索引是有效使用数据库的基础,但你的数据量很小的时候,或许通过扫描整表来存取数据的性能还能接受,但当数据量极大时,当访问量极大时,就一定需要通过索引的辅助才能有效地存取数据。一般索引建立的好坏是性能好坏的成功关键。
1.InnoDb数据与索引存储细节
使用InnoDb作为数据引擎的Mysql和有聚集索引的SqlServer的数据存储结构有点类似,虽然在物理层面,他们都存储在Page上,但在逻辑上面,我们可以把数据分为三块:数据区域,索引区域,主键区域,他们通过主键的值作为关联,配合工作。默认配置下,一个Page的大小为16K。
一个表数据空间中的索引数据区域中有很多索引,每一个索引都是一颗B+Tree,在索引的B+Tree中索引的值作为B+Tree的节点的Key,数据主键作为节点的Value。
在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点数据域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主键索引。这种索引也叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
表数据都以Row的形式放在一个一个大小为16K的Page中,在每个数据Page中有都页头信息和一行一行的数据。其中页头信息中主要放置的是这一页数据中的所有主键值和其对应的OFFSET,便于通过主键能迅速找到其对应的数据位置。

2.索引优化检索的原理
索引是数据库的灵魂,如果没有索引,数据库也就是一堆文本文件,存在的意义并不大。索引能让数据库成几何倍数地提高检索效率。使用Innodb作为数据引擎的Mysql数据库的索引分为聚集索引(也就是主键)和普通索引。上节我们已经讲解了这两种索引的存储结构,现在我们仔细讲解下索引是如何工作的。
聚集索引和普通索引都有可能由多个字段组成,我们又称这种索引为复合索引,1.2.3将为大家解析这种索引的性能情况.
2.1聚集索引
从上节我们知晓,Innodb的所有数据是按照聚集索引排序的,聚集索引这种存储方式使得按主键的搜索十分高效,如果我们SQL语句的选择条件中有聚集索引,数据库会优先使用聚集索引来进行检索工作。
数据库引擎根据条件中的主键的值,迅速在B+Tree中找到主键对应的叶节点,然后把叶节点所在的Page数据库读取到内存,返回给用户,如上图绿色线条的流向。下面我们来运行一条SQL,从数据库的执行情况分析一下:
select * from UP_User where userId = 10000094;
......
# Query_time: 0.000399 Lock_time: 0.000101 Rows_sent: 1 Rows_examined: 1 Rows_affected: 0
# Bytes_sent: 803 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# InnoDB_trx_id: 1D4D
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# Filesort: No Filesort_on_disk: No Merge_passes: 0
# InnoDB_IO_r_ops: 0 InnoDB_IO_r_bytes: 0 InnoDB_IO_r_wait: 0.000000
# InnoDB_rec_lock_wait: 0.000000 InnoDB_queue_wait: 0.000000
# InnoDB_pages_distinct: 2
SET timestamp=1451104535;
select * from UP_User where userId = 10000094;
我们可以看到,数据库读从磁盘取了两个Page就把809Bytes的数据提取出来返回给客户端。
下面我们试一下,如果试一下选取条件没有包含主键和索引的情况:
select * from `UP_User` where bigPortrait = '5F29E883BFA8903B';
# Query_time: 0.002869 Lock_time: 0.000094 Rows_sent: 1 Rows_examined: 1816 Rows_affected: 0
# Bytes_sent: 792 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: Yes Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 25
可以看到如果使用主键作为检索条件,检索时间花了0.3ms,只读取了两个Page,而不使用主键作为检索条件,检索时间花了2.8ms,读取了25个Page,全局扫描才把这条记录给找出来。这还是一个只有1000多行的表,如果更大的数据量,对比更加强烈。
对于这两个Page,一个是主键B+Tree的数据,一个是10000094这条数据所在的数据页。
2.2普通索引
我们用普通索引作为检索条件来搜索数据需要检索两遍索引:首先检索普通索引获得主键,然后用主键到主索引中检索获得记录。如上图红色线条的流向。
下面我用一个例子来看看数据库的表现:
# Query_time: 0.000400 Lock_time: 0.000101 Rows_sent: 1 Rows_examined: 1 Rows_affected: 0
# Bytes_sent: 803 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 4
我们可以看到数据库用了0.4ms来检索这条数据,读取了4个page,比用主键作为检索条件多用了0.1ms,多读取了两个Page,而这两个Page就是userName这个普通索引的B+Tree所在的数据页。
2.3复合索引
聚集索引和普通索引都有可能由多个字段组成,多个字段组成的索引的叶节点的Key由多个字段的值按照顺序拼接而成。这种索引的存储结构是这样的,首先按照第一个字段建立一棵B+Tree,叶节点的Key是第一个字段的值,叶节点的value又是一棵小的B+Tree,逐级递减。对于这样的索引,用排在第一的字段作为检索条件才有效提高检索效率。排在后面的字段只能在排在他前面的字段都在检索条件中的时候才能起辅助效果。下面我们用例子来说明这种情况。
我们在UP_User表上建立一个用来测试的复合索引,建立在 (`nickname`,`regTime`)两个字段上,下面我们测试下检索性能:
# Query_time: 0.000443 Lock_time: 0.000101 Rows_sent: 1 Rows_examined: 1 Rows_affected: 0
# Bytes_sent: 778 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 4
我们看到索引起作用了,和普通索引的效果一样都用了0.43ms,读取了四个Page就完成了任务。
# Query_time: 0.007076 Lock_time: 0.000286 Rows_sent: 1 Rows_examined: 1816 Rows_affected: 0
# Bytes_sent: 803 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: Yes Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 26
从这次选择的执行情况来看,虽然regTime在刚才建立的复合索引中,还是做了全局扫描。因为这个复合索引排在regTime字段前面的nickname字段没有出现在选择条件中,所以这个索引我们没用用到。
那么我们什么情况下会用到复合索引呢。我一般在两种情况下会用到:
- 需要复合索引来排重的时候。
- 用索引的第一个字段选取出来的结果不够精准,需要第二个字段做进一步的性能优化。
我基本上没有建立过三个以上的字段做复合索引,如果出现这种情况,我觉的你的表设计可能出现了大而全的问题,需要在表设计层面调优,而不是通过增加复杂的索引调优。所有复杂的东西都是大概率有问题的。
3.批量选择的效率
我们业务经常这样的诉求,选择某个用户发送的所有消息,这个帖子所有回复内容,所有昨天注册的用户的UserId等。这样的诉求需要从数据库中取出一批数据,而不是一条数据,数据库对这种请求的处理逻辑稍微复杂一点,下面我们来分析一下各种情况。
3.1根据主键批量检索数据
我们有一张表PW_Like,专门存储Feed的所有赞(Like),该表使用feedId和userId做联合主键,其中feedId为排在第一位的字段。该表一共有19个Page的数据。下面我们选取feedId为11593所有的赞:
# Query_time: 0.000478 Lock_time: 0.000084 Rows_sent: 58 Rows_examined: 58 Rows_affected: 0
# Bytes_sent: 865 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 2
我们花了0.47ms取出了58条数据,但一共只读取了2个Page的数据,其中一个Page还是这个表的主键。说明这58条数据都存储在同一个Page中。这种情况,对于数据库来说,是效率最高的情况。
3.2根据普通索引批量检索数据
还是刚才那个表,我们除了主键以外,还在userId上建立了索引,因为有时候需要查询某个用户点过的赞。那么我们来看看只通过索引,不通过主键来检索批量数据时候,数据库的效率情况。
# Query_time: 0.002892 Lock_time: 0.000062 Rows_sent: 27 Rows_examined: 27 Rows_affected: 0
# Bytes_sent: 399 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 15
我们可以看到的结果是,虽然我们只取出了27条数据,但是我们读取了15个数据Page,花了2.8毫秒,虽然没有进行全局扫描,但基本上也把一般的数据块读取出来了。因为PW_Like中的数据由于是按照feedId物理排序的,所以这27条数据分别分布在13个Page中(有两个Page是索引和主键),所以数据库需要把这13个Page全部从磁盘中读取出来,哪怕某一个Page(16K)上只有一条数据(15Bytes),也需要把这个数据Page读出来才能取出所有的目标Row。
通过普通索引来检索批量数据,效率明显比通过主键来检索要低得多。因为数据是分散的,所以需要分散地读取数据Page进行拼接才能完成任务。但是索引对主键而言还是非常有必要的补充,比如上面这个例子,当用户量达到100万的时候,检索某一个用户点的所有的赞的成本也只是大概读取15个Page,花2ms左右。
3.2检索一段时间范围内的数据
选取一定范围内的数据是我们经常要遇到的问题。在海量数据的表中检索一定范围内的数据,很容易引起性能问题。我们遇到的最常见的需求有以下几种:
- 选取一段时间内注册的用户信息
这种时候,时间肯定不会是用户表的主键,如果直接用时间作为选择条件来检索,效率会非常差,如何解决这种问题呢?我采取的办法是,把注册时间作为用户表的索引,每次先把需要检索的时间的两端的userId都差出来,然后用这两个userId做选择条件做第三次查询就是我们想要的数据了。这三次检索我们只需要读取大约10个Page就能解决问题。这种方法看起来很麻烦,但是是表的数据量达到亿级的时候的唯一解决方案。 - 选取一段时间内的日志
日志表是我们最常见的表,如何设计好是经常聊到的话题。日志表之所以不好设计是因为大家都希望用时间作为主键,这样检索一段时间内的日志将非常方便。但是用时间作为主键有个非常大的弊端,当日志插入速度很快的时候,就会出现因为主键重复而引起冲突。
对于这种情况,我一般把日志生成时间和一个自增的Id作为日志表的联合主键,把时间作为第一个字段,这样即避免了日志插入过快引起的主键唯一性冲突,又能便捷地根据时间做检索工作,非常方便。下面是这种日志表的检索的例子,大家可以看到性能非常好。还有就是日志表最好是每天一个表,这样能更便利地管理和检索。
select * from log_test where logTime > "2015-12-27 11:53:05" and logTime < "2015-12-27 12:03:05";
# Query_time: 0.001158 Lock_time: 0.000084 Rows_sent: 599 Rows_examined: 599 Rows_affected: 0
# Bytes_sent: 4347 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 3
4.批量选择的效率
我们在批量检索数据的时候,对选择的结果在大多数情况下,都需要数据是排好序的。排序的性能也是日常需要注意到的,下面我们分三种情况来分析下数据库是如何排序的。
对于ORDER BY 主键这种情况,数据库是非常乐于见到的,基本上不会有额外性能的损耗,因为数据本来就是按照主键顺序存储的,取出来直接返回即可。
下面的所有关于排序的例子是在UP_MessageHistory表上做的实验,这个表一共有195个page,35417行数据,主键建立在字段id上,在sendUserId和destUserId上都建立了索引。
首先我们先做一个没有排序的检索:
# Query_time: 0.016135 Lock_time: 0.000084 Rows_sent: 3572 Rows_examined: 3572 Rows_affected: 0
# Bytes_sent: 95600 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 125
然后我们在相同的条件下对id进行排序:
# Query_time: 0.016259 Lock_time: 0.000086 Rows_sent: 3572 Rows_examined: 3572 Rows_affected: 0
# Bytes_sent: 95600 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 125
从上面的数据可以看出,性能和没有加order by差不多,基本没有额外的性能损耗。接下来我们对索引进行排序:
# Query_time: 0.018107 Lock_time: 0.000083 Rows_sent: 3572 Rows_examined: 7144 Rows_affected: 0
# Bytes_sent: 103123 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 125
接下来我们用普通字符串字段做排序再看看:
# Query_time: 0.023611 Lock_time: 0.000085 Rows_sent: 3572 Rows_examined: 7144 Rows_affected: 0
# Bytes_sent: 105214 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 125
然后我们再用普通的数字类型字段排序看看情况:
针对以上的实验结果,我们可以得出以下结论:
- 针对主键做排序操作不会有性能损耗;
- 针对不在选择条件中的索引字段做排序操作,索引不会起优化排序的作用;
- 针对数值类型字段排序会比针对字符串类型字段排序的效率要高很多。
下面我们再研究下用选择条件中的索引字段排序,数据库是否会优化排序算法,我们任然用UP_User表来研究。
# Query_time: 0.001470 Lock_time: 0.000130 Rows_sent: 122 Rows_examined: 122 Rows_affected: 0
# Bytes_sent: 9559 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 17
然后我们用选择条件中的索引字段做排序:
# Query_time: 0.001407 Lock_time: 0.000087 Rows_sent: 122 Rows_examined: 122 Rows_affected: 0
# Bytes_sent: 9559 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No# InnoDB_pages_distinct: 17
然后我们用选择条件中的非索引数值字段做排序:
# Query_time: 0.002017 Lock_time: 0.000104 Rows_sent: 122 Rows_examined: 244 Rows_affected: 0
# Bytes_sent: 9657 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 17
从上面三条查询语句的执行时间来分析,使用索引字段排序和不排序花的时间差不多,比使用普通字段排序花的时间少一些,因此我们可以得出第四条结论:
4.针对在选择条件中的索引字段做排序操作,索引会起优化排序的作用。
5.索引维护
在前面我们可以看到所有的主键和索引都是排好序的,那么排序这件事情就需要销号资源,每次有新的数据插入,或者老的数据的数值发生变更,排序就需要调整,这里面是需要损耗性能的,下面我们分析一下。
自增型字段作为主键时,数据库对主键的维护成本非常低:
- 每次新增加的值都是一个最大的值,追加到最后即可,其他数据不需要挪动;
- 这种数据一般不做修改。
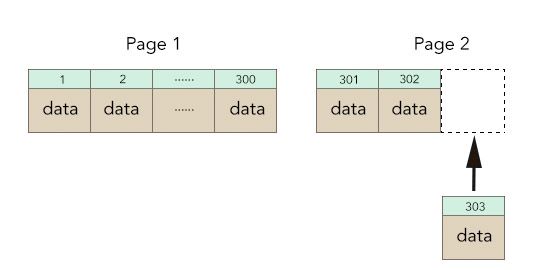
使用业务型字段作为主键时,主键维护成本会比较高。每次生成的新数据都有可能需要挪动其他数据的位置。

因为innodb主键和数据是在放在一块的,每次挪动主键,也需要挪动数据,维护的成本会比较搞,对于需要频繁写入的表,不建议使用业务字段作为主键的。
由于主键是所有索引的叶节点的值,也是数据排序的依据,如果主键的值被修改,那么需要修改所有相关索引,并且需要修改整个主键B+Tree的排序,损耗会非常大。避免频繁更新主键可以避免以上提到的问题。
# Query_time: 0.010916 Lock_time: 0.000201 Rows_sent: 0 Rows_examined: 1 Rows_affected: 1
# Bytes_sent: 59 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# InnoDB_pages_distinct: 11
从上面的数据可以看出来,索然SQL语句只修改了一条数据,却影响了11个Page。
相对于主键而已,索引就轻很多,它的叶节点的值是主键,很轻,维护起来成本比较低。但也不建议为一个表建立过多索引。维护一个索引成本低,维护8个就不一定低了,这种事需要均衡地对待。
6.索引设计原则
索引其实是一把双刃剑,用好了事半功倍,没用好,事倍功半。
主键的字段无特殊情况,一定要使用数值类型的,排序时占用计算资源少,存储时占用空间也少。若主键的字段值很大,则整个数据表的各种索引也会变得没有效率,因为所有的索引的叶节点的值都是主键。
并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段 sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用