- squid.conf
| |-- ssl.conf
| |-- webalizer.conf
| `-- welcome.conf
|-- logs -> ../../var/log/httpd
|-- modules -> ../../usr/lib/httpd/modules
`-- run -> ../../var/run
4 directories, 16 files
[root@wzp 16]# du -s root/etc/httpd/
112 root/etc/httpd/
[root@wzp 16]# du -s /root/etc/httpd/
112 /root/etc/httpd/
原文件和解压后的文件大小内容完全一致
最后就是通过cron实现该脚本的定期运行实现指定的数据的backup了!!