NETapp WAFL 文件系统
NetApp的文件系统名为WAFL,是专为Filer系统而设计的。WAFL是”Write Anywhere File Layout”,即”任意位置写入文件布局”的缩写。WAFL文件系统和Filer的整合式RAID管理采用一体化设计,以避免大多数带有RAID管理机制的文件系统所固有的性能问题。
网络化存储实际应用中的三个基本要求决定了需要为NetApp Filer设计全新的文件系统:
文件系统应该更加有效地操控RAID机制
增加新的硬盘时,文件系统应该能够相应的动态增长
文件系统应该不需要做消耗大量时间的一致性检查
在这些基本要求之上,引申出了支持数据快照(Snapshot)的要求。
NetApp于 1995年5月提出专利申请,在1998年10月获得专利(专利号码:5,819,292),题目为《Method For Maintaining Consistent States of A File System and For Creating User-Accessible Read-Only Copies of A File System》,前半部分就是有关WAFL的 内容,后半部分则关于数据快照(Snapshot)技术。另一项专利于1995年6月申请,在1998年9月获得专利(专利号码:5,948,110), 题目为《Method For Providing Parity In a RAID Subsystem Using Non-Volatile Memory》,这就是如何利用NVRAM来加速RAID,并保护RAID数据的一致性。WAFL采用有电池保护的NVRAM(非易失性内存)来担任其日志(journal),并藉由consistency points提供文件系统一致性(consistent) 的保证,在非正常断电或关机时,重新开机后可在2分钟内开始提供服务,不需要执行文件系统检查,也不用担心文件系统会损毁。WAFL结合NVRAM、RAID、Snapshot的设计难度极高,故从1992年至今仍未有其它厂商可以做到。
WAFL的主要特点及其所带来的优势包括:
永远一致性的文件系统:任何时刻文件系统均处于一致性的状态,即使遇到非正常断电或不正常关机后,也不需执行硬盘检查,即可在复电后2分钟内迅速提供服务。
具电池保护的NVRAM日志:利用存取速度较硬盘快一千倍的内存,担任文件系统的日志,同时保护metadata及data的交易纪录,并加速写入的效率和反应时间、保证文件系统的一致性、保证写入的交易不会因断电而流失。
内建智能型最佳化的RAID磁盘阵列管理系统:配合NVRAM日志功能,藉由硬盘区块的配置最佳化,可将大量的随机写入转为少量的循序写入,真正达到平行写入 (Stripe Write) 并减少磁头移动的次数和磁头移动的距离的目的,加速文件存取和搜寻的速度。
能增长的文件系统:不需其它软件的协助,就可直接实时动态线上扩增文件系统容量且立刻能使用新增加的容量。每次可只增加一块硬盘或多块硬盘的方式来 扩增,完全不需要停机,也不需要等待时间。另外也可在不扩增容量的前提下,动态线上提高文件数量的上限,完全不需要停机,也不需要等待时间,也不影响系统 运作效率。
瞬间快照备份 (Snapshot):使用不需要移动硬盘区块的WAFL专 利技术,可瞬间备份整个文件系统,每个volume可有255份快照,每个使用者都有自己专属的一个快照目录,可自行恢复只属于自己在任一快照时间点的资 料,完全不需系统管理人员的协助。每个快照备份皆是完整的文件系统备份 (Full File System Backup),不论已有多少份数的备份,系统运作效率皆不受影响。
WAFL作 为专门为网络文件访问而优化的UNIX兼容文件系统。在某些方面,其磁盘格式类似于其它UNIX文件系统,如伯克利快速文件系统(Berkeley Fast File System,以下简称FFS)和IBM TransArc Episode文件系统,相似之处包括:
WAFL是基于数据块的,使用没有片段的4KB大小数据块
WAFL使用inodes来描述其文件
WAFL文件系统中,目录是格式特殊的文件
像IBM TransArc Episode文件系统一样,WAFL使用文件来储存元数据(Meta Data)。WAFL三个最重要的元数据文件是:
inode文件,包含文件系统所有的inode
块图文件,用以识别空闲块
inode图文件,用以识别空闲inode。
这里采用”图”而不是”位图”的称谓,因为这些文件采用多于1位(bit)对每一个路径加以描述。
其中,每一个WAFL inode包含16个块指针,用以表明哪一个数据块属于该文件。不同于伯克利快速文件系统,一个WAFL inode的所有块指针指向的是相同层次上的数据块。这样,对于小于64KB的文件,inode使用16个块指针指向文件数据块;大于64MB的文 件,inode使用块指针指向间接数据块,间接数据块再指向实际的文件数据块。较大文件的inode指向更多的间接数据块。对于十分小的文件,数据储存在 inode本身。
简单的,可以把WAFL理解为数据块树型结构,在树的根部是root inode,root inode是用以描述inode文件的特殊inode。inode文件包含描述系统中其它文件的inode,包括块图和inode图文件。WAFL文件系统数据块树型结构的树叶是所有文件的数据块。如下图所示:
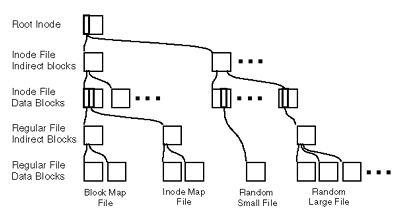
图:WAFL的树型结构示例图
图中显示,文件由不同的数据块组成。较大的文件在inode和实际数据块之间存在额外的间接层次。WAFL要启动的话,必须要找到该树型结构的根部,所以对于WAFL(任意位置写入文件布局)来讲,root inode是个例外,它必须处于硬盘上的固定位置以便WAFL定位。使用文件来保存元数据的方式带来的好处有:
允许在硬盘上任何地方写入元数据块。这就是WAFL名称的起源。与FFS类似,WAFL在其写入分配策略上有着完全的灵活性,数据块不是被永久地分配到固定的磁盘位置上。WAFL利用了这种灵活性来优化Filer的RAID性能。WAFL可以事先规划对同一RAID条带进行多重写入的时间,这样当仅仅更新RAID某一硬盘条带中某一数据块时,就不会对整个写入性能带来损耗。在有关RAID的章节中,详细描述了WAFL采用的旨在有效利用增强型RAID4的写分配策略。
使文件系统的增长变得十分容易。当增加新的硬盘时,Filer可以自动增加元数据文件的大小。如果系统的缺省值稍小,管理员也可以手动增加文件系统中的inode。允许元数据块在硬盘上任何地方写入。这种方式使得SnapShot数据快照功能成为可能。要使SnapShot可以工作,WAFL必须可以把新的数据,包括元数据写入到新的硬盘空间上,而不是覆盖原有数据。如果WAFL在磁盘上固定的位置存储元数据,这项功能就不可能实现。
1、批次动态条带化读写算法
WAFL文 件系统中采用批次动态条带化读写算法。在UNIX或者Windows文件服务器中,写入性能尤其重要,因为它必须直接面对硬盘(或非易失性内存),而读操 作尚可以面对UNIX/Windows客户端和服务器的高速缓存。这就使得UNIX或者Windows客户端和服务器的硬盘写操作要比读操作多5-10 倍。如Ousterhout机构的一项观测证明,当服务器端和客户端高速缓存增大的情况下,对写入操作的响应主导了I/O子系统的处理过程。其影响是 NFS服务器上的磁盘写操作可能比读操作多5倍(相关内容见于Ousterhout 89报告)。
这种需求特点,激发了WAFL在最初的设计中,即最大限度的发挥了写入分配策略的灵活性。WAFL文件系统中,通过批次动态条带化读写算法的三种机制,保证了这种灵活性的实现:
Ÿ WAFL能 把文件系统的任何数据块(除包含root inode的数据块外)写到磁盘中的任何位置上。而在FFS中,诸如inode、位图和元数据被保存在磁盘中的固定位置上,这就妨碍了文件系统写入性能。 例如,对某一新近更新的文件,不能将它的数据块和inode在磁盘上的紧邻位置加以存储。而WAFL则相反,它可以在磁盘上的任何地方加以写入,从而创造性的优化了写入性能。
Ÿ WAFL能把数据块按任何顺序写到磁盘中。与之对应的,FFS仅能把数据块按确定的顺序写到磁盘中,在中断之后可以通过fsck恢复文件系统的一致性。因为WAFL文件系统的映像文件只有在写入一致点信息时才会改变,所以WAFL能按任何顺序写入数据块。
Ÿ WAFL能在单一写入周期内为多个NFS操作同时分配盘空间。而FFS需要为NFS请求一一分配空间。WAFL在 确定文件系统一致点之前可以收集数百个NFS请求,在一致点(consistency points)时刻立即为其分配空间。这种延缓分配写入空间的机制通过从应答处理的过程中去除磁盘分配时间,大大改进了NFS操作的等待时间。对于那些在 到达磁盘前即被删除的数据块而言,这种方式也避免了时间的浪费。
这些特性赋予了WAFL文件系统特别灵活的写入策略。为众多写入同时分配空间的能力使其更加智能化,允许将数据快以任何顺序写入到任何地方的能力又确保了这种策略适用于多种环境。概要地讲:
Ÿ WAFL通过将多数据块写入到同一条带中的方式,大大提高了RAID的效率与性能
Ÿ WAFL通过将相关的块写入到相近的位置而大大缩短了寻道时间
Ÿ WAFL通过将顺序的块放置在RAID阵列中某个单一磁盘上的方式,减少了大文件读出时的磁头冲突
在通常的文件系统下,优化写分配是很困难的,因为以上这些目标之间经常冲突,而WAFL则可以很好的解决所有问题。
2、NVRAM
为在磁盘上保存完整的文件系统一致性版本,WAFL文件系统至少每10秒会生成一个内部数据快照SnapShot,称为一个一致点(consistency point)。当时Filer启动时,WAFL总是使用时间最近的一致点版本,这意味着即使发生掉电或者其它严重系统错误后,系统再次投入正常运转也无需耗时的文件系统检查工作。Filer在仅仅1到2分钟的时间内即可正常启动,而这段时间也主要是花费在磁盘定位和内存检查上。
这种特性是由于Filer使用了由电池支持的NVRAM(非易失性内存)来避免丢失最近一致点之后可能发生的任何NFS与CIFS请求。其工作示意图如下:

图:NVRAM工作示意图
NVRAM是带有电池的独特内存,即使切断电源,仍然可以存储数据。在不正常停机之后,WAFL重演所有”日志”以防丢失。日志类似于线上交易处理(OLTP) 数据库系统的Log记录。WAFL采用内存,而不是硬盘来保存日志,因为比硬盘快一千倍,提供极高的响应速度。即使有大量的交易,响应速度也不会变慢。当使用者的写入要求送到NVRAM并完成时,马上可以接受下一笔的写入要求,又可同时保护metadata及data的交易纪录。当NVRAM收集这些写入要求到达某种条件时,WAFL会先经过计算并整理过后再批次写入到硬盘。其工作情况大体如下:
Ÿ 当Filer正常关闭时,NVRAM不包含任何未处理的NFS请求,它被自动关闭以延长其电池寿命。
Ÿ 在正常系统关闭规程下,文件管理器先关闭NFS与CIFS服务,将所有缓存中的操作写入磁盘,然后关闭NVRAM。
Ÿ 在系统掉电或者其它非正常状况下,系统将会自动重现保存在NVRAM中,但是尚未转存到磁盘上的NFS与CIFS请求。
如上所述,WAFL通 过创建内部SnapShot来避免系统在不正常停机后对文件系统进行检查,这种特殊的SnapShot叫做一致点,每过几秒钟就会自动创建一次。不同于其 它SnapShot快照的是,一个一致点没有名字,而且不能通过NFS协议访问它。同于其它SnapShot快照的是,一致点是整个文件系统的一个完全自 一致的映像。当WAFL重新启动时,它简单地回放为最近的一致点。即使单一分区中包含20GB或者超过20GB的数据,这项特性依然使得Filer可以在1到2分钟的时间内重启。
在一致点之间,WAFL也在把数据写到磁盘中,但是它仅仅写到不使用的块中,如此呈现的数据块树型结构的最近一致点仍然是完全不变的。在两个一致点之间,WAFL需要处理数百或者成千上万的NFS请求,因所以磁盘上面的文件系统映像在数秒内会保持不变,直到WAFL写入新的一致点。磁盘上面的文件系统映像也会自动更新。虽然这项技术在UNIX文件系统中比较少见的,但它在数据库领域是比较常见的。但即使在数据库领域,像WAFL这样在同一时刻的一致点中写入如此多的操作也是比较少见的。
WAFL实际上把NVRAM划分成为两份独立的日志报告。当一份日志写满,WAFL转换到另一份日志,并且开始写一致点,将与第一份日志的差异安全地记录到硬盘上。即使日志没有写满,WAFL每10秒也要写一次新的一致点,以防止硬盘中存储的文件系统映像太过陈旧。
利用NVRAM记录NFS请求的方式比传统的利用NVRAM为磁盘做读写缓存的方式有很多好处。NetApp Filer使用NVRAM来存储未提交NFS请求的方式则与其它一些UNIX产品十分不同:
Ÿ 其它操作系统把NVRAM作为磁盘缓存,并在磁盘层加以使用时,包含的是关键的文件系统一致性数据。如果NVRAM发生故障,即使采用fsck也无法恢复系统状态。
Ÿ WAFL使用NVRAM作为文件系统的遍历来源,而不是需要利用硬盘来加以更新的高速缓存。WAFL对NVRAM空间的使用是非常有效的,例如,要求文件系统创建一个文件的请求仅需使用数百个字节即可描述。而实际的文件创建操作则可能包含着众多的数据块改变。因为WAFL使用NVRAM记录操作的遍历信息,而不是操作结果本身,这就使可以在Filer NVRAM日志文件中执行得数千个操作。
我们来对以上两种机制做一下比较。其它厂商利用硬盘当作日志,只能保障硬盘区块的运作,不能确保网络文件系统交易的安全与完整性,当遭遇网络暂时中断或系统宕机,恢复联机与运作后,中断的网络文件系统交易已经流失。不仅速度无法与NVRAM匹敌,也无法同时保护metadata及data的交易纪录不会流失。
两种不同方式的对比示意图如下:
图:NVRAM与其它厂商技术方式的对比
第一种,是处理NFS请求并将其结果写入磁盘缓存,第二种,是NetApp NVRAM采用的,对那些需要重演的请求,记录下其日志信息。举例来比较,如果从一个目录移动一个文件到另一个目录,文件系统必须更新内容以及来源、目标目录的inode。在FFS中,每一个块是8 KB,这项操作将使用到32 KB的高速缓存空间。而WAFL仅使用大约150个字节空间,简单的记录下需要对该信息执行更名操作。WAFL可以在每MB的NVRAM中记录多于千项操作。
记录NFS请求的最终优势是它大大提高了NFS响应时间。为了响应NFS请求,没有NVRAM的文件系统必须更新它的内存数据结构、为新数据分配磁盘空间,但是它们只是把修改后的数据复制到NVRAM中,而不是磁盘中。相比之下,WAFL能更迅速准确的响应NFS请求,因为它只需要更新其内存数据结构并且记录访问要求,而不需要为新数据分配磁盘空间,也不需要把修改后的数据复制到NVRAM中。
WAFL的全称是Write Anywhere File Layout. 从类似于其它UNIX的文件系统比如Berkeley Fast File System (FFS) 和 TransArc Episode file system. 它的核心理念是"文件任意地方写"。先说普通的文件系统,是由inode和data组成,inode处于硬盘的固定位置(一般是初始位置),OS/磁头默 认就已经知道了inode的地址,inode可以理解成文件的目录,系统启动后读inode文件便知道此文件系统包含有哪些文件并且知道这些文件所在的地 址。而在WAFL里,inode大概分为两层:root inode和inode. root inode是处于硬盘的固定位置。root inode很小,只有128 Bytes. root inode指向inode的地址。inode是可以放在任何地方的。一个inode文件一般只有4KB. 其实在inode这一层里面是有很多链式的inode的。当一个inode文件不够大,放不下一个大data文件的所有地址时,需要有多个inode文件 来为此大data文件"服务",因此WAFL便用上层inode指向下层多个inode的方式。如下图:

RAM存放data缓存,而NVRAM则放操作log. 类似于数据库的archive log.
RAID 3是利用每一条带的长度很短例如一个扇区512bit来实现性能的提升。它用大文件的支持很有效。但对随机IO读写的时候爱莫能助,因为每一个随机IO读 写都要让RAID里的所有硬盘同时工作,它做不到让一个硬盘读写一个IO而另一个硬盘读写另一个IO。所以就有了RAID 4. RAID 4只是改进了RAID 3里的条带长度,比如把512bit改为4KB. 想通过如此来支持随机IO小文件(小于4KB)的读写. 事实上RAID 4是能够支持随机IO读的,但是写的时候就碰到一难题。当一个小于4KB的小文件写的时候需要改写两个盘的数据:Data盘和校验盘,而RAID 4是把其它一个硬盘作为校验盘的,所以当有两个小文件想写的时候,校验盘同一时间只能做一个数据的写了。这样,校验盘便成了瓶颈。这也是为什么后来有 RAID 5的原因。RAID 5把校验盘通过条带化分配给了所有硬盘,提高的并发的几率!所以现在RAID 3和RAID 5都有人用,但RAID 4就不受待见,没人爱用了。
而NetApp到底是如何使用了RAID 4的呢? RAID 4只有一种情况可以并发IO写,那就是当要写的两个或多个小文件刚好处于同一条带时!此时,N个数据盘上的同一条带需要改写数据,并且校验盘的同一条带也 要改写。WAFL便是通过软件层来让这一情况发生。WAFL通过编程来让一段时间内要写的数据尽量处于同一条带,当然,数据大于一个条带时那就处于相邻的 条带了。RAID 4便是如此,WAFL巧妙地利用了它,使它的性能达到最优化。
而RAID DP(Double Parity),其实很类似于RAID 6. 它们的目的都是通过两个校验盘来防止两个数据盘同时掉线而掉数据。只是它们算法不一样。RAID 6用的是数据乘以一个系数后再异或来产生第二个校验数据;而RAID DP是不同条带之间做异或来产生第二个校验数据, 即两个校验盘中一个是横的条带的校验,另一个是斜的条带的校验。在此就不作评细介绍了,RAID的内容有时间再用另一篇幅介绍。
首先看系统如何保护还在内存中缓存的数据。这些数据是要被snapshot的,但它还没被写进磁盘,且在磁盘的inode里也没有信息。所以 系统要对它进行snapshot操作。每个厂商都有不同实现,我不清楚其它厂商是如何做的。而NetApp是把内存的数据分配空间,更新inode从内存 到硬盘;更新块图文件;更新磁盘缓存(注意,是硬盘上的缓存。这点也要保护)
其次,其它厂商可能是复制inode文件来作为snapshot, 而NetApp只是复制root inode来作为snapshot.
最 后,NetApp是用redirect . write方式来保护snapshot数据(红皮书上写的Write . Copy是不确切的。本质上是redirect . write)。即,snapshot完成后,如果有数据要删除,则只是删除root inode、inode里相应的信息,不删除真正的data;而如果有数据要被改写,则不改变原有data,而是把改写后的数据再完整地写在其它地方,即 inode指向其它地址,不占用原有的地址。
1. root inode处于硬盘固定位置,而data和inode可放于任何地方
2. WAFL把data和inode放于相邻的位置。且尽量让一次要写的数据在RAID 4的同一条带上。
3. 利用块图文件来指示某一个块是在被哪个文件系统所用。比如是被当前文件系统所用呢,还是被某一时间的snapshot所用。
4. WAFL从来不覆盖旧块
5. WAFL每次做check point的时候,不仅将实际数据flush到新块,连inode元数据都要写到新块而不覆盖旧块,这也就是snapshot为何胆敢只拷贝root inode就完成了的原因。
RAM里存放将要写进硬盘里的data, 称为data缓存。而NVRAM里存放的着操作的log。log里记录着"新建一个属性为XX的文件", "删除XX文件里的XX内容". NVRAM的空间平均分为两部分,两个空间轮流使用。当一个空间的值超过一定的阀值或者超过10秒,(此时叫consistency point 触发点), 就进行一次flush。即根据NVRAM里的log,把inode写进硬盘,并且清除NVRAM里的log。inode写进去了,那data呢?其实在此 次CP之前,data是不断被写进硬盘里的!flush做的仅是把inode写进去!在flush开始后,NVRAM里另一半的空间就接替了原空间作为当 前空间接替工作。等下个CP来时,又换回另一空间继续工作。(注意,在cluster的时候
WAFL给RAID芯片发送data和地 址. 在这里,RAID芯片可不认识inode和root inode了,RAID只知道data,并且知道哪些data需要存进哪些LBA地址. 若探讨得更底层些,那WAFL层的data和inode是被raid写到同一条带上,当然,RAID会计算出校验数据写进同一条带上的校验盘。而WAFL 层的root inode是被写进硬盘的某一固定位置(应该是头部吧?)。磁盘头从与data/inode的位置到root inode的位置需要一定的寻道时间,这个时间省不了。写数据的顺序是先写data/inode再写root inode.
因为这里也有寻道时 间。之前我便有个疑惑,普通的文件系统从data到inode有寻道时间,而WAFL从data/inode到root inode也有寻道时间,这似乎并不能减少寻道时间的减少。苦苦思索后,只能这么猜想了: NetApp是在写完一个CP中的所有data/inode后,再写root inode. 这样便节省了一定的寻道时间。。这个问题有待以后慢慢思考
如 此一来WAFL便不用耗费大量时间去做一致性检查了。因为它总是先写data,再写root inode. WAFL每10秒就更新一次一致点,这个一致点其实是一个内部的snapshot, 只不过此snapshot无法被访问. 当掉电时,NVRAM可保护log,即保护了操作记录。文件系统能知道掉电前的所有操作还有最近的snapshot。另外,NVRAM记录的log是很精 简的,它用很少的空间大小记录了几千几万个操作。就不用再去做文件系统一致性检查了,只用很短的时间便可恢复文件系统。但有一个问题,RAM里的数据是无 法保护的啊!到现在我也不知道NetApp对RAM是怎么处理的。如果它对RAM里的数据没有log起来,那它掉电情况下,数据就永远地丢了。可能 NetApp只是想节省一致性检查的时间,而对数据的保护不太在乎吧?

