Java序列化方案概述
1、引言
目前移动客户端应用程序上,需要将用户内容持久化到设备上,一般任何feed流应用,如微博、推特、新闻客户端等都需要将内容做持久化操作,以便在内存回收后,再次进入程序能迅速恢复之前的内容。另外如一些视频、音乐、购物等软件,凡是收藏的视频、歌曲、商品以及个人主页等,也应将这些用户私有的内容做序列化,以便无网进入时也能看到相关内容,并正常使用软件。
陆陆续续使用和测试过一些Java序列化方案,这篇主要从Android客户端应用程序的角度,并以速度、序列化文件大小、实践简易性为主要考虑指标介绍并对比以下序列化方案。
2、JVM-Serializsers
(1)JVM-Serializsers使用介绍
首先介绍一下JVM-Serializsers,是一个很不错的测试序列化的工具,可以用它来评测各种流行的java序列化反序列化工具,在其测试模型上构建新的序列化使用上也很方便。本文结合JVM-Serializsers测试模型,并在其测试模型下新增测试了fast-serialization的测试。本文重点介绍Java原生序列化、Kryo、fast-serialiation、fastjson、protocol-buffers等几种典型的序列化方案。
JVM-Serializsers下载源码后,根据readme所示:
Requirements:
- GNU Make 3.81+
- JDK 1.5+
To compile:
make
To run:
./run -help
具体步骤:
1.切到tcp源码目录下
![]()
2.编译源码:

3.运行测试案案例:

./run -chart -include=kryo,fst-serialization,java-built-in,protobuf,hessian,json/google-gson/databind,xml/xstream+c,bson/mongodb,bson/jackson/databind,json/fastjson/databind,json/jackson/databind,thrift,avro-generic data/media.1.cks
include参数代表要进行测试的序列化工具,当然前提是在jvm-serialization中的测试模型下已经构建完相应工具的测试用例。更多参数可通过./run -help看说明,如果带上-chart参数,还会生成序列化性能数据的图形对比。
4.运行结果:
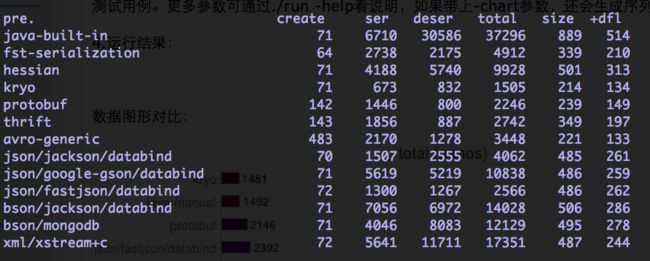
表中参数介绍:
Total Time (“total”):创建一个对象,将其序列化成一个字节数组,然后再反序列化成一个对象。
Serialization Time (“ser”):创建一个对象,将其序列化成一个字节数组。
Deserialization Time (“deser+deep”):相比于序列化,反序列化更耗时。为了更公平的比较,jvm-serializers在反序列化测试时访问了反序列化得到的对象的所有字段(也就是deep的含义),因为部分工具反序列化时“偷懒”而没有做足工作。
Serialized Size (“size”):序列化数据的大小,这个大小会依赖于使用的数据。
Serialization Compressed Size (“size+dfl”):使用java内置的DEFLATE(zlib)压缩的序列化数据的大小。
Object Creation Time (“create”):对象创建耗时很短(平均100纳秒)所以通常的比较没什么意义。不过,不同工具创建的对象在表现上会有不同。有的工具只是创建普通的java类,你可以直接访问其字段,而有的使用get/set方法,有的使用builder模式。
该工具还将这些数据通过google chart服务生成数据图形对比图:
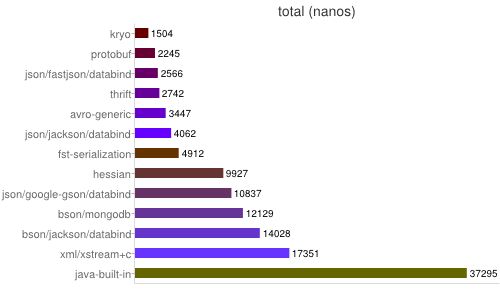
图2-1
5.测试环境
os:os x-10.9
jdk:java version "1.7.0_51"
mem:16G
cpu: 2.3 GHz Intel Core i7
更多在Android Runtime的测试见下文。
以上,已经可以利用强大的JVM-Serializsers工具来分析跟构建自己想测试的序列化工具了。
(2)Java序列化工具技术原理比较
Binary Formats & language-specific ones
JavaBuiltIn(java原生)、JavaManual(根据成员变量类型,手工写)、FstSerliazation、Kryo
Binary formats-generic language-unspecific ones
Protobuf、Thrift、 AvroGeneric、Hessian
JSON Format
Jackson、Gson、FastJSON
JSON-like:
CKS (textual JSON-like format)、BSON(JSON-like format with extended datatypes)
JacksonBson、MongoDB
XML-based formats
XmlXStream
java的序列化工具大致就可以分为以上几类,简单概括就分为二进制binary和文本格式(json、xml)两大类。
从图2-1中可以较为明显的看出,在速度的对比上一般有如下规律:
binary > textual
language-specific > language-unspecific
而textual中,由json相比xml冗余度更低因此速度上更胜一筹,而json又bson这类textual serialization技术上更成熟,框架的选择上更丰富和优秀。下面重点介绍下Kryo、fast-serialiation、fastjson、protocol-buffer
3、典型Java序列化工具分析
(1)Java原生序列化工具
Java本身提供的序列化工具基本上能胜任大多数场景下的序列化任务,关于其序列化机制,这篇文章很细致的解释了,值得一读。Java自带的序列化工具在序列化过程中需要不仅需要将对象的完整的class name记录下来,还需要把该类的定义也都记录下,包括所有其他引用的类,这会是一笔很大的开销,尤其是仅仅序列化单个对象的时候。正因为java序列化机制会把所有meta-data记录下来,因此当修改了类的所在的包名后,反序列化则会报错。Java自带序列化工具的性能问题总结如下:
一个single object的序列化会递归地,连同所有成员变量(instsnce variables)一起序列化了,这种默认机制很容易造成不必要的序列化开销。
序列化和反序列化过程需要上面的这种机制去递归并用反射机制去寻找所有成员变量的信息,另外如果没定义自己serialVersionUID的话,那么对象及其他变量都必须自己产生一个。上述过程开销很大。
使用默认序列化机制,所有序列化类定义完整信息都会被记录下来,包括所有包名、父类信息、以及成员变量
(2)优化过的Java序列化工具
kryo
kryo根据上述Java原生序列化机制的一些问题,对了很多优化工作,而且提供了很多serializer,甚至封装了Unsafe类型的序列化方式,更多关于Unsafe类型的序列化方式,请参考这里,需要注意的是,jdk1.7以后,默认关闭unsafe的类(sun.misc.Unsafe)包。更多kryo介绍参考kryo的wiki,这里贴一下kryo的典型用法。其中CompatibeFieldSerializer就是默认提供的一系列serializer的一种,顾名思义就是一种成员变量上下兼容的序列化工具,支持该类对成员变量的增删。另外kryo更新比较活跃,问题修复很快。
private static Kryo myKryo = new Kryo();
static {
myKryo.register(MusicInfo.class, new CompatibleFieldSerializer<MusicInfo>(myKryo, Media.class), 50);
}
public static void saveObjectByKryo(Object o, String fileName) {
Output output = null;
try {
output = new Output(new FileOutputStream(fileName), 8 * 1024);
myKryo.writeObject(output, o);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (output != null) {
output.close();
}
}
}
public static Object readObjectByKryo(String filename, Class<?> clazz) {
Input input = null;
try {
input = new Input(new FileInputStream(new File(filename)));
return myKryo.readObject(input, clazz);
} catch (Throwable t) {
t.printStackTrace();
} finally {
if (input != null) {
input.close();
}
}
return null;
}
fast-serialization
fst-serialozation相对来说是一个很新的序列化工具,虽然从2-1的评测上来看,速度于kryo有一些差距,但根据本人在生产环境上的场景上测试,效果几乎于kryo一致,都能瞬间反序列化出内容并渲染,该序列化的原理描述:
Fast Serialization reimplements Java Serialization with focus on speed, size and compatibility. This allows the use of FST with minimal code change.
FSTStructs implements a struct emulation to avoid de-/encoding completely. Use case is high performance message oriented software. Other applications are data exchange with other languages, reduction of FullGC by 'flattening' complex Objects, fast offheap, Control of data locality (CPU cache friendly) for high performance computational tasks, allocation free java programs.
Details: StructsIntroduction
这里贴一下fast-serialization的使用方法,如果原来系统使用的Java原生的序列化工具,替换成fast-serialization非常简单:只要把Java的ObjectOutputStream与ObjectInputStream替换成FSTObjectOutput和FSTObjectInput就行了:
public static boolean saveObjectByJava(Object o, String filename) { FSTObjectOutput oos = null; // ObjectOutputStream oos = null; try { oos = new FSTObjectOutput(new FileOutputStream(filename)); oos.writeObject(o); oos.flush(); return true; } catch (IOException e) { e.printStackTrace(); } finally { if (oos != null) { try { oos.close(); } catch (IOException e) { e.printStackTrace(); } } } return false; } public static Object readObjectByJava(String filename) { // FSTObjectInput ois = null; ObjectInputStream ois = null; try { ois = new ObjectInputStream(new FileInputStream(filename)); return ois.readObject(); } catch (Throwable t) { t.printStackTrace(); } finally { if (ois != null) { try { ois.close(); } catch (IOException e) { e.printStackTrace(); } } } return null; }
(3)JSON
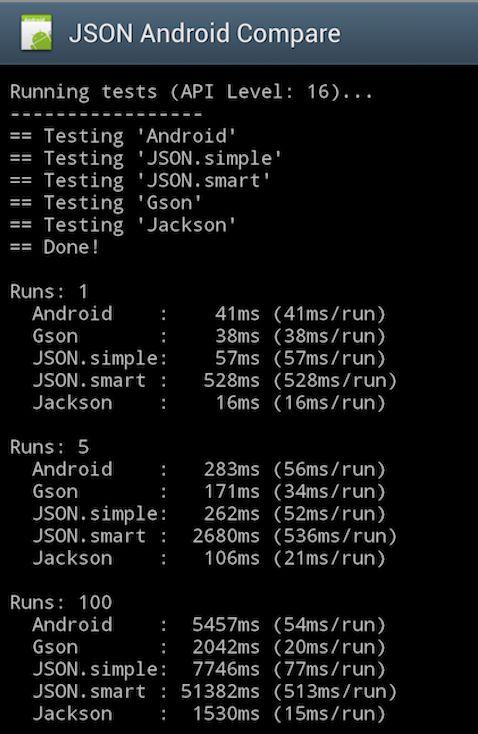
从上一节的多种序列化工作的表现来看,比较优秀的JSON解析工具的表现还是比较好的,有些json解析工具甚至速度超过了一些二进制的序列化方式。Android环境下也有评测json解析性能的demo,图3-1,可以看出jackson在速度上还是比较有优势的,但与Android自带的json包,也没有数量级以上的优势,而jackson的jar包大小达1mb多,因此对于普通的android应用来说是比较奢侈的。
(4)Protocol-Buffer
Protocol buffers是一个用来序列化结构化数据的技术,支持多种语言诸如C++、Java以及Python语言,可以使用该技术来持久化数据或者序列化成网络传输的数据。相比较一些其他的XML技术而言,该技术的一个明显特点就是更加节省空间(以二进制流存储)、速度更快以及更加灵活。 通常,编写一个protocol buffers应用需要经历如下三步:
1、定义消息格式文件,最好以proto作为后缀名
2、使用Google提供的protocol buffers编译器来生成代码文件,一般为.h和.cc文件,主要是对消息格式以特定的语言方式描述
3、使用protocol buffers库提供的API来编写应用程序
具体方法可参考google Protobuf 提供的详细的developer guide
总结
就已有原先使用Java原生序列化方案的系统来说,kryo于fst-serializer是良好的java原生序列化方案替代者,不仅体现再编程简单,而且速度与性能上会有大幅提升,尤其是fst-serializer ,只需替代output/inputstream 即可,性能的提升上也很可观,目前该工具刚出来,稳定性还需要多测测。
如果程序本身就用json格式序列化,则可以考虑引入一个性能优异的json解析库,一般再服务端jackson是广受欢迎的解析库,但是其1.1mb的jar包大小对一般的Android应用有点奢侈,而fastjson在Android上的表现似乎没有再JDK上那么好,不过也比大多数解析库快了。另外用textual格式序列化对象,在Android客户端上还要考虑一些安全问题。
protobuffer更多的是一种取代xml的夸语言的消息交换格式,尽快速度很快,但是编程上需要定义消息格式,对成员变量多、业务复杂的javabean来说代价是较为复杂的,对稳定的已有系统来说总体代价较高。
下表是几种方案的各项指标的一个对比
| 序列化工具 | 序列化速度 | 序列化文件大小 | 编程模型复杂度 | 社区活跃度 | jar包大小 |
| kryo |
极快 | 小 | 简单 | 高 | 132kb |
| fst-serializer | 快 | 小 | 非常简单 | 高 | 246kb |
| protobuffer | 快 | 较大 | 较复杂 | 稳定 | 329kb |
| fastjson | 较快 | 较大 | 简单 | 一般 | 338kb |
| jackson | 一般 | 较大 | 简单 | 稳定 | 1.1mb |
| gson | 较慢 | 较大 | 简单 | 稳定 | 189kb |
4、参考博客:
Java序列化机制介绍及简单优化方法: http://www.javacodegeeks.com/2010/07/java-best-practices-high-performance.html
Java序列化“最佳”实践: http://www.javacodegeeks.com/2010/07/java-best-practices-high-performance.html
提升Java序列化的几种方法: http://www.javacodegeeks.com/2013/09/speed-up-with-fast-java-and-file-serialization.html
详细的Java序列化过程: http://blog.csdn.net/zhaozheng7758/article/details/7820018
Unsafe类型的Java序列化方法:http://www.javacodegeeks.com/2012/07/native-cc-like-performance-for-java.html
protobuf介绍1:http://www.ibm.com/developerworks/cn/linux/l-cn-gpb/
protobuf介绍2:http://www.cnblogs.com/royenhome/archive/2010/10/29/1864860.html