Hadoop2.6.0集群搭建
一、Hadoop简述
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
在该实验中,我选择的是在CentOS5.8上安装hadoop2.6.0版本。
二、安装CentOS5.8
1. 在VirtualBox中选择新建虚拟机






2. 选择分区:
boot : 100M
swap : 选择内存的1.5倍
/ : 分配剩余的存储
3. 安装完系统之后进行命令:set up
setup --->选择 service system
只留4项服务:
crond
network
ssh
syslog
三、Hadoop搭建步骤
因为我的电脑内存比较小,没能同时启动很多台虚拟系统,因此在该实验中,我只安装三台虚拟机器来完成hadoop的搭建。
1. 环境准备
集群中一共安装三台机器:
master : master/192.168.10.1
slave1 : slave01/192.168.10.2
slave2 : slave02/192.168.10.3
刚开始就只需要新建一台虚拟机器master就可以,之后配置完一系列的操作之后再复制两台服务器分别重命名为slave01、slave02
2. 修改主机名
因为不同的虚拟机版本会导致主机名的配置文件位置不一样,我这里用的是CentOS5.8,所以该配置文件在/etc/sysconfig/network.
在该配置文件中,将hostname的值设置master。修改之后重启系统。
NETWORKING=yes
HOSTNAME=master
3. 修改ip
i. 修改虚拟机的网络选项为:仅主机host-only适配器
ii. 修改windows下虚拟网卡选项[VirtualBox Host-only Network]
将IPV4的IP地址值改为 192.168.10.253
iii. vi /etc/sysconfig/network-scripts/ifcfg-eth0 将修改值如下:
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.10.1
NETMASK=255.255.255.0
GATEWAY=192.168.10.253
iv. 将修改立即生效:
service network restart
4. 配置hosts文件
vi /etc/hosts
192.168.10.1 master
192.168.10.2 slave01
192.168.10.3 slave02
5. 安装jdk
i. 在网上下载jdk安装包之后放到想放的位置,安装完之后修改软连接。我将其安装在/usr/local/下。
ii. 解压安装jdk,并创建软连接:
tar -zxvf jdk-8u65-linux-x64.tar.gz /usr/local
ln -s /usr/local/jdk1.6.0_45 /usr/local/jdk
iii. 修改环境变量
touch /etc/profile.d/java.sh
vi /etc/profile.d/java.sh
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
iv. 立即生效
source /etc/profile
在命令行输入java -version
---显示如下便表示安装完毕:
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
6. 安装hadoop
i. 先关闭防火墙
0.1#service iptables stop
0.2#chkconfig iptables off
0.3#iptables -F
0.4#/etc/init.d/iptables save
0.5#vi /etc/selinux/config
SELINUX=disabled
ii. 创建使用的用户帐户
/usr/sbin/groupadd hadoop
/usr/sbin/useradd hadoop -g Hadoop
设置密码:
passwd Hadoop
iii. 创建hadoop工作目录/数据目录
mkdir -p /application/hadoop
mkdir -p /data/hadoop
mkdir -p /data/hadoop/hdfs/name
mkdir -p /data/hadoop/hdfs/data
mkdir -p /data/hadoop/hdfs/tmp
修改目录所属组及所属用户:
chown -R hadoop:hadoop /data/hadoop
chown -R hadoop:hadoop /application/hadoop
iv. 将下载的hadoop软件上传到hadoop账号的路径下,安装hadoop
cd /home/hadoop
cp hadoop-2.6.0-64.tar.gz /application/hadoop/
cd /application/hadoop
tar -zxvf hadoop-2.6.0-64.tar.gz
ln -s hadoop-2.6.0 hadoop
v. 配置环境变量
vi /etc/profile.d/java.sh
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/application/hadoop/hadoop
export HADOOP_PREFIX=/application/hadoop/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
立即生效:
source /etc/profile
打印看看:
echo $JAVA_HOME
vi. 这一步使用hadoop账号登录进行设置,配置ssh无密码登录。
$ cd /home/hadoop
$ mkdir .ssh
$ chmod 755 .ssh
$ cd .ssh
$ ssh-keygen -t rsa -P ''
//询问保存路径时直接[按回车]采用默认路径
$ cat id_rsa.pub >> authorized_keys
$ chmod 600 authorized_keys
7. 修改hadoop的安装目录中/application/hadoop/Hadoop/etc/配置文件
i. 参考自网上的修改配置文件的方式,一共需要改7个配置文件,hadoop-env.sh中只需要修改JAVA_HOME的值,也就是jdk的安装路径。
ii. 配置slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xm文件,这些文件,参考自http://blog.csdn.net/stark_summer/article/details/42424279博客中的配置。
7.1 配置 hadoop-env.sh文件-->修改JAVA_HOME
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk
7.2 配置 yarn-env.sh 文件-->>修改JAVA_HOME
# some Java parameters
export JAVA_HOME=/usr/local/jdk
7.3 配置slaves文件-->>增加slave节点 (可能有一个默认值localhost,将其改为主机master)
master
slave01
slave02
7.4 配置 core-site.xml文件-->>增加hadoop核心配置(hdfs文件端口是9000、file:/data/hadoop/hdfs/tmp)
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/data/hadoop/hdfs/tmp</value> <description>Abasefor other temporary directories.</description> </property> <property> <name>hadoop.proxyuser.spark.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.spark.groups</name> <value>*</value> </property> </configuration>
7.5 配置hdfs-site.xml 文件-->>增加hdfs配置信息(namenode、datanode端口和目录位置)
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/data/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/data/hadoop/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
7.6 配置 mapred-site.xml 文件-->>增加mapreduce配置(使用yarn框架、jobhistory使用地址以及web地址)
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
7.7 配置yarn-site.xml文件-->>增加yarn功能
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> </configuration>
iii. 配置完之后先不用格式化。待复制完另两台服务器之后再一起分别格式化。
8. 完全复制已配置好的master服务器为slave01、slave02
复制完slave01和slave02之后,分别启动这两台服务器,并参考前文所说方式进行以下操作:
i. 修改主机名(步骤2)
ii. 修改ip(步骤3)
iii. 重启reboot
9. 分别在master、slave01、slave02上对hadoop的配置文件使用以下命令进行格式化。
hadoop namenode -format
10. 自此,hadoop集群搭建完毕。
11. 启动hadoop集群:
/application/hadoop/hadoop/sbin/start-dfs.sh
/application/hadoop/hadoop/sbin/start-yarn.sh
之后再命令行输入jps,显示如下:

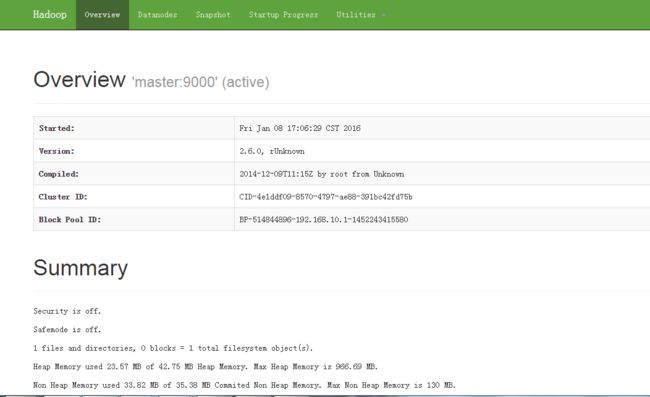
在浏览器中输入网址:
http://192.168.10.1:50070
显示如下:

输入网址:192.168.10.1:8088
显示如下

四、运行实例
在集群使用该软件自带的实例进行测试。
vi words
java
c++
hello
hello
python
java
java
java
c
c
$ hadoop fs -mkdir /data
$ hadoop fs -put words /data
$ hadoop jar /application/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /data /output
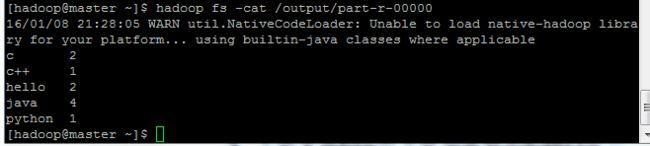
$ hadoop fs -cat /output/part-r-00000
结果如下:

五、总结:
在hadoop集群的安装中,出现了各种各样的问题。各种的细节如果不仔细就会漏了去操作,比如hosts文件,以及ip的配置文件、环境变量的配置等,都很容易漏掉去配置或者配置出错。还有一个就是,在搭建hadoop的时候要将防火墙永久的关闭,如果只是在本次开机使用中关闭,很有可能在下次开机的时候防火墙又会开启了。
Hadoop安装路径下的/etc下的配置文件,要很仔细的配置,按照网上的教程,看懂是做什么的时候再弄,不要一味的跟着照搬,否则很容易出错。