架构
一、先从J2EE工程的通用架构说起

这是一个通用的Web即B/S工程的架构,它由:
ü Web Server
ü App Server
ü DB Server
三大部分组成,其中:
Web Server
置于企业防火墙外,这个防火墙,大家可以认为是一个CISCO路由器,然后在CISCO路由器上开放了两个端口为:80和443。
80端口:用于正常的http访问
443端口:用于https访问,即如果你在ie里打入https://xxx.xxx.xx这样的地址,默认
走的是443这个端口。
WebServer专门:
用于解析HTML、JS(JavaScript)、CSS、JPG/GIF等图片格式文件、TXT、
VBSCRIPT、PHP等一切一切“静态”网页内容。
App Server
置于企业防火墙内,它和Web Server之间的连接必须且一定为内部IP连接。
外部IP:即Internet IP地址,我们的web服务器一般会有一个内部IP一个外部IP,因此在这里,我们的App Server没有任何外部IP,只有内部IP,所以我在这边说App Server与Web Server只能以内部IP形式连接。
打比方说我们用的是tomcat,它的端口为8080,那么这个ip地址上的8080端口只能由任何内部ip才能访问,外部的internet是访问不了的,这样做就是为了安全。
App Server用于解析我们的任何需要Java编译器才能解析的“动态”网页,其实App Server本身也能解析任何静态网页的。
那么我们这样来想一下:
我们让负责专门解析静态网页的Web Server来解析html等内容,而让App Server专门用于解析任何需要Java编译器才能解析的东西,让它们“两人”各司其职。这样作的好处:
1) 为App Server“减压”,同时也提高了performance
2) 不用再把8080这个端口暴露在internet上了,也很安全,必经我们的app server上可是有我们的代码的,就算是编译过的代码也容易被“反编译”,这是很不安全的。
3) 为将来的进一步的“集群扩展”打好了基础
DB Server
打比方说我们用的是Oracle,它需要通过1521与App Server进行连接是不是?那么这个1521我们称为数据库连接端口,如果把它暴露在Internet上,是不是在危险了点?就算我们的密码很复杂,但对于高明的黑客来说,要攻破你的口令也只是时间上的问题而己。
因此我们把我们的DB Server也和App Server一样,置于内网的防火墙。任何的DB连接与管理只能通过内网即在公司企业内部来访问,就是这个道理。
二、动手来架构
2.1 Oracle数据加的安装与配置
DB(Oracle)我已经为大家准备好了,连接信息为:
IP: |
10.225.10x.xx |
Port: |
1521 |
Username/Password: |
xxx/xxx |
Sid: |
Jcoedb1 |
url: |
jdbc:oracle:thin:@10.225.10x.xx:1521:xxx |
所以,根据上述的架构,我们可以把如下这样的一份清单丢给NSS或者是相关的网络管理部门,让他们给我们开通相应的端口:
Web Server |
对外IP: xxx.xxx.xxx.xxx 向internet开通80与443端口 |
App Server |
对内IP: 10.225.xxx.xxx 只对10.225.段的ip开放8080,8009等端口, |
Db Server |
对内IP: 10.225.xxx.xxx 只对10.225.段的ip开放1521端口 |
2.2 App Server的安装
直接解压tomcat至你的本地如:d:\tomcat,我这边用的目录名叫tomcat2,大家随意,最好名字能够越简单越好d:\tomcat或者c:\tomcat就行,不要放得太“深”。
2.3 Web Server的安装
我们在这边将安装Apache For Win 2.2.x,它将占用你机器的80和443端口。因此如果你机器上有任何程序占用你的80和443端口,必须将它关闭掉,比如说:
我们装有微软的IIS,这本身也是一个WebServer,那么请你将它关闭:
ControlPanel->Administrative Tools->Service,找到IISAdmin和,将它全部关闭并将启动方式设为:manual以便于不用每次重启后再要去手动关闭一下。
然后用netstat �Cano找到任何还在占用80端口的程序,将它关闭掉。
2.4 开始安装Apache Http Server
我们将安装这个版本的apache http server作为我们今后一直使用的Web Server
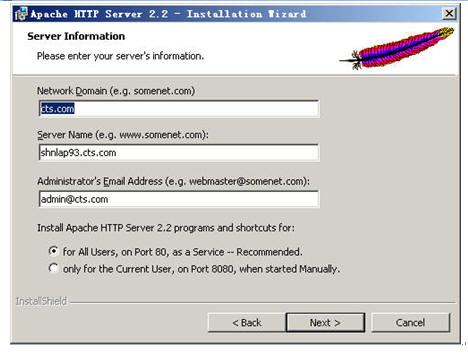
这边的server name你们要填入自己的server的真实名,不能用我这个,这个servername如:shnlap93.cts.com只能够我用,这个名称是全局唯一的,和你的IP一样。
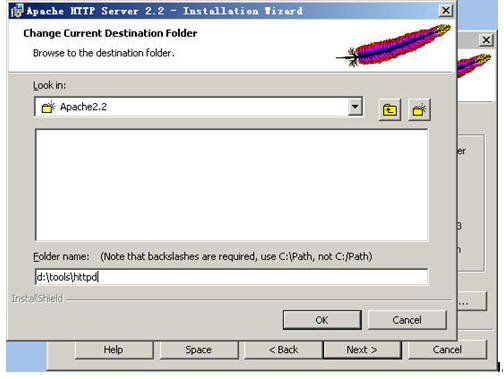

选全部安装

装完后你会多出一个这样的图标来,点击该图标,里面有用于控制apache http server的启动、停止与重启等操作选项。同时在你们的“服务”面板中,也能发现这样的一个服务项,它启动时默认是随着系统的启动而启动的,我们把它改成“手动”吧,因为将来我们还要安装IBM Http Server来作练习。
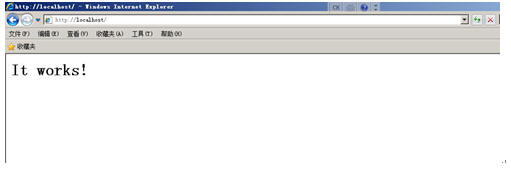
装完后,在Apache2.2启动的前提下,打开一个ie输入http://localhost,你将会得到这样的一个页面,就说明你的Apache的安装是成功的。
2.5 Apache的配置
学Java的人,必须会这个Apache的配置,要不然你怎么模拟环境、搭建环境和架构环境?光会Coding是远远不够的,你将永远只配作个码农。。。嘿嘿嘿!有很多人发觉到了后面JAVA学不上去了,关键因素在于:配置。
你会配环境了,那么你就能模拟任何客户方、开发方的环境。
你会配环境了,你的代码将来上线时才能成功运行。
你会配环境了,所以整个工程的技术核心就是你。
跟着我的教程,你们将会安装和运行达近百个各种软件与配置,搞得你一股臭味一股臭味!!
你准备好了没有?
当然,不用怕,因为我的配置都是实际运行的环境,所以网上的一些东西你可以不用去看,因为很多人都是在网上进行拷贝、复制,有时也不经过验证,会让你走很多的弯路到头来还是落得个BUG一天世界,就看我的教程吧。
Apache的配置主要集中在httpd.conf文件,它位于你的安装目录,比如:
D:\tools\httpd\conf\
我们用ultraedit或者相关文本编辑工具打开它,来看它的内容:
先来查找到如下这一行:
#ServerName
我们可以得到如下这一行内容:
#ServerName shnlap93.cts.com:80 |
这就是我们的主机名了,我们可以将前面的“#”去掉,并将其改为:
ServerName 10.225.106.35:80 |
改完后存盘,在重启你的Apache2.2前我们先测试一下我们的Apache的配置文件是否改得对:
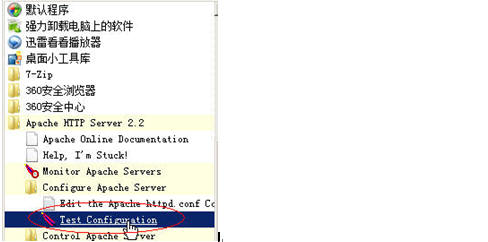
如果在你点了Test Configuration后,黑屏一闪而过,说明你的改动无误,否则这个黑屏会一直停留在当前状态,并且告诉你,你的配置改动有错,错在哪里。
重新启动你的Apache
找到如下这行:
DocumentRoot
你会发下有这样的一行内容:
DocumentRoot "D:/tools/httpd/htdocs" |
这个叫作DocumentRoot即webroot,即:发布目录,发布在这个目录下的任何工程都会在Apache服务开启时被装载成标准的web工程,我们现在动手来把这个WebRoot定位到我们自己的发布目录中去吧。
DocumentRoot "d:/www" |
我们把它改到了d盘的www目录中去了,然后我们在该目录中放入一个index.html文件,内容为:
<html><body><h1>Hey man, apache works!</h1></body></html> |
重启我们的Apache服务,来测试一下:

嘿嘿,我们得到了什么?禁止访问,为什么?
找到下面这一段:
<Directory /> Options FollowSymLinks AllowOverride None Order deny,allow deny from all </Directory> |
看到了没?
现在,把这个”deny from all”改成”allow fromall’吧。
<Directory /> Options FollowSymLinks AllowOverride None Order deny,allow allow from all </Directory> |
修改完后重启你的Apache服务

Ok,我们的Apache的发布目录已经成功更改到了d:\www目录下了,我们再来做一个实验:
我们在IE浏览器中输入: http://localhost/css/,我们看到了什么?
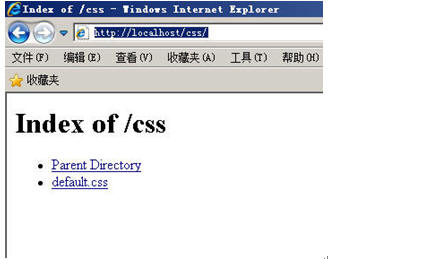
这还了得,用户如果是个初级黑客都可以知道我们的服务器上有哪些文件,哪些目录甚至可以直接看到我们的文件内容,怎么办?
找到下面这行
Options FollowSymLinks indexes |
把它注掉改成下面这样
#Options FollowSymLinks indexes Options None |
不要急,再往下找,还有
Options Indexes FollowSymLinks |
又来一个,再改掉
#Options Indexes FollowSymLinks Options None |
改完这两条后重启你的Apache服务
再次打开一个新的IE,输入:http://localhost/css/,我们看到了如下的界面:

好了,Apache的基本配置完成了即:
1) 基本的安全配置,不允许目录访问
2) 把WebRoot改到另一个物理目录上而不使用Apache自带的WebRoot目录
2.6 整合Apache与Tomcat
Apache(Web Server)负责处理HTML静态内容;
Tomcat(App Server)负责处理动态内容;
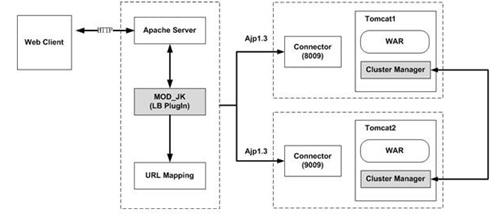
其实就是上述这样的一个架构,下面是原理
1) Apache装有一个模块,这个模块叫mod_jk
2) Apache通过80端口负责解析任何静态web内容
3) 任何不能解析的内容,用表达式告诉mod_jk,让mod_jk派发给相关的app server去解释。
通过上述的文字描述我们可以得知:
1) 我们需要在Apache中先装一个mod_jk
2) 我们需要在httpd.conf中写点表达式
下面来实现。
1) 把mod_jk-1.2.31-httpd-2.2.3.so手工copy进我们的Apache安装目录的modules目录下,这个文件的全名叫: mod_jk-1.2.31-httpd-2.2.3.so,大家可以从ftp上的“/JavaArchitect/mod_jk/”目录中获取,因为这个文件是我用C++在本地重新编译过的,网上下载的是src即源码,省去大家再去编译的时间了,而且一些其它网上下载的mod_jk.so是无法使用的。
2) 用ultraedit打开httpd.conf文件,跑到文件最后面加入以下几行:
LoadModule jk_module modules/mod_jk-1.2.31-httpd-2.2.3.so JKWorkersFile conf/workers.properties JkLogFile logs/mod_jk.log <VirtualHost *> ServerAdmin localhost DocumentRoot d:/www/ ServerName localhost DirectoryIndex index.html index.htm index.jsp index.action ErrorLog logs/shsc-error_log.txt CustomLog logs/shsc-access_log.txt common JkMount /*WEB-INF ajp13 JkMount /*j_spring_security_check ajp13 JkMount /*.action ajp13 JkMount /servlet/* ajp13 JkMount /*.jsp ajp13 JkMount /*.do ajp13 JkMount /*.action ajp13 JkMount /*fckeditor/editor/filemanager/connectors/*.* ajp13 JkMount /fckeditor/editor/filemanager/connectors/* ajp13 </VirtualHost> |
关键的是这两句:
LoadModule jk_module modules/mod_jk-1.2.31-httpd-2.2.3.so
JKWorkersFile conf/workers.properties
代表:
ü Apache载入一个额外的插件,用于连接tomcat。
ü 连接时的配置参数描述位于Apache安装目录的/conf目录下的一个叫workers.properties文件中,mod_jk一般使用ajp13协议连接,使用的是tomcat的8009端口。
3) Worker.properties文件内容如下:
workers.tomcat_home=d:/tomcat2 workers.java_home=C:/jdk1.6.32 ps=/ worker.list=ajp13 worker.ajp13.port=8009 worker.ajp13.host=localhost worker.ajp13.type=ajp13 |
4) 告诉我们的Apache,哪些是要交给tomcat来解析,除此之外都由Apache本身来解析:
<VirtualHost *> ServerAdmin localhost DocumentRoot d:/www/ ServerName localhost DirectoryIndex index.html index.htm index.jsp index.action ErrorLog logs/shsc-error_log.txt CustomLog logs/shsc-access_log.txt common JkMount /*WEB-INF ajp13 JkMount /*j_spring_security_check ajp13 JkMount /*.action ajp13 JkMount /servlet/* ajp13 JkMount /*.jsp ajp13 JkMount /*.do ajp13 JkMount /*.action ajp13 JkMount /*fckeditor/editor/filemanager/connectors/*.* ajp13 JkMount /fckeditor/editor/filemanager/connectors/* ajp13 </VirtualHost> |
大家看到没,所有的/servlet/*都由tomcat负责解析,所有的jsp, .do, .action都由tomcat解析。
此处还有一个特殊的/fckeditor,这个是我们使用的一个博客编辑器,这个因为是servlet的,因此也需要交给tomcat铁析。
5) 将/cbbs工程布署到tomcat的webapps目录下
6) 将/cbbs同样手工copy一份到d:/www目录下
7) 删除d:/www/cbbs/WEB-INF这个目录,嘿嘿,因为d:/www下的东西是由Apache解析的,所有的WEB-INF下的都是Java,我们只需要布署在tomcat下即可,是不是?
8) 重启tomcat,重启Apache,在ie中直接输入: http://localhost/cbbs,使用sally/abcdefg登录,操作一下,一切成功
Oh…yeah, tomcat+apache一步搞定。
三、用于实验的cbbs工程配置
最后附上cbbs布署需要用到的配置,相关的工程可通过ftp的” /Java Architect/Project/”下的cbbs.zip来获取。
ü 在tomcat中打开server.xml加入:
<Resource driverClassName="oracle.jdbc.OracleDriver" factory="org.apache.commons.dbcp.BasicDataSourceFactory" maxActive="25" maxIdle="100" maxWait="5000" name="jdbc/eltds" password="xxx" type="javax.sql.DataSource" url="jdbc:oracle:thin:@10.225.101.51:1521:jcoedb1" username="xxx"/> |
和
<Context crossContext="true" docBase="D:/upload" path="/uploadpic" reloadable="true"/> <Context docBase="cbbs" path="/cbbs" reloadable="true"/> |
ü 手工在d盘根目录建立一个upload目录,在此目录内再建立一个image目录。
ü 在tomcat中打开context.xml加入
<ResourceLink name="jdbc/cbbsds" type="javax.sql.DataSource" global="jdbc/cbbsds"/> |
在前一天的学习中我们知道、了解并掌握了Web Server结合App Server是怎么样的一种架构,并且亲手通过Apache的Http Server与Tomcat6进行了整合的实验。
这样的架构的好处在于:
ü 减轻App Server端的压力,用Web Server来分压,即Web Server只负责处理静态HTML内容,而App Server专职负责处理Java请求,这对系统的performance是一个极大的提升。
ü 安全,Web Server端没有任何Java源代码包括编译后的东西,对Internet开放的只有Web Server,因此黑客就算通过80端口攻入了我们的Web Server,他能得到什么?除了静态HTML内容,任何逻辑,口令他都得不到,为什么?喏。。。因为我们的App Server“躲”在Web Server的屁股后面呢。
需要注意的地方:
ü 如果以这样的架构出现,你的J2EE 工程,必须在web.xml里把那些个<servlet-mapping>划分清楚,比如说:
我们可以知道*.do, *.action, *.jsp是属于JAVA需要解析的东西对吧!
但是,如果你的servlet写成这样
/abc
/123
/def
那么当我们在作映射时,需要把/abc, /123, /def分别写成一行行的JKMount语句,是不是。。。OK,假设我们这个工程有100个servlet(这个算少的哦),你该不会在httpd.conf文件中给我写这样的无聊的东西100行吧?
所以,我们在规划我们的servlet时需要有矩可循,即pattern,因此我才一直强调,大家在servlet命名时必须统一成:
/servlet/myServletabc
这样,我在做这个Web Server到App Server的Mapping时,是不是只要一句:JkMount /servlet/* ajp13就可以搞定啦?
ü 同样的架构有不同的变种:
IIS+Tomcat
因为微软的IIS本身就是一个Web Server,因此通过IIS和Tomcat的一个插件叫”isapi”的也可以作到这样的架构,但是我强烈不推荐,因为JAVA源于Unix系统,归于Unix系统,Unix可是不认什么IIS的,一定请一定用Apache,你是JAVA不是多奶(dot net)。
Apache+Weblogic
IBM HttpServer(Apache的一个变种)+IBM WAS6.x/WAS7.X
Tomcat集群
Apache挂N多个tomcat,由tomcat1…tomcat2…tomcat3…等组成
Weblogic集群
Apache挂N多个weblogic,由weblogic1…weblogic2…weblogic3…等组成
WASND(IBMWebsphere App Server Network Deployment)
IBM HttpServer挂N多个WAS,由WAS1…WAS2…WAS3…等组成
二、HTTPS
2.1 HTTPS介绍
先来看HTTPS的概念

我们一般的http走的是80端口,而https走的是443端口,有什么不一样的地方吗?
很简单,我们拿个telnet命令来作个实验:
telnet127.0.0.1 80,直接就登进了80端口(如果你机器上的Apache开放的话),这样好极了,所有的http中的get, put, post全部可以被我们截获,你的上网帐号,你提交的表单信息全部被别人拦截,就算你对一些信息加了密,对于黑客来说,这些加密被解密只是时间问题,而且一般黑客可以利用云计算,群集计算对你的加密可以进行“硬杀伤”,即穷举算法,利用超大规模集群解密的你的算法会很快,电影里的几十秒解开一个128位的加密不是神话,是真的!!!
因此,我们要让黑客一开始就攻不进来,连门都进不来,何谈拿到我里面的东西,对不对?
现在我们把我的http通道,变成了https,同时关闭80端口,因此用用户要访问必须经过443端口。好了,我们再来用:
telnet localhost 443
你连telnet都进不进去,因此,你就无法再获取http通道内传输的东西了。因此黑客要进入你的网站先要突破这个https,而https使用的是RSA非对称128位加密,如果是安全交易类甚至会使用RSA 1024位加密算法,除非是世界上最高明的黑客才能突破我们的防线。
2.2 HTTPS的构成
要构成HTTPS,我们需要有一张“根证书”,一张“服务器认证”才能做到一般的https,HTTPS还分成“双向认证”,在双向认证的结构中我们需要3张证书即“根证书”,“服务器认证”,“客户端认证”。为什么需要这么多证书?嘿嘿,下面我们来看HTTPS是怎么构成这个“信任关系链”的。
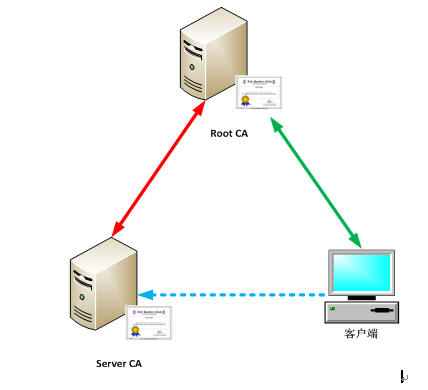
ü 证书我们称为CA;
ü 根证书叫Root CA;
上述这个图什么意思?
首先,RootCA是全球的根,这个“树”的根是全球任何IE、FireFox、Safari里的证书库里都有这个RootCA的,因为它们是权威,所以全球的电子证书拿它们做“根”,这些证书比较具有代表性的是:
ü Verisign
ü RSA
这两家公司是世界上所有加密算法的“鼻祖”,因此被拜为全球所信任,我们可以在我们的IE中看到这些“根”。

其此,全球的计算器客户默认在装完系统后,都会带有这些ROOT CA,因此“由ROOT CA签出来的服务器证书将自动被客户端所信任”。
所以,这个信任关系,就此建立。
在HTTPS是SSL的一种,它们间是如何进行加密传输的呢,就是这个“信任关系”,先建立起信任关系,然后再开始数据传输,在加密的世界中“建立信任”就需要用到至少2张证书,即ROOT CA, SERVER CA,我们把这个信任建立的过程称为“Hands Shake”,握手协议。
前面说到了,这个握手分单向和双向,包括上述这个图就是一个单向握手,什么叫单向,什么叫双向呢?我们下面来讲解:
ü 单向握手信任
我们又称它为“包二奶协议”,大家想一下,贪官包二奶和二奶说“你跟着我,我每月给你1万块”,他说的这个话,能不能写下来? 能吗? 当然不能,写下来还得了,将来二奶一不爽把这份白纸黑字的东西交到中纪委还不把这烂货给双规了哈?
所以,二奶单向里信任贪官,这就是二奶协议,即客户端认为我访问的这台服务器“是安全的”,因此客户端可以向服务器发送和提交任何东西。
ü 双向握手信任
我们又称它为“君子协定”,呵呵,从这个词表面上来看就知道这个协议有多牢靠了,首先,它是写在字面上的,其次,双方都签署协议这个信任关系怎么样啊? 非常牢靠!
即客户端信任服务器,因此客户端可以向服务器发送和提交任何东西。同时,服务器也信任客户端,允许该客户端向我发送和提交东西。

客户端单向信任服务器很简单,只要这个服务器是我客户端信任的顶级根签发出来的证书就行,而服务器如何信任客户端呢?记住下面三句话:
首先,你这个客户端到我这边来登记一下;
其次,我给你签一张证书,你带回家装在你的IE里;
最后,每次访问时因为你的IE里装着我服务器签出的证书,所以你是我的会员,所以我信任你;
2.3 证书与如何生成证书的基本概念
通过上面的概念,我们知道了,如果建立起这个HTTPS的环境我们需要至少一张服务器证书,对不对?而且这张服务器证书是需要由客户端信任的“ROOT”级机构所签发出来的。
所以一般生成证书由以下几个步骤构成:
1. 生成一对不对称密钥,即公钥public key和私钥 private key
2. 用密钥产生请求,同时把我的请求交给ROOT机构
3. ROOT机构对我提交的请求进行“签名”Sign
这个被签完名后的“请求”就称为证书。
上面多出来了密钥,公钥,私钥三个名词,下面来做解释。
先来看一个真理:
1)密钥,密钥为一对,即一把公钥,一把私钥
2)一把私钥可以对应多把公钥,而这些公钥只可能来源于一把私钥
3)公钥加密,私钥解密
大家想一下,公钥加密,这是“公”就是人人有这把KEY,都可以用来加密,但是能打开我这扇门的因该只有一个人是吧?这就是为什么说“私钥”解密。

倒过来
私钥“加密”(被称为签名),公钥“解密”(被称为认证)

把上面这个“真理”倒过来,呵呵,好玩了,因为public key只能用来加密而解密必须是private key,因此公钥是不能加密的,公钥也不能用来解密,那么它们该怎么做?
HP公司是卖打印机的,它有100个代理,都为它销售打印机。
客户来到了某个代理公司,问:你凭什么说你是HP的代理
代理公司说:请看,这是HP公司给我证书
客户问:你的证书不能伪造吗?
代理公司答:请看,下面有一个防伪条形码
于是,客户把这个防伪条形码用手机拍下来,来到HP公司说:这是不是你们的代理?
HP公司说:你等一下! 随后HP公司拿出以前给这家代理公司的公钥,对这个签名做一个“解密”(被称为杂凑算法),也算出来一个防伪条形码,然后拿这个防伪条形码和客户带来的防伪条形码一比较,完全一致,所以HP和客户说:您可以完全相信这家公司,这家公司是我代理的。
这边这个防伪条形码就是代理公司用HP在颁发证书时给它时用HP的私钥的“签名”;
HP公司用为当初给代理商发放证书时同时生成的密钥对里的公钥对这个签个名做一个杂凑算法,然后拿算出来的防伪条形码再和客户带来的这个防伪条形码比对的这个过程被称为“认证”;
一起来看看证书里的防伪条形码吧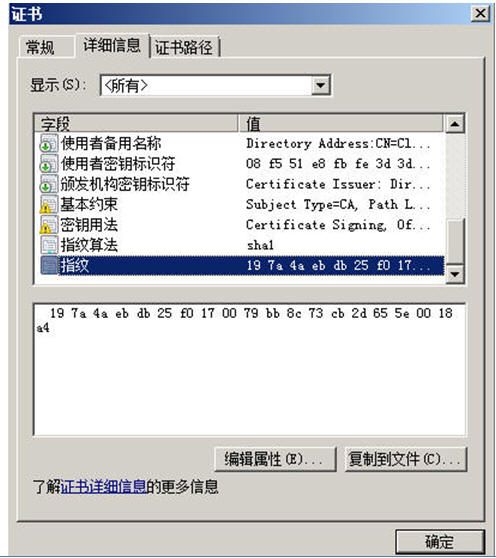
我们把它称为电子“指纹”,一般用的是SHA或者是MD5算法,因为MD5和SHA是不可逆唯一性算法,所以把它比喻成“指纹”再恰当不过了。
2.4 实际开发实验中如何产生证书
实际产生证书时,我们需要生成请求,但不是说我们把请求交给Verisign或者一些信息机构,它们就帮我们签的,这是要收费的,一般签个名:50-500美金不等,有时还分为每年必须去签一次,要不然就会失效。
所以我们在实际开发环境中,为了做实验或者是搭建模拟环境,不可能会去花钱买个证书的,有时我们环境要搭建几套,怎么办?这钱花的没有明堂的。
所以,在实际开发环境中,我们自己来模拟这个ROOTCA,然后用自己模拟出来的ROOTCA去签我们服务器的证书,这个过程就被称为“自签”。
2.5 使用OpenSSL来签证书
OpenSSL就是这么一个自签,加密的命令行工具,它是从UNIX下分离出来的一个项目,但也有FOR WINDOWS平台的,比如说我给你们用的这个OPENSSL,就是For WIN的,但是由于它是从UNIX/LINUX下产生的,因此它内部的配置还是用的是LINUX/UNIX的盘符与路径,需要手动去校正,当然我已经做好了校正,因此直接打了个压缩包放在了FTP上,大家拿下来后解压后就可以直接用了。
如果你们是自己从网上官方网站下载的OPENSSL需要手动去改它的盘符和路径,要不然是用不起来的。
ü 设置环境变量
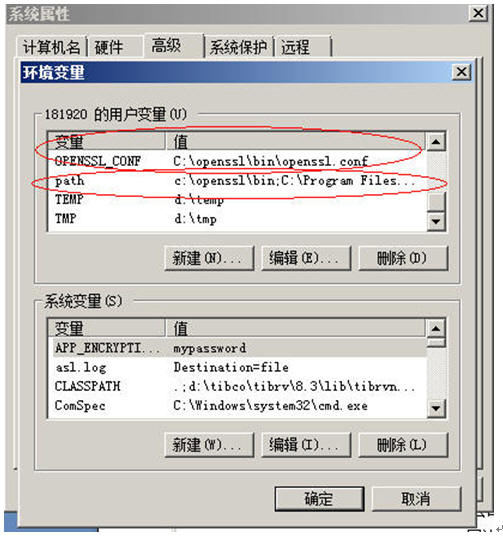
把c:\openssl\bin\openssl.cnf设成OPENSSL_CONF这样的一个变量,同时把c:\openssl\bin目录加到你的path里去(根据你们自己的解压后的openssl的实际路径)。
ü 生成根证书所用的密钥
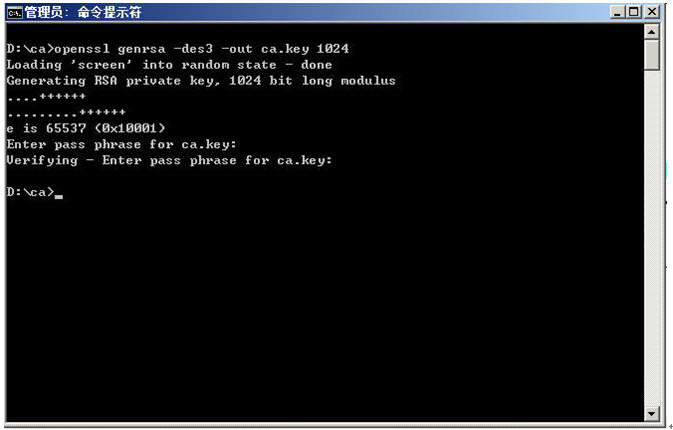
提示输入密码我们使用:aaaaaa
再次输入确认密码
(密钥,由其是private key是由口令保护的)
去除CA密钥的口令
为什么我们要把好好的口令保护给去除呢?这边不是去除而是代表这个证书在被应用程序启动时不需要显示的提示用户输入口令,要不然我们会出现下面这种情况:
在启动HTTPS协议的服务器时,一般我们点一下service->apache2.x启动,就启动了,但如果这个https所带的证书是没有经过上述这道手续后处理的话,这个服务在启动时会失败,而需要切换成手动命令行启动,就是黑屏!在黑屏状态下,apache2.x服务器启动时会提示你要求:输入口令,这个太麻烦了,一般启动服务器服务的一定是超级管理员,因此一般情况下没必要在启动相关服务时再输入一遍口令了。
ü 生成CA即ROOT CA证书并自签
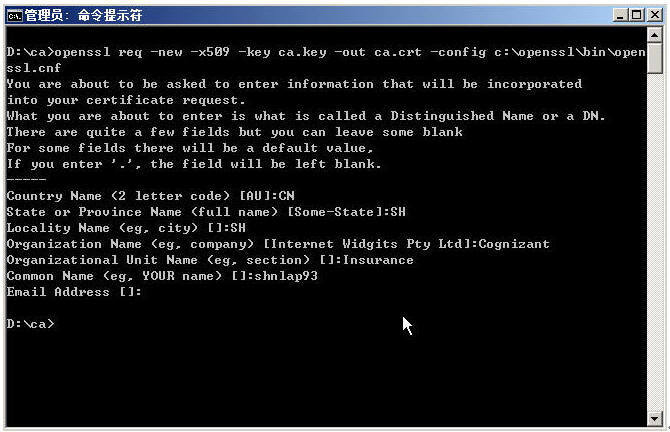
网上有很多说法,说是先产生CA的Request请求,再用ca.key去自签,我给大家介绍一条一步到位的产生ca ROOT证书的命令,为了安全,我们在最后加上“-configC:\openssl\bin\openssl.cnf”,以使openssl工具可以找到相应的config文件(有些系统在指定了OPENSSL_CONF环境变量后一般就不需要在命令行里去手工指定这个-config变量了)。
由于我们产生的证书为:X509格式,因此需要按照X509格式填入相关的值。
AU-国家家的缩写,如:CHINA=CN,美国=USA,英国=UK,日本=JP
State or Province Name-省/洲的缩写或者是全称,如:上海=SH
Locality Name-城市的全称或者是缩写,如:上海=SH
Organization Name-公司名,如:Cognizant
Common Name-要安装这台证书的主机名,证书是和主机名绑定的,如果证书里的主机名和你实际的主机名不符,这张证书就是非法的证书。
我们不能够填IP,一定一定要填主机名即域名www.xxx.com这样的东西,比如说我填的是shnlap93,但我的主机怎么知道shnlap93是指:10.225.106.35或者说是指localhost这台机器呢?
打开C:\Windows\System32\drivers\etc\hosts这个文件,如下:
localhost shnlap93 10.225.106.35 shnlap93 |
看到了吧?所以当我们使用pint shnlap93时,它是不是就可以知道shnlap93=10.225.106.35啦?
EmailAddress-邮件地址,爱填不填,可以跳过,反正我们是“自签”。
Look,我们的CA证书生成了,可以双击这张证书,查看信息后关闭它。
目前这张ROOT 证书,只是个自签的产品,因为是自签,一般其它客户端的IE里因此是不会带有这张根证书的。
要其实客户端也能信任这张根证书,我们必须怎么办?
将它安装到我们的IE的信任域里。
ü 将ROOT CA导入客户端的根级信任域,有多少台客户端,每个客户端都要导一边这个证书!
所以说如果我们拥有世界级的根证书该多好啊,电脑上默认就带有我们的证书,因此知道这帮世界级的根证书机构为什么能挣钱了吧?50-500美金签张证书,几秒钟的事,CALL!!!
点[导入]按钮

下一步,下一步,此时会有一个弹出框,选“yes(是)”完成导入。
再来打开我们的ca.crt文件
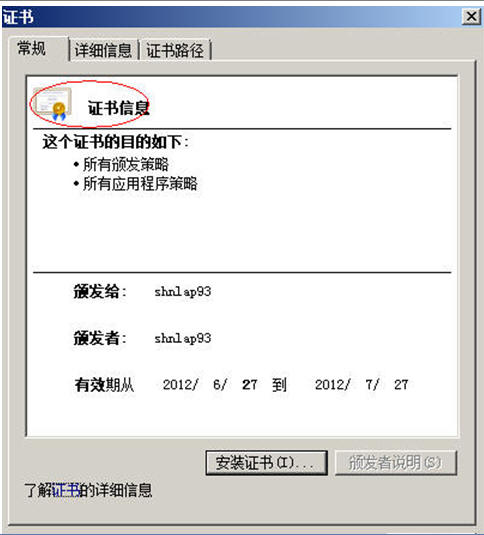
发现了没有,这张证书是有效的证书了,所以在“证书信息”前原有的一个红叉叉,消失了。
ü 生成Web服务器端证书密钥
我们的root证书有了,现在可以生成Web服务器端的证书了,并且用root ca去签名

先生成密钥,密码6个a

去除密码(提示:enter pass phrase for server.key时输入刚才生成密钥时的密码即6个a。
ü 生成Web服务器端证书的签名请求

生成服务器端证书请求时需要输入server端key的口令,我们为了方便,也用6个a。
ü 用Root CA去对Web服务器的证书请求即csr(certificate request)进行签名认证

输入y并回车
此时它会提示:
1 out of 1certificate requests certified, commit? [y/n],再 输入y并回车

Web服务器的server.crt证书生成完毕。
注:
如果在操作时有任何错,必须连同生成的.key,.csr, .crt文件全部删除重头来一遍
我们来看看,这个server.crt文件,双击它。
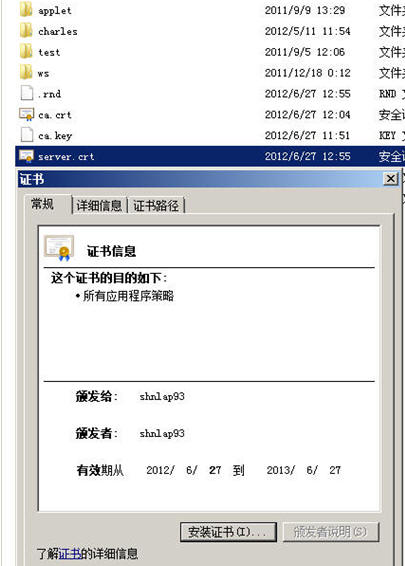
首先,我们看到该证书的“证书信息”前没有红色的大叉,然后是证书信息正是我们刚才输入的内容,为什么没有大叉?
因为我们的RootCA根证书装在我们IE的根级信任域里,又因为我们的客户端信任我们的RootCA,因此当我们的客户端打开由RootCA签出来的server.crt时,这根“信任链”被建立了起来,所以客户端自动单向信任我们的server.crt,对不对?
下面我们来做一个实验,把我们的Root CA从我们的根级信任域中删除。
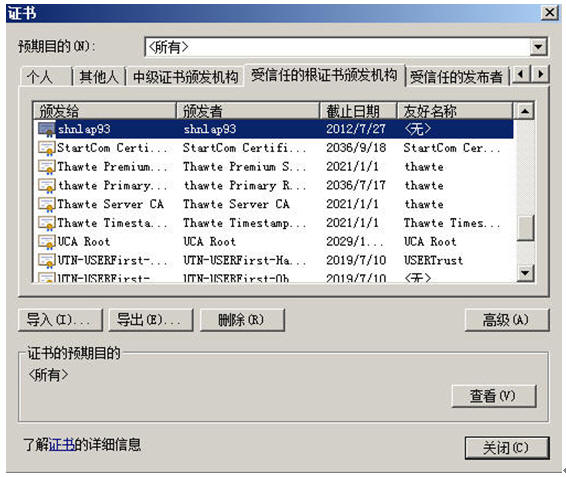
选中这个shnlap93的根级证书,点[删除],会弹出两次确认框,选“yes”确认删除掉它。
关闭IE,然后我们再次双击我们的server.crt文件,来查看证书内容。
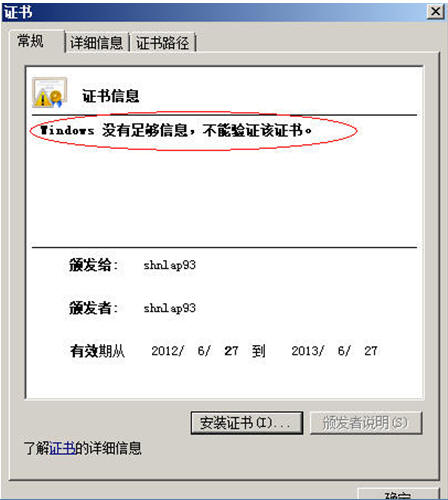
我们看到了什么?“不能验证该证书。
重新导入我们的Root CA至IE的根级信任域(见将ROOT CA导入客户端的根级信任域)。
再次打开server.crt查看证书内容。

一切回复正常了。
2.6 为Apache HttpServer布署https协议
ü 用文本编辑器打开httpd.conf文件,找到如下这一行
#Include conf/extra/httpd-ssl.conf |
这行默认是被注释掉的,因此请把它放开,修改成如下
Include conf/extra/httpd-ssl.conf |
ü 打开D:\tools\httpd\conf\extra\里的httpd-ssl.conf文件
在开头处添加如下这一行语句
# # This is the Apache server configuration file providing SSL support. # It contains the configuration directives to instruct the server how to # serve pages over an https connection. For detailing information about these # directives see <URL:http://httpd.apache.org/docs/2.2/mod/mod_ssl.html> # # Do NOT simply read the instructions in here without understanding # what they do. They're here only as hints or reminders. If you are unsure # consult the online docs. You have been warned. # LoadModule ssl_module modules/mod_ssl.so |
然后找到下面这一行
SSLCertificateFile "D:/tools/httpd/ |
把它改成:
SSLCertificateFile "D:/tools/httpd/cert/server.crt" |
再找到下面这一行
SSLCertificateKeyFile "D:/tools/httpd/ |
把它改成
SSLCertificateKeyFile "D:/tools/httpd/cert/server.key" |
然后把我们在我们的Apache HttpServer的安装目录下手工建一个目录叫cert的目录,并把我们在前面生成的server.crt与server.key文件拷入d:\tools\httpd\cert目录内。
在httpd.conf文件中搜索“ServerName”
搜到下面这样的一句
ServerName 10.225.101.35:80 |
把它改成你的主机名
ServerName shnlap93:80 |
此处的shnlap93是你的主机名
再继续在httpd.conf文件中搜索“VirtualHost *”
搜到下面这一句
<VirtualHost *> |
把它改成
<VirtualHost shnlap93:80> |
在D:\tools\httpd\conf\extra\httpd-ssl.conf文件中查找
搜“VirtualHost _default_:443”
然后把位于< VirtualHost _default_:443>段内的头三行改成如下格式
确保你的http的发布目录在d:/www
确保你的HTTPS的主机名为shnlap93:443(这边的名字和生成证书里的common name必须完全一模一样连大小写都必须一样)
DocumentRoot "D:/www" ServerName shnlap93:443 ServerAdmin admin@localhost |
然后在下一个“</VirtualHost> ”结束前,填入下面这几行语句
DirectoryIndex index.html index.htm index.jsp index.action JkMount /*WEB-INF ajp13 JkMount /*j_spring_security_check ajp13 JkMount /*.action ajp13 JkMount /servlet/* ajp13 JkMount /*.jsp ajp13 JkMount /*.do ajp13 JkMount /*.action ajp13 JkMount /*fckeditor/editor/filemanager/connectors/*.* ajp13 JkMount /fckeditor/editor/filemanager/connectors/* ajp13 |
在重启我们的Apache服务前先Test Configuration一下,如果一切无误,可以重启了。
然后我们来实验一下我们的Web Server的https的效果

看到没有,这个红圈圈起来的地方,目前是正常的,显示金黄色的一把钥匙。
如果你的Root CA没有装入IE的根级信任域,此时你敲入https://shnlap93/cbbs时,你会被提示说“该证书不被任何”,然后让你点一下“确认”按钮,点完信任后能进入我们的Web应用,但是,原先应该显示“金黄色钥匙”的地方会显示一个红色的圈圈,并且当你查看证书信息时,这个地方也会显示“证书不受信任”,并且显示一个红色的大叉。
2.7 为Tomcat也布署https协议
我们的Apache HttpServer已经走https协议了,不是已经enough了吗?NO,远远不够,如果你没有用到任何App Server即tomcat/weblogic/was那么我们说我们的应用已经走https协议了,但是因为我们的架构是Web Server + App Server,因此,我们的App Server也必须走https协议。
如果只是Web Server走https协议,而App Server没有走https协议,这就叫“假https架构”,是一种极其偷赖和不负责任的做法。
概念同产生Apache的HttpServer的证书一样,只是这边的信任域有点不一样。
Web的信任域就是你的IE里的内容里的证书里的“根级信任域”,App Server的信任域是打不开也不能访问这块地方的,而且App Server的信任域格式也不是crt文件,而是.jks(javakey store的简称)。
下面来做一个tomcat的https布署。
原有ca.crt和ca.key继续有用,因为ROOT CA都是一个,而且必须一定始终是唯一的一个,对吧?
我们直接从server.jks来做起。
说JKS,这东西好玩的很,jks文件其实就是把key文件与crt文件合在一起,以java key store的格式来存储而己。
2.8 生成Tomcat的SSL证书
为Tomcat的server所在的服务器生成一个server.jks文件
很多网上的资料是拿原先的server.crt文件转成keystore文件,其实是不对的,需要单独生成一张server.jks文件。
怎么生成证书?回顾一下上文:
1) 生成KEY
2) 生成证书请求
3) 用CA签名
下面开始使用%JAVA_HOME%\bin目录下的keytool工具来产生证书
ü 生成JKS密钥对,密码使用6个a,alias代表“别名”,CN代表Common Name,必须与主机名完全一致,错了不要怪我自己负责。
keytool -genkey -alias shnlap93X509 -keyalg RSA -keysize 1024 -dname "CN=shnlap93, OU=insurance-dart, O=Cognizant, L=SH, S=SH, C=CN" -keypass aaaaaa -keystore shnlap93.jks -storepass aaaaaa |
ü 生成JSK的CSR
keytool -certreq -alias shnlap93X509 -sigalg "MD5withRSA" -file shnlap93.csr -keypass aaaaaa -keystore shnlap93.jks -storepass aaaaaa |
此处注意:
Alias名必须和上面一致
密码和上面一致
ü 使用openssl结合ca.crt与ca.key为jsk的csr来签名认证并产生jks格式的crt
openssl x509 -req -in shnlap93.csr -out shnlap93.crt -CA ca.crt -CAkey ca.key -days 3650 -CAcreateserial -sha1 -trustout -CA ca.crt -CAkey ca.key -days 3650 -CAserial ca.srl -sha1 -trustout |
提示yes和no时选yes
于是,我们有了一张符合jks格式的crt证书叫shnlap93.crt文件,来查看它。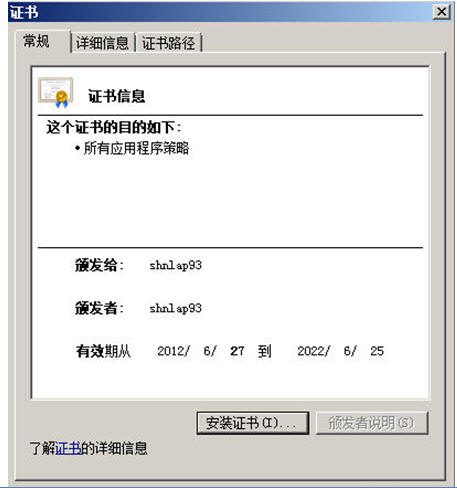
证书上没有红色的大叉,因为我们的Root CA装在我们的IE的根级信任域中,OK,下面来了,生成这个JKS,就是把crt和key合在一起,来了!
ü 生成符合x509格式的jks文件
1) 将Root CA导入jks信任域
keytool -import -alias rootca -trustcacerts -file ca.crt -keystore shnlap93.jks -storepass aaaaaa |
前面我说了,jks信任域是读不到IE的根级信任域的,因此要手动把ca.crt文件导入jks的信任域
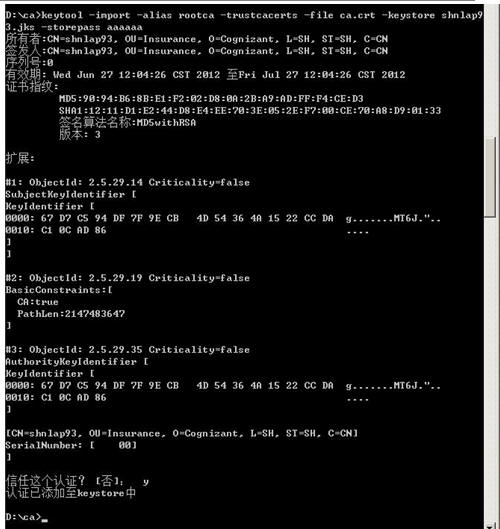
1) 现在我们的shnlap93.jks文件中有两个realm(域),一个是:
本身的csr(产生的签书请求认证的域,还没被认证,因为认证的内容变成了shnlap93.crt文件了是不是?)
刚才步骤中导入的Root CA认证域
那么客户端信任Root CA没有问题,但由于server端本身的信任域还只是处于“请求被签名”的状态,那么客户端如何去信任这个jks文件呢?
答案就是:补链,补这根信任链!
keytool -import -alias shnlap93X509 -file shnlap93.crt -keystore shnlap93.jks -storepass aaaaaa |

我们不是生成过shnlap93.crt吗?把它导入jks不就是能够把原有的“正在处于请求被签名认证”这个状态改成“已经被Root CA签名认证” 了吗?对吧?
所以,我们用于布署tomcat的ssl证书的jks格式的文件shnlap93.jks已经完整了。
2.9 布署Tomcat上的Https协议
Apache HttpServer走的是443端口,Tomcat走的就是8443端口。
打开tomcat的conf目录下的server.xml,我们来找下面这一段:
<!-- <Connector executor="tomcatThreadPool" port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" /> --> |
默认情况下,它是被由“<!-- -->”这样的标签给注释起来的,我们把它放开
<!-- enable tomcat ssl --> <Connector executor="tomcatThreadPool"port="8443" protocol="HTTP/1.1" connectionTimeout="20000" secure="true" SSLEnabled="true" clientAuth="false" sslProtocol="TLS" keystoreFile="d:/tomcat/conf/shnlap93.jks" keystorePass="aaaaaa" /> |
clientAuth=”false”
如果该值为”true”就代表要启用双向认证
keystoreFile就是我们生成的keystore文件所在的完全路径
keystorePass就是我们生成keystore时的password
重启tomcat,输入https://shnlap93:8080/cbbs, 可以看到登录网页,且右上方的SSL连接信息为“金黄色的钥匙”而不是红色大叉,那么一切就成功了。
重启Apache,然后在ie地址栏输入: https://shnlap93/cbbs,用sally/abcdefg,一切成功。
注意:
当启用了https协议后,你在ie地址栏就不能再用localhost了,为什么?因为我们的证书中的CN(Common Name)填入的是主机名,如果你还用:https://localhost,那么你也能正常进入网址,只是多了几步https不被信任的警告框,并且你右上角的ssl连接信息为红色的大叉,对于这样的https连接,如果换成是购物网站,你敢信任吗?
2.10 apache https + tomcat https
假https
前面说过,如果你是在Apache上启用了https而没有在tomcat上启用https协议,那么我们在tomcat中布署一个servlet,含一条打印语句: System.out.println(“”+request.getScheme()),那么它将打印出来http。
真https
如果我们在Apache上启用了https通时在tomcat上也启用了https,那么我们如果有这样的一条语句:System.out.println(“”+request.getScheme()),它打印出来的将是:https。
在前两天的学习中我们知道、了解并掌握了Web Server结合App Server实现单向Https的这样的一个架构。这个架构是一个非常基础的J2ee工程上线布署时的一种架构。在前两天的教程中,还讲述了Http服务器、App Server的最基本安全配置(包括单向https的实现), 它只是避免了用户可以通过浏览器侵入我们的Web访问器或者能够通过Web浏览器来查询我们的Web目录结构及其目录内的文件与相关内容,这种入侵我们把它称为:
Directory traversal,当然我们只是实现了最基本的防范Directory traversal的手段,在日后的Security课程中将会详细地去擅述完整的Web Security的相关理论。
从今天起我们将继续在原有的这种Apache+Tomat的架构上,去论述如何在性能及Performance上优化这个架构,因此这两天的课程在有些人看来,可能会有些“枯燥”,所以我在此给大家打个招呼:
这两天的课程论述的是如何在不改动代码与SQL语句的前提下,如何去改善和提高web server与app server的性能,千万不要小觑这一内容,它可以让你在不改动代码的情况下得到10-20倍以上的性能提高,网上有其它的大牛们写过一篇文章叫“Tomcat如何支持到1000个用户”,经本人经过几个重大工程的实践,Opensource的Tomcat如果调优的好不只可以支持者1000个用户,尤其当你的布署环境是64位操作系统的情况下,可能能够支持更大更高的并发性能,最后本节内容将会以Tomcat集群来做收场,在将来的课程中还会进一步详细讲述Weblogic的集群配置与IBM WASND的集群配置。
二、从性能测试谈起
2.1 性能测试简介
即压力测试,就是根据一定数量的VU(Virtual Users)我称为并发用户操作核心交易后,系统所能达到的最大瓶劲,以便于发现系统的极限、有没有Outof memory这样的问题存在以及相关的系统设置、配置是否搭挡的合理的一种测试。
一般商业的比较好的用LoaderRunner,如果没钱的就用Opensource的Jmeter来模拟这个VU的操作。
压力测试,存在几个误区,需要小心。
1) 无限大的拼命增加VU的数量
系统再完美,硬件配置再高,也经不住没有经过合理运算的VU的压力呀。
2) 偏执的用一定的数据量的VU,跑7*24小时
不是说这个没必要,很有必要,小日本的电视为什么寿命敢说比中国人生产的电视机寿命长?因为它用一个机械臂就对着电视机的按钮不断的点点点。
我们说的压力测试要测试多长时间,关键是要看经过科学计算的VU的数量以及核心交易数有多少,不是说我拿250个VU跑24*7如果没有问题我这个系统就没有问题了,这样的说法是不对的,错误的。随便举个例子就能把你推倒。
假设我有250个VU,同时跑上万笔交易,每个VU都有上万笔交易,250个VU一次跑下来可能就要数个小时,你又怎么能断定250个VU对于这样的系统我跑24*7小时就能真的达到上万笔交易在250个VU的并发操作下能够真的跑完7天的全部交易?可能需要一周半或者两周呢?对吧?
我还看到过有人拿500个VU对着一条交易反复跑24*7小时。。。这样的测试有意义吗?你系统就仅仅只有一条交易?你怎么能够判断这条交易涉及到的数据量最大?更不用说交易是彼此间有依赖的,可能a+b+c+d的交易的一个混合组织就能够超出你单笔交易所涉及到的数据量了呢!
2.2 合理的制定系统最大用户、并发用户
提供下面这个公式,以供大家在平时或者日常需要进行的性能测试中作为一个参考。
(1) 计算平均的并发用户数:C = nL/T
公式(1)中,C是平均的并发用户数;n是login session的数量;L是login session的平均长度;T指考察的时间段长度。
(2) 并发用户数峰值:C’ ≈ C+3根号C
公式(2)则给出了并发用户数峰值的计算方式中,其中,C’指并发用户数的峰值,C就是公式(1)中得到的平均的并发用户数。该公式的得出是假设用户的loginsession产生符合泊松分布而估算得到的。
实例:
假设有一个OA系统,该系统有3000个用户,平均每天大约有400个用户要访问该系统,对一个典型用户来说,一天之内用户从登录到退出该系统的平均时间为4小时,在一天的时间内,用户只在8小时内使用该系统。
则根据公式(1)和公式(2),可以得到:
C = 400*4/8 = 200
C’≈200+3*根号200 = 242
F=VU * R / T
其中F为吞吐量,VU表示虚拟用户个数,R表示每个虚拟用户发出的请求数,T表示性能测试所用的时间
R = T / TS。
2.3 影响和评估性能的几个关键指标
从上面的公式一节中我们还得到了一个名词“吐吞量”。和吞吐量相关的有下面这些概念,记录下来以供参考。

吞吐量
指在一次性能测试过程中网络上传输的数据量的总和。
对于交互式应用来说,吞吐量指标反映的是服务器承受的压力,在容量规划的测试中,吞吐量是一个重点关注的指标,因为它能够说明系统级别的负载能力,另外,在性能调优过程中,吞吐量指标也有重要的价值。
吞吐率
单位时间内网络上传输的数据量,也可以指单位时间内处理客户请求数量。它是衡量网络性能的重要指标,通常情况下,吞吐率用“字节数/秒”来衡量,当然,你可以用“请求数/秒”和“页面数/秒”来衡量。其实,不管是一个请求还是一个页面,它的本质都是在网络上传输的数据,那么来表示数据的单位就是字节数。
事务
就是用户某一步或几步操作的集合。不过,我们要保证它有一个完整意义。比如用户对某一个页面的一次请求,用户对某系统的一次登录,淘宝用户对商品的一次确认支付过程。这些我们都可以看作一个事务。那么如何衡量服务器对事务的处理能力。又引出一个概念----TPS
TPS (Transaction Per second)
每秒钟系统能够处理事务或交易的数量,它是衡量系统处理能力的重要指标。
点击率(Hit Per Second)
点击率可以看做是TPS的一种特定情况。点击率更能体现用户端对服务器的压力。TPS更能体现服务器对客户请求的处理能力。
每秒钟用户向web服务器提交的HTTP请求数。这个指标是web 应用特有的一个指标;web应用是“请求-响应”模式,用户发一个申请,服务器就要处理一次,所以点击是web应用能够处理的交易的最小单位。如果把每次点击定义为一个交易,点击率和TPS就是一个概念。容易看出,点击率越大。对服务器的压力也越大,点击率只是一个性能参考指标,重要的是分析点击时产生的影响。
需要注意的是,这里的点击不是指鼠标的一次“单击”操作,因为一次“单击”操作中,客户端可能向服务器发现多个HTTP请求。
吞吐量指标的作用:
ü 用户协助设计性能测试场景,以及衡量性能测试场景是否达到了预期的设计目标:在设计性能测试场景时,吞吐量可被用户协助设计性能测试场景,根据估算的吞吐量数据,可以对应到测试场景的事务发生频率,事务发生次数等;另外,在测试完成后,根据实际的吞吐量可以衡量测试是否达到了预期的目标。
ü 用于协助分析性能瓶颈:吞吐量的限制是性能瓶颈的一种重要表现形式,因此,有针对性地对吞吐量设计测试,可以协助尽快定位到性能冰晶所在位置。
平均相应时间
也称为系统响应时间,它一般指在指定数量的VU情况下,每笔交易从mouse 的click到IE的数据刷新与展示之间的间隔,比如说:250个VU下每笔交易的响应时间不超过2秒。
当然,响应时间也不能一概而论,对于实时交易如果银行柜台操作、超市收银员(邪恶的笑。。。)的操作、证交所交易员的操作来说这些操作的响应时间当然是越快越好,而对于一些企业级的如:
与银行T+1交易间的数据跑批、延时交易、T+1报表等,你要求它在2秒内响应,它也做不到啊。就好比你有个1MB的带宽,你传的东西是超过4MB,你要它在2秒内跑完理论速度也做不到啊,对吧,所以有些报表或者数据,光前面传输时间就不止两秒了。。。一口咬死说我所有的交易平均相应时间要2秒,真的是不科学的!
2.4 合理的性能测试
VU数量的增加
一个合理的性能测试除了需要合理的计算VU的数量、合理的设置系统平均响应时间外还需要合理的在测试时去规划发起VU的时间,比如说,我看到有人喜欢这样做压力测试。
第一秒时间,500个并发用户全部发起了。。。结果导致系统没多久就崩了,然后说系统没有满足设计要求。
为什么说上述这样的做法是不对的?我们说不是完全不对,只能说这样的测试已经超过了500个VU的并发的设计指标了。
合理的并发应该是如下这样的:
有25-50个VU开始起交易了,然后过一段时间又有25-50个用户,过一段时间又增加一些VU,当所有的设计VU都发起交易了,此时,再让压力测试跑一段时间比如说:24*7是比较合理的。所以VU数量不是一上手就500个在一秒内发起的,VU数量的增加应该如下面这张趋势图:

这是一个阶梯状的梯型图,可以看到VU的发起是逐渐逐渐增多的,以下两种情况如果发生需要检查你的系统是否在原有设置上存在问题:
ü VU数量上升阶段时崩溃
有时仅仅在VU数量上升阶段,系统就会了现各种各样的错误,甚至有崩溃者,这时就有重新考虑你的系统是否有设置不合理的地方了。
ü VU全部发起后没多久系统崩溃
VU在达到最高值时即所有的VU都已经发起了,此时它是以一条直的水平线随着系统运行而向前延伸着的,但过不了多久,比如说:运行24*7小时,运行了没一、两天,系统崩溃了,也需要做检查。
所以,理想的性能测试应该是VU数量上升到最终VU从发起开始到最后所有VU把交易做完后,VU数量落回零为止。吐吞量的变化
从2.3节我们可以知道,吞吐量是随着压力/性能测试的时间而逐渐增大的,因此你的吞吐量指示应该如下图所示:

肯定是这样,你的吞吐量因该是积累的,如果你的吞吐量在上升了一段时间后突然下落,而此时你的性能测试还在跑着,如下图所示:

那么,此时代表什么事情发生了?你可以查一下你的loaderrunner或者jmeter里对于这段吞吐量回落期间的交易的response的状态进行查看,你将会发现大量的error已经产生,因为产生了error,所以你的交易其实已经出错了,因此每次运行的数据量越来越小,这也就意味着你的压力测试没有过关,系统被你压崩了!
平均响应时间
平均响应时间如VU的数量增加趋势图一样,一定是一开始响应时间最短,然后一点点增高,当增高到一定的程度后,即所有的VU都发起交易时,你的响应时间应该维持在一个水平值,然后随着VU将交易都一笔笔做完后,这个响应时间就会落下来,这段时间内的平均值就是你的系统平均响应时间。看看它,有没有符合设计标准?
内存监控
我们就来说AppServer,我们这边用的是Tomcat即SUN的JVM的内存变化,我们就用两张图例来讲解吧:
理想状态情况下的JVM内存使用趋势:

这是一个波浪型的(或者也可以说是锯齿型的)趋势图,随着VU数量的一点点增加,我们的内存使用数会不断的增加,但是JVM的垃圾回收是自动回收机制的,因此如果你的JVM如上述样的趋势,内存上涨一段时间,随即会一点点下落,然后再上涨一点,涨到快到头了又开始下落,直到最后你的VU数量全部下降下来时,你的JVM的内存使用也会一点点的下降。
非理想状态情况下的JVM内存使用趋势:

嘿嘿嘿,看到了吗?你的JVM随着VU 数量的上升,而直线上升,然后到了一定的点后,即到了java �CXmx后的那个值后,突然直线回落,而此时你的交易还在进行,压力测试也还在进行,可是内存突然回落了。。。因为你的JVM已经crash了,即OUT OF MEMORY鸟。
CPU Load
我们来看一份测试人员提交上来CPU得用率的报告:
Web Server |
App Server |
DB Server |
60% |
98% =_=!(oh my god) |
6% �� |
同时平均响应时间好慢啊。
拿过来看了一下代码与设计。。。Struts+Spring+JDBC的一个框架,没啥花头的,再仔细一看Service层。
大量的复杂业务逻辑甚至报表的产生全部用的是javaobject如:List, Hashmap等操作,甚至还有在Service层进行排序、复杂查询等操作。
一看DB层的CPU利用率才6%,将一部分最复杂的业务拿出去做成Store Procedure(存储过程后),再重新运行压力测试。
Web Server |
App Server |
DB Server |
60% |
57% =_=!(oh my god) |
26% �� |
同时平均响应时间比原来快了15-16倍。
为什么??
看看第一份报告,我们当时还查看了数据库服务器的配置,和APPServer的配置是一个级别的,而利用率才6%。。。
数据库,至所以是大型的商用的关系型数据库,你只拿它做一个存储介质,你这不是浪费吗?人家里面设置的这个StoreProcedure的处理能力,索引效率,数据分块等功能都没有去利用,而用你的代码去实现那么多复杂业务比如说多表关联、嵌套等操作,用必要吗?那要数据库干什么用呢?
是啊,我承认,原有这样的代码,跨平台能力强一点,可付出的代价是什么呢?
用户在乎你所谓的跨平台的理论还是在乎的是你系统的效率?一个系统定好了用DB2或者是SQL SERVER,你觉得过一年它会换成ORACLE或者MYSQL吗?如果1年一换,那你做的系统也只能让用户勉强使用一年,我劝你还是不要去做了。在中国,有人统计过5年左右会有一次系统的更换,而一些银行、保险、金融行业的系统一旦采用了哪个数据库,除非这个系统彻底出了问题,负责是不会轻意换数据库的,因此不要拿所谓的纯JAVA代码或者说我用的是Hibernate,ejb实现可以跨数据库这套来说事,效率低下的系统可以否定你所做的一切,一切!
三、Apache服务器的优化
上面两节,讲了大量的理论与实际工作中碰到的相关案例,现在就来讲一下在我们第一天和第二天中的ApacheHttp Server + Tomcat这样的架构,怎么来做优化吧。
3.1 Linux/UnixLinux系统下Apache 并发数的优化
Apache Http Server在刚安装完后是没有并发数的控制的,它采用一个默认的值,那么我们的Web Server硬件很好,允许我们撑到1000个并发即VU,而因为我们没有去配置导致我们的WebServer连300个并发都撑不到,你们认为,这是谁的责任?
Apache Http服务器采用prefork或者是worker两种并发控制模式。
preforkMPM
使用多个子进程,每个子进程只有一个线程。每个进程在某个确定的时间只能维持一个连接。在大多数平台上,PreforkMPM在效率上要比Worker MPM要高,但是内存使用大得多。prefork的无线程设计在某些情况下将比worker更有优势:它可以使用那些没有处理好线程安全的第三方模块,并且对于那些线程调试困难的平台而言,它也更容易调试一些。
workerMPM 使用多个子进程,每个子进程有多个线程。每个线程在某个确定的时间只能维持一个连接。通常来说,在一个高流量的HTTP服务器上,Worker MPM是个比较好的选择,因为Worker MPM的内存使用比PreforkMPM要低得多。但worker MPM也由不完善的地方,如果一个线程崩溃,整个进程就会连同其所有线程一起"死掉".由于线程共享内存空间,所以一个程序在运行时必须被系统识别为"每个线程都是安全的"。
一般来说我们的ApacheHttp Server都是装在Unix/Linux下的,而且是采用源码编译的方式来安装的,我们能够指定在编译时Apache就采用哪种模式,为了明确我们目前的Apache采用的是哪种模式在工作,我们还可以使用httpd �Cl命令即在Apache的bin目录下执行httpd �Cl,来确认我们使用的是哪种模式。
这边,我们使用Apache配置语言中的” IfModule”来自动选择模式的配置。
我们的ApacheHttp Server在配完后一般是没有这样的配置的,是需要你手动的添加如下这样的一块内容的,我们来看,在httpd.conf文件中定位到最后一行LoadModule,敲入回车,加入如下内容:
<IfModule prefork.c> ServerLimit 20000 StartServers 5 MinSpareServers 5 MaxSpareServers 10 MaxClients 1000 MaxRequestsPerChild 0 </IfModule> |
上述参数解释:
ü ServerLimit 20000
默认的MaxClient最大是256个线程,如果想设置更大的值,就的加上ServerLimit这个参数。20000是ServerLimit这个参数的最大值。如果需要更大,则必须编译apache,此前都是不需要重新编译Apache。
生效前提:必须放在其他指令的前面
ü StartServers 5
指定服务器启动时建立的子进程数量,prefork默认为5。
ü MinSpareServers 5
指定空闲子进程的最小数量,默认为5。如果当前空闲子进程数少于MinSpareServers ,那么Apache将以最大每秒一个的速度产生新的子进程。此参数不要设的太大。
ü MaxSpareServers 10
设置空闲子进程的最大数量,默认为10。如果当前有超过MaxSpareServers数量的空闲子进程,那么父进程将杀死多余的子进程。此参数不要设的太大。如果你将该指令的值设置为比MinSpareServers小,Apache将会自动将其修改成"MinSpareServers+1"。
ü MaxClients 256
限定同一时间客户端最大接入请求的数量(单个进程并发线程数),默认为256。任何超过MaxClients限制的请求都将进入等候队列,一旦一个链接被释放,队列中的请求将得到服务。要增大这个值,你必须同时增大ServerLimit。
ü MaxRequestsPerChild10000
每个子进程在其生存期内允许伺服的最大请求数量,默认为10000.到达MaxRequestsPerChild的限制后,子进程将会结束。如果MaxRequestsPerChild为"0",子进程将永远不会结束。
将MaxRequestsPerChild设置成非零值有两个好处:
1.可以防止(偶然的)内存泄漏无限进行,从而耗尽内存。
2.给进程一个有限寿命,从而有助于当服务器负载减轻的时候减少活动进程的数量。
Prefork.c的工作方式:
一个单独的控制进程(父进程)负责产生子进程,这些子进程用于监听请求并作出应答。Apache总是试图保持一些备用的(spare)或者是空闲的子进程用于迎接即将到来的请求。这样客户端就不需要在得到服务前等候子进程的产生。在Unix系统中,父进程通常以root身份运行以便邦定80端口,而Apache产生的子进程通常以一个低特权的用户运行。User和Group指令用于设置子进程的低特权用户。运行子进程的用户必须要对它所服务的内容有读取的权限,但是对服务内容之外的其他资源必须拥有尽可能少的权限。
在上述的</IfModule>后再加入一个”<IfModule>”如下红色加粗(大又粗)内容:
<IfModule prefork.c> ServerLimit 20000 StartServers 5 MinSpareServers 5 MaxSpareServers 10 MaxClients 1000 MaxRequestsPerChild 0 </IfModule> <IfModule worker.c> ServerLimit 50 ThreadLimit 200 StartServers 5 MaxClients 5000 MinSpareThreads 25 MaxSpareThreads 500 ThreadsPerChild 100 MaxRequestsPerChild 0 </IfModule> |
上述参数解释:
ü ServerLimit16
服务器允许配置的进程数上限。这个指令和ThreadLimit结合使用设置了MaxClients最大允许配置的数值。任何在重启期间对这个指令的改变都将被忽略,但对MaxClients的修改却会生效。
ü ThreadLimit64
每个子进程可配置的线程数上限。这个指令设置了每个子进程可配置的线程数ThreadsPerChild上限。任何在重启期间对这个指令的改变都将被忽略,但对ThreadsPerChild的修改却会生效。默认值是"64".
ü StartServers3
服务器启动时建立的子进程数,默认值是"3"。
ü MinSpareThreads75
最小空闲线程数,默认值是"75"。这个MPM将基于整个服务器监视空闲线程数。如果服务器中总的空闲线程数太少,子进程将产生新的空闲线程。
ü MaxSpareThreads250
设置最大空闲线程数。默认值是"250"。这个MPM将基于整个服务器监视空闲线程数。如果服务器中总的空闲线程数太多,子进程将杀死多余的空闲线程。MaxSpareThreads的取值范围是有限制的。Apache将按照如下限制自动修正你设置的值:worker要求其大于等于MinSpareThreads加上ThreadsPerChild的和
ü MaxClients400
允许同时伺服的最大接入请求数量(最大线程数量)。任何超过MaxClients限制的请求都将进入等候队列。默认值是"400",16(ServerLimit)乘以25(ThreadsPerChild)的结果。因此要增加MaxClients的时候,你必须同时增加ServerLimit的值。
ü ThreadsPerChild25
每个子进程建立的常驻的执行线程数。默认值是25。子进程在启动时建立这些线程后就不再建立新的线程了。
ü MaxRequestsPerChild 0
设置每个子进程在其生存期内允许伺服的最大请求数量。到达MaxRequestsPerChild的限制后,子进程将会结束。如果MaxRequestsPerChild为"0",子进程将永远不会结束。
将MaxRequestsPerChild设置成非零值有两个好处:
1.可以防止(偶然的)内存泄漏无限进行,从而耗尽内存。
2.给进程一个有限寿命,从而有助于当服务器负载减轻的时候减少活动进程的数量。
注意
对于KeepAlive链接,只有第一个请求会被计数。事实上,它改变了每个子进程限制最大链接数量的行为。
Worker.c的工作方式:
每个进程可以拥有的线程数量是固定的。服务器会根据负载情况增加或减少进程数量。一个单独的控制进程(父进程)负责子进程的建立。每个子进程可以建立ThreadsPerChild数量的服务线程和一个监听线程,该监听线程监听接入请求并将其传递给服务线程处理和应答。Apache总是试图维持一个备用(spare)或是空闲的服务线程池。这样,客户端无须等待新线程或新进程的建立即可得到处理。在Unix中,为了能够绑定80端口,父进程一般都是以root身份启动,随后,Apache以较低权限的用户建立子进程和线程。User和Group指令用于设置Apache子进程的权限。虽然子进程必须对其提供的内容拥有读权限,但应该尽可能给予它较少的特权。另外,除非使用了suexec,否则,这些指令设置的权限将被CGI脚本所继承。
公式:
ThreadLimit>= ThreadsPerChild
MaxClients <= ServerLimit * ThreadsPerChild 必须是ThreadsPerChild的倍数
MaxSpareThreads>= MinSpareThreads+ThreadsPerChild
硬限制:
ServerLimi和ThreadLimit这两个指令决定了活动子进程数量和每个子进程中线程数量的硬限制。要想改变这个硬限制必须完全停止服务器然后再启动服务器(直接重启是不行的)。
Apache在编译ServerLimit时内部有一个硬性的限制,你不能超越这个限制。
preforkMPM最大为"ServerLimit200000"
其它MPM(包括work MPM)最大为"ServerLimit 20000
Apache在编译ThreadLimit时内部有一个硬性的限制,你不能超越这个限制。
mpm_winnt是"ThreadLimit 15000"
其它MPM(包括work prefork)为"ThreadLimit 20000
注意
使用ServerLimit和ThreadLimit时要特别当心。如果将ServerLimit和ThreadLimit设置成一个高出实际需要许多的值,将会有过多的共享内存被分配。当设置成超过系统的处理能力,Apache可能无法启动,或者系统将变得不稳定。
3.2 WindowsWindows系统下Apache 并发数的优化
以上是Linux/Unix下的Apache的并发数优化配置,如果我们打入了httpd �Cl如下显示:
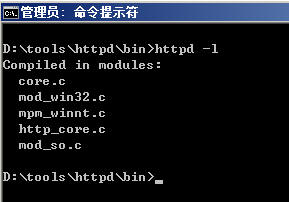
怎么办?
ü 步骤一
先修改/path/apache/conf/httpd.conf文件。
httpd.conf
将“#Includeconf/extra/httpd-mpm.conf”前面的 “#” 去掉,保存。
ü 步骤二
再修改/apache安装目录/conf/extra/httpd-mpm.conf文件。
在mpm_winnt模式下,Apache不使用prefork也不使用work工作模式,切记!
因此,我们只要找到原文件中:
<IfModule mpm_winnt_module> ThreadsPerChild 150 MaxRequestsPerChild 0 </IfModule> |
修改后
<IfModule mpm_winnt_module> ThreadsPerChild 500 MaxRequestsPerChild 5000 </IfModule> |
上述参数解释:
ü ThreadsPerChild
是指一个进程最多拥有的线程数(Windows版本,貌似不可以开启多个进程),一般100-500就可以,根据服务器的具体性能来决定。
ü MaxRequestsPerChild
是指一个线程最多可以接受的连接数,默认是0,就是不限制的意思,
0极有可能会导致内存泄露。所以,可以根据实际情况,配置一个比较大的值。Apache会在几个线程之间进行轮询,找到负载最轻的一个线程来接受新的连接。
注意:
修改后,一定不要apacherestart,而是先 apache stop 然后再 apache start才可以。
3.3 启用服务端图片压缩
对于静态的html 文件,在apache 可加载mod_deflate.so 模块,把内容压缩后输出,可节约大量的传输带宽。
打开httpd.conf文件,找到:
#LoadModule deflate_module modules/mod_deflate.so |
将前面的“#”去掉,变成:
LoadModule deflate_module modules/mod_deflate.so |
然后在最后一行的LoadModule处,加入如下的几行:
<IfModule mod_deflate.c> DeflateCompressionLevel 7 AddOutputFilterByType DEFLATE text/html text/plain text/xml application/x-httpd-php AddOutputFilter DEFLATE css js </IfModule> |
注意:
默认等级是6,而且9级需要更多的CPU时间,用默认的6级就可以了。
要注意的是,在apache 2.2.15中,我用httpd -l看,居然发现mod_deflat已经内置了,所以其实就不用再在httpd.conf中增加loadmodule了,否则会说出错的
3.4 Apache中将MS办公文档自动关联客户端的MS-Office
我们经常会在web页的一个超链接上点一个指向物理文件的文档,我们一般会得到“保存,另存为,打开”,3个选项,当我们打开的如果是一个MS文档,在选“打开”选项时IE会自动启用客户端上装有的word或者是excel等相关MS办公工具去打开,这个怎么做呢?很简单。
打开httpd.conf,找到:
AddType application/x-compress .Z AddType application/x-gzip .gz .tgz |
在其后敲入一个回车,加入:
AddType application/vnd.openxmlformats docx pptx xlsx doc xls ppt txt |
重启Apache服务即可。
3.5 防止DDOS攻击
DDOS攻击即采用自动点击机器人或者连续点击工具不断的刷新某一个网址或者网页上的按钮,造成网站在一时间收到大量的HTTP请求,进而阻塞网站正常的HTTP通道甚至造成网站瘫痪。

为了防止这一形式的攻击,我们一般把在一个按钮或者是一个请求在一秒内连续执行如:100次,可以认为是一种攻击(比如说你打开一个网页,点一下提交按钮,然后按住F5键不松开)。
在Linux下的Apache HttpServer安装后会提供一个mod_evasive20的模块,用于防止这一形式的攻击,它的做法是:
如果认为是一个DDOS攻击,它的防范手段采用如下两种形势:
ü 把这个请求相关联的IP,封锁30分钟
ü 直接把相关的IP踢入黑名单,让其永不翻身
设置:
在你的Apache的httpd.conf文件中的最后一行“LoadModule”加入如下这句:
LoadModule evasive20_module /usr/lib/httpd/modules/mod_evasive20.so |
然后加入下面这几行
<IfModule mod_evasive20.c> DOSHashTableSize 3097 DOSPageCount 15 DOSSiteCount 100 DOSPageInterval 1 DOSSiteInterval 1 DOSBlockingPeriod 36000 DOSEmailNotify 网站超级管理员@xxx.com DOSLogDir "logs/mod_evasive" </IfModule> |
核心参数解释:
ü DOSHashTableSize3097 记录黑名单的尺寸
ü DOSPageCount 每个页面被判断为dos攻击的读取次数
ü DOSSiteCount 每个站点被判断为dos攻击的读取部件(object)的个数
ü DOSPageInterval 读取页面间隔秒
ü DOSSiteInterval 读取站点间隔秒
ü DOSBlockingPeriod 被封时间间隔秒
注意:
上述设置是针对Linux/Unix下的Apache Server,相关的Windows下的Apache见如下设置:
为Windows下的Apache加载mod_evasive模块
1. 下载附件中的压缩包,解压并拷贝mod_dosevasive22.dll到Apache安装目录下的modules目录(当然也可以是其他目录,需要自己修改路径)。
2. 修改Apache的配置文件http.conf。
添加以下内容
LoadModule dosevasive22_module modules/mod_dosevasive22.dll DOSHashTableSize 3097 DOSPageCount 3 DOSSiteCount 50 DOSPageInterval 1 DOSSiteInterval 1 DOSBlockingPeriod 10 |
3.6 Apache中设置URL含中文附件的下载/打开的方法(仅限Linux系统下)
这个话题很有趣,起因是我们在工程中碰到了客户这样的一个需求:
<a href=”xxx.xxx.xx/xx/xxx/轮胎损坏情况2007-05-05.jpg”>损坏部件</a>
看看好像没啥问题,一点这个超链接,因该是在IE中打开一个叫” 轮胎损坏情况2007-05-05.jpg”,嘿嘿,大家自己动手放一个带有中文名的这样的一个图片,看看能否被解析,解析不了。
所以我们就说,真奇怪,我们上传图片都是上传时的图片名经上传组件解析过以后变成一个UUID或者是GUID一类的文件名如:gb19070122abcxd.jpg这样一种英文加数字组合的文件名,这样的文件名,Apache当然是可以解析的,客户坚持一定我上传的图片是中文名(连中文描述都不行),因为,客户说:我们是中国人,当然用中文图片名。。。
没办法,找了半天,找到一篇日文的教程,还好还好,N年前学过一点点日语,照着教程把它啃下来了。
这是一个日本人写的关于在Apache中支持以亚州文字命名文件名的一个“补丁”,叫“mod_encoding”。
相关配置:
1. 下载完后是一个这样的压缩包:mod_encoding-20021209.tar.gz
2. 解压后使用:
configure make make install |
在make这一行时,编译出错,报“make: *** [mod_encoding.so] Error 1”这样的错
原因很明显,是regex.h未包含进来,解决办法也很简单:
ü 用vi打开mod_encoding.c,
ü 在#include <httpd.h>那一段的前面加上如下一行:
#include <regex.h>然后:
重新make再make install 搞定,CALL!!!
3. 编译后得到一个:mod_encoding.so的文件,然后在httpd.conf文件中加入下面这几行:
LoadModule encoding_module modules/mod_encoding.so Header add MS-Author-Via "DAV" <IfModule mod_encoding.c> EncodingEngine on NormalizeUsername on SetServerEncoding GBK DefaultClientEncoding UTF-8 GBK GB2312 AddClientEncoding "(Microsoft .* DAV $)" UTF-8 GBK GB2312 AddClientEncoding "Microsoft .* DAV" UTF-8 GBK GB2312 AddClientEncoding "Microsoft-WebDAV*" UTF-8 GBK GB2312 </IfModule> |
4. 重启Apache,搞定,在apache中我们的url可以是中文名的附件了。
3.7 不可忽视的keepalive选项
在Apache 服务器中,KeepAlive是一个布尔值,On 代表打开,Off 代表关闭,这个指令在其他众多的 HTTPD 服务器中都是存在的。
KeepAlive 配置指令决定当处理完用户发起的 HTTP 请求后是否立即关闭 TCP 连接,如果 KeepAlive 设置为On,那么用户完成一次访问后,不会立即断开连接,如果还有请求,那么会继续在这一次 TCP 连接中完成,而不用重复建立新的 TCP 连接和关闭TCP 连接,可以提高用户访问速度。
那么我们考虑3种情况:
1.用户浏览一个网页时,除了网页本身外,还引用了多个javascript 文件,多个css 文件,多个图片文件,并且这些文件都在同一个HTTP 服务器上。
2.用户浏览一个网页时,除了网页本身外,还引用一个javascript 文件,一个图片文件。
3.用户浏览的是一个动态网页,由程序即时生成内容,并且不引用其他内容。
对于上面3中情况,我认为:1 最适合打开 KeepAlive ,2 随意,3 最适合关闭 KeepAlive
下面我来分析一下原因。
在 Apache 中,打开和关闭 KeepAlive 功能,服务器端会有什么异同呢?
先看看理论分析。
打开KeepAlive 后,意味着每次用户完成全部访问后,都要保持一定时间后才关闭会关闭TCP 连接,那么在关闭连接之前,必然会有一个Apache进程对应于该用户而不能处理其他用户,假设KeepAlive 的超时时间为10 秒种,服务器每秒处理 50个独立用户访问,那么系统中 Apache 的总进程数就是 10 * 50 = 500 个,如果一个进程占用 4M 内存,那么总共会消耗 2G内存,所以可以看出,在这种配置中,相当消耗内存,但好处是系统只处理了 50次 TCP 的握手和关闭操作。
如果关闭KeepAlive,如果还是每秒50个用户访问,如果用户每次连续的请求数为3个,那么 Apache 的总进程数就是 50 * 3= 150 个,如果还是每个进程占用 4M 内存,那么总的内存消耗为 600M,这种配置能节省大量内存,但是,系统处理了 150 次 TCP的握手和关闭的操作,因此又会多消耗一些 CPU 资源。
再看看实践的观察。
我在一组大量处理动态网页内容的服务器中,起初打开KeepAlive功能,经常观察到用户访问量大时Apache进程数也非常多,系统频繁使用交换内存,系统不稳定,有时负载会出现较大波动。关闭了KeepAlive功能后,看到明显的变化是:Apache 的进程数减少了,空闲内存增加了,用于文件系统Cache的内存也增加了,CPU的开销增加了,但是服务更稳定了,系统负载也比较稳定,很少有负载大范围波动的情况,负载有一定程度的降低;变化不明显的是:访问量较少的时候,系统平均负载没有明显变化。
总结一下:
在内存非常充足的服务器上,不管是否关闭KeepAlive 功能,服务器性能不会有明显变化;
如果服务器内存较少,或者服务器有非常大量的文件系统访问时,或者主要处理动态网页服务,关闭KeepAlive 后可以节省很多内存,而节省出来的内存用于文件系统Cache,可以提高文件系统访问的性能,并且系统会更加稳定。
ü 补充1
关于是否应该关闭 KeepAlive 选项,我觉得可以基于下面的一个公式来判断。
在理想的网络连接状况下,系统的Apache 进程数和内存使用可以用如下公式表达:
HttpdProcessNumber= KeepAliveTimeout * TotalRequestPerSecond / Average(KeepAliveRequests)
HttpdUsedMemory= HttpdProcessNumber * MemoryPerHttpdProcess
换成中文意思:
总Apache进程数 = KeepAliveTimeout * 每秒种HTTP请求数 / 平均KeepAlive请求
Apache占用内存 = 总Apache进程数 * 平均每进程占用内存数
需要特别说明的是:
[平均KeepAlive请求] 数,是指每个用户连接上服务器后,持续发出的 HTTP 请求数。当 KeepAliveTimeout 等 0或者 KeepAlive 关闭时,KeepAliveTimeout 不参与乘的运算从上面的公式看,如果 [每秒用户请求]多,[KeepAliveTimeout] 的值大,[平均KeepAlive请求] 的值小,都会造成 [Apache进程数] 多和 [内存]多,但是当 [平均KeepAlive请求] 的值越大时,[Apache进程数] 和 [内存] 都是趋向于减少的。
基于上面的公式,我们就可以推算出当 平均KeepAlive请求 <= KeepAliveTimeout 时,关闭 KeepAlive 选项是划算的,否则就可以考虑打开。
ü 补充2
KeepAlive 该参数控制Apache是否允许在一个连接中有多个请求,默认打开。但对于大多数论坛类型站点来说,通常设置为off以关闭该支持。
ü 补充3
如果服务器前跑有应用squid服务,或者其它七层设备,KeepAlive On 设定要开启持续长连接
实际在 前端有squid 的情况下,KeepAlive 很关键。记得On。
Keeyalive不能随心所欲设置,而是需要根据实际情况,我们来看一个真实的在我工作中发生的搞笑一次事件:
当时我已经离开该项目了,该项目的TeamLeader看到了keepalive的概念,他只看到了关闭keeyalive可以节省web服务器的内存,当时我们的web服务器只有4gb内存,而并发请求的量很大,因此他就把这个keepalive设成了off。
然后直接导致脱机客户端(脱机客户端用的是.net然后webservice连接)的“login”每次都显示“出错”。
一查代码才知道,由于这个脱机客户端使用的是webservice访问,.net开发团队在login功能中设了一个超时,30秒,30秒timeout后就认为服务器没有开启,结果呢由于原来的apache设的是keeyalive和timeout 15秒,现在被改成了off,好家伙,根本就没有了这个timeout概念,因此每次.net登录直接被apache弹回来,因为没有了这个timeout的接口了。
由此可见,学东西。。。不能一知半解,务必求全面了解哈。
3.8 HostnameLookups设置为off
尽量较少DNS查询的次数。如果你使用了任何”Allow fromdomain”或”Denyfrom domain”指令(也就是domain使用的是主机名而不是IP地址),则代价是要进行两次DNS查询(一次正向和一次反向,以确认没有作假)。所以,为了得到最高的性能,应该避免使用这些指令(不用域名而用IP地址也是可以的)。
从“第三天”的性能测试一节中,我们得知了决定性能测试的几个重要指标,它们是:
ü 吞吐量
ü Responsetime
ü Cpuload
ü MemoryUsage
我们也在第三天的学习中对Apache做过了一定的优化,使其最优化上述4大核心指标的读数,那么我们的Apache调优了,我们的Tomcat也作些相应的调整,当完成今的课程后,到时你的“小猫”到时真的会“飞”起来的,所以请用心看完,这篇文章一方面用来向那位曾写过“Tomcat如何承受1000个用户”的作都的敬,一方面又是这篇原文的一个扩展,因为在把原文的知识用到相关的两个大工程中去后解决了:
1) 承受更大并发用户数
2) 取得了良好的性能与改善(系统平均性能提升达20倍,极端一个交易达80倍)。
另外值的一提的是,我们当时工程里用的“小猫”是跑在32位机下的, 也就是我们的JVM最大受到2GB内存的限制,都已经跑成“飞”了。。。。。。如果在64位机下跑这头“小猫”。。。。。。大家可想而知,会得到什么样的效果呢?下面就请请详细的设置吧!

二、一切基于JVM(内存)的优化
2.1 32位操作系统与64位操作系统中JVM的对比
我们一般的开发人员,基本用的是都是32位的Windows系统,这就导致了一个严重的问题即:32位windows系统对内存限制,下面先来看一个比较的表格:
操作系统 |
操作系统位数 |
内存限制 |
解决办法 |
Winxp |
32 |
4GB |
超级兔子 |
Win7 |
32 |
4GB |
可以通过设置/PAE |
Win2003 |
32 |
可以突破4GB达16GB |
必需要装win2003 advanced server且要打上sp2补丁 |
Win7 |
64 |
无限制 |
机器能插多少内存,系统内存就能支持到多大 |
Win2003 |
64 |
无限制 |
机器能插多少内存,系统内存就能支持到多大 |
Linux |
64 |
无限制 |
机器能插多少内存,系统内存就能支持到多大 |
Unix |
64 |
无限制 |
机器能插多少内存,系统内存就能支持到多大 |
上述问题解决后,我们又碰到一个新的问题,32位系统下JVM对内存的限制:不能突破2GB内存,即使你在Win2003 Advanced Server下你的机器装有8GB-16GB的内存,而你的JAVA,只能用到2GB的内存。
其实我一直很想推荐大家使用Linux或者是Mac操作系统的,而且要装64位,因为必竟我们是开发用的不是打游戏用的,而Java源自Unix归于Unix(Linux只是运行在PC上的Unix而己)。
所以很多开发人员运行在win32位系统上更有甚者在生产环境下都会布署win32位的系统,那么这时你的Tomcat要优化,就要讲究点技巧了。而在64位操作系统上无论是系统内存还是JVM都没有受到2GB这样的限制。
Tomcat的优化分成两块:
ü Tomcat启动命令行中的优化参数即JVM优化
ü Tomcat容器自身参数的优化(这块很像ApacheHttp Server)
这一节先要讲的是Tomcat启动命令行中的优化参数。
Tomcat首先跑在JVM之上的,因为它的启动其实也只是一个java命令行,首先我们需要对这个JAVA的启动命令行进行调优。
需要注意的是:
这边讨论的JVM优化是基于Oracle Sun的jdk1.6版有以上,其它JDK或者低版本JDK不适用。
2.2 Tomcat启动行参数的优化
Tomcat 的启动参数位于tomcat的安装目录\bin目录下,如果你是Linux操作系统就是catalina.sh文件,如果你是Windows操作系统那么你需要改动的就是catalina.bat文件。打开该文件,一般该文件头部是一堆的由##包裹着的注释文字,找到注释文字的最后一段如:
# $Id: catalina.sh 522797 2007-03-27 07:10:29Z fhanik $ # ----------------------------------------------------------------------------- # OS specific support. $var _must_ be set to either true or false. |
敲入一个回车,加入如下的参数
Linux系统中tomcat的启动参数
export JAVA_OPTS="-server -Xms1400M -Xmx1400M -Xss512k -XX:+AggressiveOpts -XX:+UseBiasedLocking -XX:PermSize=128M -XX:MaxPermSize=256M -XX:+DisableExplicitGC -XX:MaxTenuringThreshold=31 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -Djava.awt.headless=true " |
Windows系统中tomcat的启动参数
set JAVA_OPTS=-server -Xms1400M -Xmx1400M -Xss512k -XX:+AggressiveOpts -XX:+UseBiasedLocking -XX:PermSize=128M -XX:MaxPermSize=256M -XX:+DisableExplicitGC -XX:MaxTenuringThreshold=31 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -Djava.awt.headless=true |
上面参数好多啊,可能有人写到现在都没见一个tomcat的启动命令里加了这么多参数,当然,这些参数只是我机器上的,不一定适合你,尤其是参数后的value(值)是需要根据你自己的实际情况来设置的。
参数解释:
ü -server
我不管你什么理由,只要你的tomcat是运行在生产环境中的,这个参数必须给我加上
因为tomcat默认是以一种叫java �Cclient的模式来运行的,server即意味着你的tomcat是以真实的production的模式在运行的,这也就意味着你的tomcat以server模式运行时将拥有:更大、更高的并发处理能力,更快更强捷的JVM垃圾回收机制,可以获得更多的负载与吞吐量。。。更。。。还有更。。。
Y给我记住啊,要不然这个-server都不加,那是要打屁股了。
ü -Xms�CXmx
即JVM内存设置了,把Xms与Xmx两个值设成一样是最优的做法,有人说Xms为最小值,Xmx为最大值不是挺好的,这样设置还比较人性化,科学化。人性?科学?你个头啊。
大家想一下这样的场景:
一个系统随着并发数越来越高,它的内存使用情况逐步上升,上升到最高点不能上升了,开始回落,你们不要认为这个回落就是好事情,由其是大起大落,在内存回落时它付出的代价是CPU高速开始运转进行垃圾回收,此时严重的甚至会造成你的系统出现“卡壳”就是你在好好的操作,突然网页像死在那边一样几秒甚至十几秒时间,因为JVM正在进行垃圾回收。
因此一开始我们就把这两个设成一样,使得Tomcat在启动时就为最大化参数充分利用系统的效率,这个道理和jdbcconnection pool里的minpool size与maxpool size的需要设成一个数量是一样的原理。
如何知道我的JVM能够使用最大值啊?拍脑袋?不行!
在设这个最大内存即Xmx值时请先打开一个命令行,键入如下的命令:
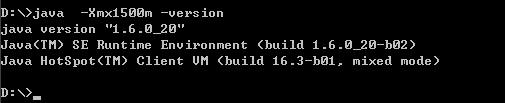
看,能够正常显示JDK的版本信息,说明,这个值你能够用。不是说32位系统下最高能够使用2GB内存吗?即:2048m,我们不防来试试
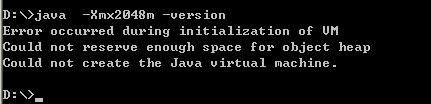
可以吗?不可以!不要说2048m呢,我们小一点,试试1700m如何
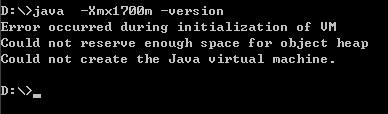
嘿嘿,连1700m都不可以,更不要说2048m了呢,2048m只是一个理论数值,这样说吧我这边有几台机器,有的机器-Xmx1800都没问题,有的机器最高只能到-Xmx1500m。
因此在设这个-Xms与-Xmx值时一定一定记得先这样测试一下,要不然直接加在tomcat启动命令行中你的tomcat就再也起不来了,要飞是飞不了,直接成了一只瘟猫了。
ü �CXmn
设置年轻代大小为512m。整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
ü -Xss
是指设定每个线程的堆栈大小。这个就要依据你的程序,看一个线程 大约需要占用多少内存,可能会有多少线程同时运行等。一般不易设置超过1M,要不然容易出现out ofmemory。
ü -XX:+AggressiveOpts
作用如其名(aggressive),启用这个参数,则每当JDK版本升级时,你的JVM都会使用最新加入的优化技术(如果有的话)
ü -XX:+UseBiasedLocking
启用一个优化了的线程锁,我们知道在我们的appserver,每个http请求就是一个线程,有的请求短有的请求长,就会有请求排队的现象,甚至还会出现线程阻塞,这个优化了的线程锁使得你的appserver内对线程处理自动进行最优调配。
ü -XX:PermSize=128M-XX:MaxPermSize=256M
JVM使用-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64;
在数据量的很大的文件导出时,一定要把这两个值设置上,否则会出现内存溢出的错误。
由XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。
那么,如果是物理内存4GB,那么64分之一就是64MB,这就是PermSize默认值,也就是永生代内存初始大小;
四分之一是1024MB,这就是MaxPermSize默认大小。
ü -XX:+DisableExplicitGC
在程序代码中不允许有显示的调用”System.gc()”。看到过有两个极品工程中每次在DAO操作结束时手动调用System.gc()一下,觉得这样做好像能够解决它们的out ofmemory问题一样,付出的代价就是系统响应时间严重降低,就和我在关于Xms,Xmx里的解释的原理一样,这样去调用GC导致系统的JVM大起大落,性能不到什么地方去哟!
ü -XX:+UseParNewGC
对年轻代采用多线程并行回收,这样收得快。
ü -XX:+UseConcMarkSweepGC
即CMS gc,这一特性只有jdk1.5即后续版本才具有的功能,它使用的是gc估算触发和heap占用触发。
我们知道频频繁的GC会造面JVM的大起大落从而影响到系统的效率,因此使用了CMS GC后可以在GC次数增多的情况下,每次GC的响应时间却很短,比如说使用了CMS GC后经过jprofiler的观察,GC被触发次数非常多,而每次GC耗时仅为几毫秒。
ü -XX:MaxTenuringThreshold
设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概率。
这个值的设置是根据本地的jprofiler监控后得到的一个理想的值,不能一概而论原搬照抄。
ü -XX:+CMSParallelRemarkEnabled
在使用UseParNewGC 的情况下, 尽量减少 mark 的时间
ü -XX:+UseCMSCompactAtFullCollection
在使用concurrent gc 的情况下, 防止 memoryfragmention, 对live object 进行整理, 使 memory 碎片减少。
ü -XX:LargePageSizeInBytes
指定 Java heap的分页页面大小
ü -XX:+UseFastAccessorMethods
get,set 方法转成本地代码
ü -XX:+UseCMSInitiatingOccupancyOnly
指示只有在 oldgeneration 在使用了初始化的比例后concurrent collector 启动收集
ü -XX:CMSInitiatingOccupancyFraction=70
CMSInitiatingOccupancyFraction,这个参数设置有很大技巧,基本上满足(Xmx-Xmn)*(100- CMSInitiatingOccupancyFraction)/100>=Xmn就不会出现promotion failed。在我的应用中Xmx是6000,Xmn是512,那么Xmx-Xmn是5488兆,也就是年老代有5488 兆,CMSInitiatingOccupancyFraction=90说明年老代到90%满的时候开始执行对年老代的并发垃圾回收(CMS),这时还 剩10%的空间是5488*10%=548兆,所以即使Xmn(也就是年轻代共512兆)里所有对象都搬到年老代里,548兆的空间也足够了,所以只要满 足上面的公式,就不会出现垃圾回收时的promotion failed;
因此这个参数的设置必须与Xmn关联在一起。
ü -Djava.awt.headless=true
这个参数一般我们都是放在最后使用的,这全参数的作用是这样的,有时我们会在我们的J2EE工程中使用一些图表工具如:jfreechart,用于在web网页输出GIF/JPG等流,在winodws环境下,一般我们的app server在输出图形时不会碰到什么问题,但是在linux/unix环境下经常会碰到一个exception导致你在winodws开发环境下图片显示的好好可是在linux/unix下却显示不出来,因此加上这个参数以免避这样的情况出现。
上述这样的配置,基本上可以达到:
ü 系统响应时间增快
ü JVM回收速度增快同时又不影响系统的响应率
ü JVM内存最大化利用
ü 线程阻塞情况最小化
2.3 Tomcat容器内的优化
前面我们对Tomcat启动时的命令进行了优化,增加了系统的JVM可使用数、垃圾回收效率与线程阻塞情况、增加了系统响应效率等还有一个很重要的指标,我们没有去做优化,就是吞吐量。
还记得我们在第三天的学习中说的,这个系统本身可以处理1000,你没有优化和配置导致它默认只能处理25。因此下面我们来看Tomcat容器内的优化。
打开tomcat安装目录\conf\server.xml文件,定位到这一行:
<Connector port="8080" protocol="HTTP/1.1" |
这一行就是我们的tomcat容器性能参数设置的地方,它一般都会有一个默认值,这些默认值是远远不够我们的使用的,我们来看经过更改后的这一段的配置:
<Connector port="8080" protocol="HTTP/1.1" URIEncoding="UTF-8" minSpareThreads="25" maxSpareThreads="75" enableLookups="false" disableUploadTimeout="true" connectionTimeout="20000" acceptCount="300" maxThreads="300" maxProcessors="1000" minProcessors="5" useURIValidationHack="false" compression="on" compressionMinSize="2048" compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain" redirectPort="8443" /> |
好大一陀唉。。。。。。
没关系,一个个来解释
ü URIEncoding=”UTF-8”
使得tomcat可以解析含有中文名的文件的url,真方便,不像apache里还有搞个mod_encoding,还要手工编译
ü maxSpareThreads
maxSpareThreads 的意思就是如果空闲状态的线程数多于设置的数目,则将这些线程中止,减少这个池中的线程总数。
ü minSpareThreads
最小备用线程数,tomcat启动时的初始化的线程数。
ü enableLookups
这个功效和Apache中的HostnameLookups一样,设为关闭。
ü connectionTimeout
connectionTimeout为网络连接超时时间毫秒数。
ü maxThreads
maxThreads Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可创建的最大的线程数,即最大并发数。
ü acceptCount
acceptCount是当线程数达到maxThreads后,后续请求会被放入一个等待队列,这个acceptCount是这个队列的大小,如果这个队列也满了,就直接refuse connection
ü maxProcessors与minProcessors
在 Java中线程是程序运行时的路径,是在一个程序中与其它控制线程无关的、能够独立运行的代码段。它们共享相同的地址空间。多线程帮助程序员写出CPU最 大利用率的高效程序,使空闲时间保持最低,从而接受更多的请求。
通常Windows是1000个左右,Linux是2000个左右。
ü useURIValidationHack
我们来看一下tomcat中的一段源码:
security if (connector.getUseURIValidationHack()) { String uri = validate(request.getRequestURI()); if (uri == null) { res.setStatus(400); res.setMessage("Invalid URI"); throw new IOException("Invalid URI"); } else { req.requestURI().setString(uri); // Redoing the URI decoding req.decodedURI().duplicate(req.requestURI()); req.getURLDecoder().convert(req.decodedURI(), true); } } |
可以看到如果把useURIValidationHack设成"false",可以减少它对一些url的不必要的检查从而减省开销。
ü enableLookups="false"
为了消除DNS查询对性能的影响我们可以关闭DNS查询,方式是修改server.xml文件中的enableLookups参数值。
ü disableUploadTimeout
类似于Apache中的keeyalive一样
ü 给Tomcat配置gzip压缩(HTTP压缩)功能
compression="on" compressionMinSize="2048" compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain" |
HTTP 压缩可以大大提高浏览网站的速度,它的原理是,在客户端请求网页后,从服务器端将网页文件压缩,再下载到客户端,由客户端的浏览器负责解压缩并浏览。相对于普通的浏览过程HTML,CSS,Javascript , Text ,它可以节省40%左右的流量。更为重要的是,它可以对动态生成的,包括CGI、PHP , JSP , ASP , Servlet,SHTML等输出的网页也能进行压缩,压缩效率惊人。
1)compression="on" 打开压缩功能
2)compressionMinSize="2048" 启用压缩的输出内容大小,这里面默认为2KB
3)noCompressionUserAgents="gozilla, traviata" 对于以下的浏览器,不启用压缩
4)compressableMimeType="text/html,text/xml" 压缩类型
最后不要忘了把8443端口的地方也加上同样的配置,因为如果我们走https协议的话,我们将会用到8443端口这个段的配置,对吧?
<!--enable tomcat ssl--> <Connector port="8443" protocol="HTTP/1.1" URIEncoding="UTF-8" minSpareThreads="25" maxSpareThreads="75" enableLookups="false" disableUploadTimeout="true" connectionTimeout="20000" acceptCount="300" maxThreads="300" maxProcessors="1000" minProcessors="5" useURIValidationHack="false" compression="on" compressionMinSize="2048" compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain" SSLEnabled="true" scheme="https" secure="true" clientAuth="false" sslProtocol="TLS" keystoreFile="d:/tomcat2/conf/shnlap93.jks" keystorePass="aaaaaa" /> |
好了,所有的Tomcat优化的地方都加上了。结合第三天中的Apache的性能优化,我们这个架构可以“飞奔”起来了,当然这边把有提及任何关于数据库优化的步骤,但仅凭这两步,我们的系统已经有了很大的提升。
举个真实的例子:上一个项目,经过4轮performance testing,第一轮进行了问题的定位,第二轮就是进行了apache+tomcat/weblogic的优化,第三轮是做集群优化,第四轮是sql与codes的优化。
在到达第二轮时,我们的性能已经提升了多少倍呢?我们来看一个loaderrunner的截图吧:


左边第一列是第一轮没有经过任何调优的压力测试报告。
右边这一列是经过了apache优化,tomcat优化后得到的压力测试报告。
大家看看,这就提高了多少倍?这还只是在没有改动代码的情况下得到的改善,现在明白了好好的调优一个apache和tomcat其实是多么的重要了?如果加上后面的代码、SQL的调优、数据库的调优。。。。。。所以我在上一个工程中有单笔交易性能(无论是吞吐量、响应时间)提高了80倍这样的极端例子的存在。
一、为何要集群
单台App Server再强劲,也有其瓶劲,先来看一下下面这个真实的场景。

当时这个工程是这样的,tomcat这一段被称为web zone,里面用spring+ws,还装了一个jboss的规则引擎Guvnor5.x,全部是ws没有service layer也没有dao layer。
然后App Zone这边是weblogic,传输用的是spring rmi,然后App Zone这块全部是service layer, dao layer和数据库打交道。
用户这边用的是.net,以ws和web zone连的。
时间一长,数据一多,就出问题了。
拿Loader Runner跑下来,发觉是Web Zone这块,App Server已经被用到极限了。因为客户钱不多,所以当时的Web Zone是2台服务器,且都是32位的,内存不少,有8GB,测试下来后发觉cpu loader又不高,但是web server这边的吞吐量始终上不去,且和.net客户端那边响应越来越慢。
分析了一下原因:单台tomcat能够承受的最大负载已经到头了,单台tomcat的吞吐量就这么点,还要负担Guvnor的运行,Guvnor内有数百条业务规则要执行。
再看了一下其它方面的代码、SQL调优都已经到了极限了,所以最后没办法,客户又不肯拿钱投在内存和新机器上或者是再买台Weblogic,只能取舍一下,搞Tomcat集群了。
二、集群分类

Tomcat作集群的逻辑架构是上面这样的一张图,关键是我们的production环境还需要规划好我们的物理架构。
2.1 横向集群
比如说,有两台Tomcat,分别运行在2台物理机上,好处是最大的即CPU扩展,内存也扩展了,处理能力也扩展了。

2.2 纵向集群
即,两个Tomcat的实例运行在一台物理器上,充分利用原有内存,CPU未得到扩展。
2.3 横向还是纵向
一般来说,广为人们接受的是横向扩展的集群,可做大规模集群布署。但是我们这个case受制于客户即:
ü 不会再投入新机器了
ü 不会增加内存了
但是呢,通过压力测试报告我们可知:
ü 原有TomcatServer的CPU Loader不高,在23%左右
ü 原有TomcatServer上有8GB内存,而且是32位的,单台Tomcat只使用了1800MB左右的内存
ü 网络流量不高,单块千兆以太网卡完全可以处理掉
因此,我们只能做熊掌与鱼不能兼得的事,即采用了:纵向集群。
2.4 Load Balance与High Available
ü Load Balance
简称LB即负载均衡,相当于1000根线程每个集群节点:Node负责处理500个,这样的效率是最高的。
ü High Available
简称HA即高可用性,相当于1000根线程还是交给一台机器去慢慢处理,如果这台机器崩了,另一台机器顶上。
三、集群架构中需要解决的问题
集群规划好了怎么分,这不等于就可以开始实现集群了,一旦你的系统实现了集群,随之而来的问题就会出现了。
我们原有系统中有这样几个问题,在集群环境中是需要解决的,来看:
3.1 解决上传文件同步的问题
集群后就是两个Tomcat了,即和两个线程读同一个resource的问题是一样的,还好,我们原有上传文件是专门有一台文件伺服器的,这个问题不大,两个tomcat都往一台file server里上传,文件伺服器已经帮我们解决了同名文件冲突的这个问题了,如果原先的做法是把文件上传到Tomcat的目录中,那问题就大了,来看:
集群环境中,对于用户来说一切操作都是透明的,他也不知道我有几个Tomcat的实例运行在那边。
用户一点上传,可能上传到了Tomcat2中,但是下次要显示这个文件时,可能用到的是Tomcat1内的jsp或者是class,对不对?
于是,因为你把图片存在了Tomcat的目录中,因此导致了Tomcat1在显示图片时,取不到Tomcat2目录中存放的图片。
因此我们在工程一开始就强调存图片时要用一台专门的文件服务器或者是FTP服务器来存,就是为了避免将来出现这样的问题。
3.2 解决Quartz在集群环境中的同步问题
我们的系统用到一个Quartz(一个定时服务组件)来定时触发一些自动机制,现在有了两个Tomcat,粗想想每个Tomcat里运行自己的Quartz不就行了?
但是问题来了,如果两个Quartz在同一时间都触发了处理同一条定单,即该条定单会被处理两边。。。这不是影响效率和增加出错机率了吗?
因为本身Quartz所承受的压力几乎可以忽略不计的,它只是定时会触发脚本去运行,关键在于这个定时脚本的同步性,一致性的问题上。
我们曾想过的解决方法:
我们可以让一个Tomcat布署Quartz,另一个Tomcat里不布署Quartz
但这样做的结果就是如果布署Quartz的这个Tomcat崩溃掉了,这个Quartz是不是也崩啦?
最后解决的办法:
所以我们还是必须在两台Tomcat里布署Quartz,然后使用HA的原则,即一个Quartz在运行时,另一台Quartz在监视着,并且不断的和另一个Quartz之间保持勾通,一旦运行着的Quartz崩掉了,另一个Quartz在指定的秒数内起来接替原有的Quartz继续运行,对于Quartz,我们同样也是面临着一个熊掌与鱼不能皆得的问题了,Quartz本身是支持集群的,而它支持的集群方式正是HA,和我们想的是一致的。
具体Quartz是如何在集群环境下作布署的,请见我的另一篇文章:quartz在集群环境下的最终解决方案
解决了上述的问题后基本我们可以开始布署Tomcat这个集群了。
四、布署Tomcat集群
准备两个版本一致的Tomcat,分别起名为tomcat1,tomcat2。
4.1 Apache中的配置
worker.properties文件内容的修改
打开Apache HttpServer中的apache安装目录/conf/work.properties文件,大家还记得这个文件吗?
这是原有文件内容:
workers.tomcat_home=d:/tomcat2 workers.java_home=C:/jdk1.6.32 ps=/ worker.list=ajp13 worker.ajp13.port=8009 worker.ajp13.host=localhost worker.ajp13.type=ajp13 |
现在开始改动成下面这样的内容(把原有的worker.properties中的内容前面都加上#注释掉):
#workers.tomcat_home=d:/tomcat2 #workers.java_home=C:/jdk1.6.32 #ps=/ #worker.list=ajp13 #worker.ajp13.port=8009 #worker.ajp13.host=localhost #worker.ajp13.type=ajp13 worker.list = controller #tomcat1 worker.tomcat1.port=8009 worker.tomcat1.host=localhost worker.tomcat1.type=ajp13 worker.tomcat1.lbfactor=1 #tomcat2 worker.tomcat2.port=9009 worker.tomcat2.host=localhost worker.tomcat2.type=ajp13 worker.tomcat2.lbfactor=1 #========controller======== worker.controller.type=lb worker.controller.balance_workers=tomcat1,tomcat2 worker.lbcontroller.sticky_session=0 worker.controller.sticky_session_force=true worker.connection_pool_size=3000 worker.connection_pool_minsize=50 worker.connection_pool_timeout=50000 |
上面的这些设置的意思用中文来表达就是:
ü 两个tomcat,都位于localhost
ü 两个tomcat,tomcat1用8009,tomcat2用9009与apache保持jk_mod的通讯
ü 不采用sticky_session的机制
sticky_session即:假设现在用户正连着tomcat1,而tomcat1崩了,那么此时它的session应该被复制到tomcat2上,由tomcat2继续负责该用户的操作,这就是load balance,此时这个用户因该可以继续操作。
如果你的sticky_session设成了1,那么当你连的这台tomcat崩了后,你的操作因为是sticky(粘)住被指定的集群节点的,因此你的session是不会被复制和同步到另一个还存活着的tomcat节点上的。
ü 两台tomcat被分派到的任务的权重(lbfactor)为一致
你也可以设tomcat1 的worker.tomcat2.lbfactor=10,而tomcat2的worker.tomcat2.lbfactor=2,这个值越高,该tomcat节点被分派到的任务数就越多
httpd.conf文件内容的修改
找到下面这一行:
Include conf/extra/httpd-ssl.conf |
我们将它注释掉,因为我们在集群环境中不打算采用https,如果采用是https也一样,只是为了减省开销(很多人都是用自己的开发电脑在做实验哦)。
#Include conf/extra/httpd-ssl.conf |
找到原来的“<VirtualHost>”段
改成如下形式:
<VirtualHost *> DocumentRoot d:/www <Directory "d:/www/cbbs"> AllowOverride None Order allow,deny Allow from all </Directory> <Directory "d:/www/cbbs/WEB-INF"> Order deny,allow Deny from all </Directory> ServerAdmin localhost DocumentRoot d:/www/ ServerName shnlap93:80 DirectoryIndex index.html index.htm index.jsp index.action ErrorLog logs/shsc-error_log.txt CustomLog logs/shsc-access_log.txt common JkMount /*WEB-INF controller JkMount /*j_spring_security_check controller JkMount /*.action controller JkMount /servlet/* controller JkMount /*.jsp controller JkMount /*.do controller JkMount /*.action controller JkMount /*fckeditor/editor/filemanager/connectors/*.* controller JkMount /fckeditor/editor/filemanager/connectors/* controller </VirtualHost> |
注意:
原来的JKMount *** 后的 ajp13变成了什么了?
controller
4.2 tomcat中的配置
可以拿原有的tomcat复制成另一个tomcat,分别为d:\tomcat, d:\tomcat2。
打开tomcat中的conf目录中的server.xml,找到下面这行
1)
<Server port="8005" shutdown="SHUTDOWN"> |
记得:
一定要把tomcat2中的这边的”SHUTDOWN”的port改成另一个端口号,两个tomcat如果是在集群环境中,此处的端口号绝不能一样。
2)找到
<Connector port="8080" protocol="HTTP/1.1" |
确保tomcat2中此处的端口不能为8080,我们就使用9090这个端口吧
3)把两个tomcat中原有的https的配置,整段去除
4)找到
<Connector port="8080" protocol="HTTP/1.1" URIEncoding="UTF-8" minSpareThreads="25" maxSpareThreads="75" enableLookups="false" disableUploadTimeout="true" connectionTimeout="20000" acceptCount="300" maxThreads="300" maxProcessors="1000" minProcessors="5" useURIValidationHack="false" compression="on" compressionMinSize="2048" compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain" redirectPort="8443" /> |
确保tomcat2中这边的redirectPort为9443
5)找到
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" |
改为:
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" URIEncoding="UTF-8" minSpareThreads="25" maxSpareThreads="75" enableLookups="false" disableUploadTimeout="true" connectionTimeout="20000" acceptCount="300" maxThreads="300" maxProcessors="1000" minProcessors="5" useURIValidationHack="false" compression="on" compressionMinSize="2048" compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain" /> |
确保tomcat2的server.xml中此处的8009被改成了9009且其它内容与上述内容一致(redirectPort不要忘了改成9443)
6)找到
<Engine name="Standalone" defaultHost="localhost" jvmRoute="jvm1"> |
改成
<!-- You should set jvmRoute to support load-balancing via AJP ie : <Engine name="Standalone" defaultHost="localhost" jvmRoute="jvm1"> --> <Engine name="Standalone" defaultHost="localhost" jvmRoute="tomcat1"> |
同时把tomcat2中此处内容改成
<!-- You should set jvmRoute to support load-balancing via AJP ie : <Engine name="Standalone" defaultHost="localhost" jvmRoute="jvm1"> --> <Engine name="Standalone" defaultHost="localhost" jvmRoute="tomcat2"> |
7)
在刚才的
<Engine name="Standalone" defaultHost="localhost" jvmRoute="tomcat1"> |
的下面与在
<!-- The request dumper valve dumps useful debugging information about the request and response data received and sent by Tomcat. Documentation at: /docs/config/valve.html --> <!-- <Valve className="org.apache.catalina.valves.RequestDumperValve"/> --> |
之上,在这之间加入如下一大陀的东西:
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster" channelSendOptions="6"> <Manager className="org.apache.catalina.ha.session.BackupManager" expireSessionsOnShutdown="false" notifyListenersOnReplication="true" mapSendOptions="6"/> <Channel className="org.apache.catalina.tribes.group.GroupChannel"> <Membership className="org.apache.catalina.tribes.membership.McastService" bind="127.0.0.1" address="228.0.0.4" port="45564" frequency="500" dropTime="3000"/> <Receiver className="org.apache.catalina.tribes.transport.nio.NioReceiver" address="auto" port="4001" selectorTimeout="100" maxThreads="6"/> <Sender className="org.apache.catalina.tribes.transport.ReplicationTransmitter"> <Transport className="org.apache.catalina.tribes.transport.nio.PooledParallelSender" timeout="60000"/> </Sender> <Interceptor className="org.apache.catalina.tribes.group.interceptors.TcpFailureDetector"/> <Interceptor className="org.apache.catalina.tribes.group.interceptors.MessageDispatch15Interceptor"/> <Interceptor className="org.apache.catalina.tribes.group.interceptors.ThroughputInterceptor"/> </Channel> <Valve className="org.apache.catalina.ha.tcp.ReplicationValve" filter=".*\.gif;.*\.js;.*\.jpg;.*\.png;.*\.htm;.*\.html;.*\.css;.*\.txt;"/> <ClusterListener className="org.apache.catalina.ha.session.ClusterSessionListener"/> </Cluster> |
此处有一个Receiver port=”xxxx”,两个tomcat中此处的端口号必须唯一,即tomcat中我们使用的是port=4001,那么我们在tomcat2中将使用port=4002
8)把系统环境变更中的CATALINA_HOME与TOMCAT_HOME这两个变量去除掉
9)在每个tomcat的webapps目录下布署同样的一个工程,在布署工程前先确保你把工程中的WEB-INF\we b.xml文件做了如下的修改,在web.xml文件的最未尾即“</web-app>”这一行前加入如下的一行:
<distributable/> |
使该工程中的session可以被tomcat的集群节点进行轮循复制。
4.3 启动集群
好了,现在启动tomcat1, 启动tomcat2(其实无所谓顺序的),来看效果:
分别访问http://localhost:8080/cbbs与http://localhost:9090/cbbs
确保两个tomcat节点都起来了,然后此时,我们启动Apache
然后访问直接用http://localhost/cbbs不加端口的形式访问:
用sally/abcdefg登录,瞧,应用起来了。
然后我们拿另一台物理客户端,登录这个web应用,我们可以看到:
第一个tomcat正在负责处理我们第一次登录的请求。
当有第二个HTTP请求时,另一个tomcat自动开始肩负起我们第二个HTTP请求了,这就是Load Balance。