原文:http://blog.csdn.net/cywosp/article/details/8767327
一、UNIX写盘操作模型。
1. 传统的UNIX实现在内核中设有缓冲区高速缓存或页面高速缓存,大多数磁盘I/O都通过缓冲进行。当将数据写入文件时,内核通常先将该数据复制到其中一个缓冲区中,如果该缓冲区尚未写满,则并不将其排入输出队列,而是等待其写满或者当内核需要重用该缓冲区以便存放其他磁盘块数据时,再将该缓冲排入输出队列,然后待其到达队首时,才进行实际的I/O操作。这种输出方式被称为延迟写(delayed write)(Bach [1986]第3章详细讨论了缓冲区高速缓存)。
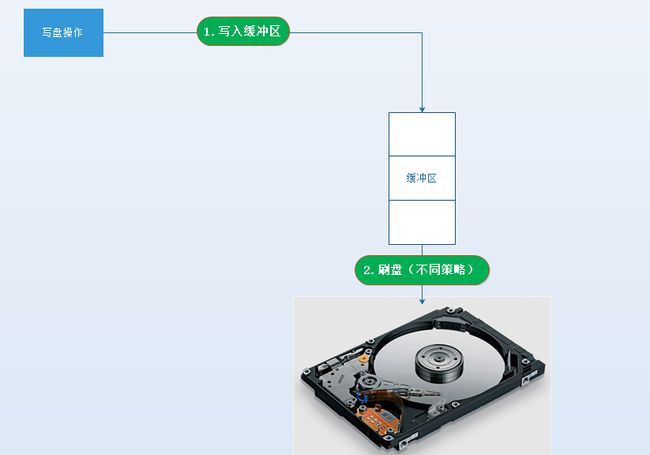
2. 延迟写减少了磁盘读写次数,但是却降低了文件内容的更新速度,使得欲写到文件中的数据在一段时间内并没有写到磁盘上。当系统发生故障时,这种延迟可能造成文件更新内容的丢失。为了保证磁盘上实际文件系统与缓冲区高速缓存中内容的一致性,UNIX系统提供了sync、fsync和fdatasync三个函数。
- sync函数只是将所有修改过的块缓冲区排入写队列,然后就返回,它并不等待实际写磁盘操作结束, 通常称为update的系统守护进程会周期性地(一般每隔30秒)调用sync函数。这就保证了定期冲洗内核的块缓冲区。命令sync(1)也调用sync函数。
- fsync函数只对由文件描述符filedes指定的单一文件起作用,并且等待写磁盘操作结束,然后返回。fsync可用于数据库这样的应用程序,这种应用程序需要确保将修改过的块立即写到磁盘上。
- fdatasync函数类似于fsync,但它只影响文件的数据部分。而除数据外,fsync还会同步更新文件的属性。
二、sync、fsync,fdatasync详细分析
对于提供事务支持的数据库,在事务提交时,都要确保事务日志(包含该事务所有的修改操作以及一个提交记录)完全写到硬盘上,才认定事务提交成功并返回给应用层。
一个简单的问题:在*nix操作系统上,怎样保证对文件的更新内容成功持久化到硬盘?
1. write不够,需要fsync
#include <unistd.h> 2 int fsync(int fd);
1 #incude <sys/mman.h> 2 int msync(void *addr, size_t length, int flags)
msync需要指定同步的地址区间,如此细粒度的控制似乎比fsync更加高效(因为应用程序通常知道自己的脏页位置),但实际上(Linux)kernel中有着十分高效的数据结构,能够很快地找出文件的脏页,使得fsync只会同步文件的修改内容。
2. fsync的性能问题,与fdatasync
"Unfortunately fsync() will always initialize two write operations : one for the newly written data and another one in order to update the modification time stored in the inode. If the modification time is not a part of the transaction concept fdatasync() can be used to avoid unnecessary inode disk write operations."
多余的一次IO操作,有多么昂贵呢?根据Wikipedia的数据,当前硬盘驱动的平均寻道时间(Average seek time)大约是3~15ms,7200RPM硬盘的平均旋转延迟(Average rotational latency)大约为4ms,因此一次IO操作的耗时大约为10ms左右。这个数字意味着什么?下文还会提到。
Posix同样定义了fdatasync,放宽了同步的语义以提高性能:
1 #include <unistd.h> 2 int fdatasync(int fd);
"fdatasync does not flush modified metadata unless that metadata is needed in order to allow a subsequent data retrieval to be corretly handled."
3. 使用fdatasync优化日志同步
2.每次log文件创建时,先写文件的最后1个page,将log文件扩展为10MB大小
3.向log文件中追加记录时,由于文件的尺寸不发生变化,使用fdatasync可以大大优化写log的效率
4.如果一个log文件写满了,则新建一个log文件,也只有一次同步metadata的开销
接下来谈谈flush dirty page,也就是前面说的同步写(没写完的话阻塞后面,直到写完才返回)。为什么是刷脏页?脏页表示缓存中的页(一般也就是内存中)也物理设备上的页处于不一致,不一致是由于在内存中被修改。所以为了使内存中的修改持久化到物理磁盘上我们需要将其从内存中flush到物理磁盘上。根据我的理解,一般来说缓存分成这几种:1>应用程序自己带了缓存,比如InnoDB的buffer pool;2>os层面上的缓存 ;3>磁盘设备自己的缓存,比如raid卡一般都管理着自己的缓存;4>磁盘本身或许会有一点点缓存(这个不确定,自己猜想的,这个即使有估计也是极小的)。好了,那么大部分的时候我们说的flush dirty page都是指从应用程序的缓存->os的缓存->物理设备,如果物理设备没有缓存的话,此时也就相当于持久化成功,但是像磁盘做了raid,raid卡有缓存的话,实际上还没真正持久化成功,因为此时还只到了raid卡的缓存,没到物理设备,但是由于raid卡一般都带有备用电池,所以即使此时断电也不会造成数据丢失。
刚才说了很多时候应用自己也有缓存机制,那么你是否想过此时与os的缓存有重复呢?答案是:会的。刚才说了我是通过研究MySQL的一个参数innodb_flush_method注意这些的,innodb_flush_method表示flush策略,MySQL提供了fdatasync/O_DSYNC/O_DIRECT这三个选项,默认是fdatasync(详情可参看博文)我这里主要说明为什么会提供选项:O_DIRECT。这个选项告诉os,InnoDB在读写数据的时候都不经过os的缓存,因为刚才说过InnoDB会维护自己的缓存buffer pool,如果还使用os的缓存那么两者就会有一定的重复。在前面参考的文章里面说O_DIRECT对大量随即读写有效率提升,顺序读写则会下降。所以根据自己的需求来定,不过如果你的MySQL用在是OLTP上,基本上选择O_DIRECT没错。
三、dirty page解释:
由于页高速缓存的缓存作用,写操作实际上会被延迟,当页高速缓存中的数据比后台存储的数据更新时,该数据被称为脏数据。以下情况下脏页被写回磁盘:
1)当空闲内存低于一个特定的阈值时
2)当脏页在内存中驻留时间超过一个特定的阈值时
写回操作是由一组可并行执行的内核线程完成,这类线程叫做pdflush线程。