本章主要讲解分析Kafka的Producer的业务逻辑,分发逻辑和负载逻辑都在Producer中维护。
一、Kafka的总体结构图
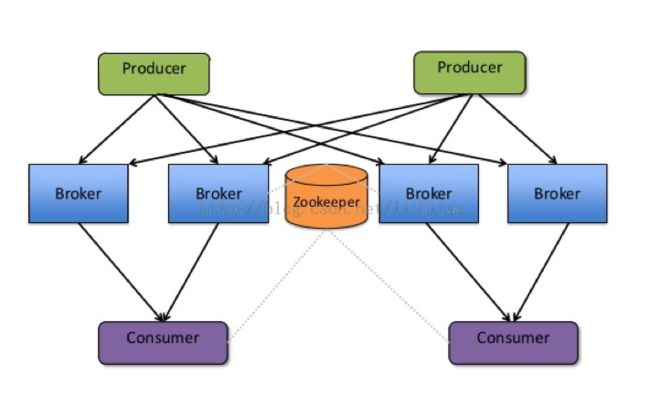
(图片转发)
二、Producer源码分析
class Producer[K,V](val config: ProducerConfig,
private val eventHandler: EventHandler[K,V]) // only for unit testing
extends Logging {
private val hasShutdown = new AtomicBoolean(false)
//异步发送队列
private val queue = new LinkedBlockingQueue[KeyedMessage[K,V]](config.queueBufferingMaxMessages)
private var sync: Boolean = true
//异步处理线程
private var producerSendThread: ProducerSendThread[K,V] = null
private val lock = new Object()
//根据从配置文件中载入的信息封装成ProducerConfig类
//判断发送类型是同步,还是异步,如果是异步则启动一个异步处理线程
config.producerType match {
case "sync" =>
case "async" =>
sync = false
producerSendThread =
new ProducerSendThread[K,V]("ProducerSendThread-" + config.clientId,
queue,
ventHandler,
config.queueBufferingMaxMs,
config.batchNumMessages,
config.clientId)
producerSendThread.start()
}
private val producerTopicStats = ProducerTopicStatsRegistry.getProducerTopicStats(config.clientId)
KafkaMetricsReporter.startReporters(config.props)
AppInfo.registerInfo()
def this(config: ProducerConfig) =
this(config,
new DefaultEventHandler[K,V](config,
Utils.createObject[Partitioner](config.partitionerClass, config.props),
Utils.createObject[Encoder[V]](config.serializerClass, config.props),
Utils.createObject[Encoder[K]](config.keySerializerClass, config.props),
new ProducerPool(config)))
/**
* Sends the data, partitioned by key to the topic using either the
* synchronous or the asynchronous producer
* @param messages the producer data object that encapsulates the topic, key and message data
*/
def send(messages: KeyedMessage[K,V]*) {
lock synchronized {
if (hasShutdown.get)
throw new ProducerClosedException
recordStats(messages)
sync match {
case true => eventHandler.handle(messages)
case false => asyncSend(messages)
}
}
}
private def recordStats(messages: Seq[KeyedMessage[K,V]]) {
for (message <- messages) {
producerTopicStats.getProducerTopicStats(message.topic).messageRate.mark()
producerTopicStats.getProducerAllTopicsStats.messageRate.mark()
}
}
//异步发送流程
//将messages异步放到queue里面,等待异步线程获取
private def asyncSend(messages: Seq[KeyedMessage[K,V]]) {
for (message <- messages) {
val added = config.queueEnqueueTimeoutMs match {
case 0 =>
queue.offer(message)
case _ =>
try {
config.queueEnqueueTimeoutMs < 0 match {
case true =>
queue.put(message)
true
case _ =>
queue.offer(message, config.queueEnqueueTimeoutMs, TimeUnit.MILLISECONDS)
}
}
catch {
case e: InterruptedException =>
false
}
}
if(!added) {
producerTopicStats.getProducerTopicStats(message.topic).droppedMessageRate.mark()
producerTopicStats.getProducerAllTopicsStats.droppedMessageRate.mark()
throw new QueueFullException("Event queue is full of unsent messages, could not send event: " + message.toString)
}else {
trace("Added to send queue an event: " + message.toString)
trace("Remaining queue size: " + queue.remainingCapacity)
}
}
}
/**
* Close API to close the producer pool connections to all Kafka brokers. Also closes
* the zookeeper client connection if one exists
*/
def close() = {
lock synchronized {
val canShutdown = hasShutdown.compareAndSet(false, true)
if(canShutdown) {
info("Shutting down producer")
val startTime = System.nanoTime()
KafkaMetricsGroup.removeAllProducerMetrics(config.clientId)
if (producerSendThread != null)
producerSendThread.shutdown
eventHandler.close
info("Producer shutdown completed in " + (System.nanoTime() - startTime) / 1000000 + " ms")
}
}
}
}
说明:
上面这段代码很多方法我加了中文注释,首先要初始化一系列参数,比如异步消息队列queue,是否是同步sync,异步同步数据线程ProducerSendThread,其实重点就是ProducerSendThread这个类,从队列中取出数据并让kafka.producer.EventHandler将消息发送到broker。这个代码量不多,但是包含了很多内容,通过config.producerType判断是同步发送还是异步发送,每一种发送方式都有相关类支持,下面我们将重点介绍这二种类型。
我们发送消息的类是如下格式:
case class KeyedMessage[K, V](val topic: String, val key: K, val partKey: Any, val message: V)
说明:
当使用三个参数的构造函数时, partKey会等于key。partKey是用来做partition的,但它不会最当成消息的一部分被存储。
1、同步发送
private def dispatchSerializedData(messages: Seq[KeyedMessage[K,Message]]): Seq[KeyedMessage[K, Message]] = {
//分区并且整理方法
val partitionedDataOpt = partitionAndCollate(messages)
partitionedDataOpt match {
case Some(partitionedData) =>
val failedProduceRequests = new ArrayBuffer[KeyedMessage[K,Message]]
try {
for ((brokerid, messagesPerBrokerMap) <- partitionedData) {
if (logger.isTraceEnabled)
messagesPerBrokerMap.foreach(partitionAndEvent =>
trace("Handling event for Topic: %s, Broker: %d, Partitions: %s".format(partitionAndEvent._1, brokerid, partitionAndEvent._2)))
val messageSetPerBroker = groupMessagesToSet(messagesPerBrokerMap)
val failedTopicPartitions = send(brokerid, messageSetPerBroker)
failedTopicPartitions.foreach(topicPartition => {
messagesPerBrokerMap.get(topicPartition) match {
case Some(data) => failedProduceRequests.appendAll(data)
case None => // nothing
}
})
}
} catch {
case t: Throwable => error("Failed to send messages", t)
}
failedProduceRequests
case None => // all produce requests failed
messages
}
}
说明:
这个方法主要说了二个重要信息,一个是partitionAndCollate,这个方法主要获取topic、partition和broker的,这个方法很重要,下面会进行分析。另一个重要的方法是groupMessageToSet是要对所发送数据进行压缩设置,如果没有设置压缩,就所有topic对应的消息集都不压缩。如果设置了压缩,并且没有设置对个别topic启用压缩,就对所有topic都使用压缩;否则就只对设置了压缩的topic压缩。
在这个gruopMessageToSet中,并不有具体的压缩逻辑。而是返回一个ByteBufferMessageSet对象。
在我们了解的partitionAndCollate方法之前先来了解一下如下类结构:
TopicMetadata -->PartitionMetadata
case class PartitionMetadata(partitionId: Int,
val leader: Option[Broker],
replicas: Seq[Broker],
isr: Seq[Broker] = Seq.empty,
errorCode: Short = ErrorMapping.NoError) 也就是说,Topic元数据包括了partition元数据,partition元数据中包括了partitionId,leader(leader partition在哪个broker中,备份partition在哪些broker中,以及isr有哪些等等。
def partitionAndCollate(messages: Seq[KeyedMessage[K,Message]]): Option[Map[Int, collection.mutable.Map[TopicAndPartition, Seq[KeyedMessage[K,Message]]]]] = {
val ret = new HashMap[Int, collection.mutable.Map[TopicAndPartition, Seq[KeyedMessage[K,Message]]]]
try {
for (message <- messages) {
//获取Topic的partition列表
val topicPartitionsList = getPartitionListForTopic(message)
//根据hash算法得到消息应该发往哪个分区(partition)
val partitionIndex = getPartition(message.topic, message.partitionKey, topicPartitionsList)
val brokerPartition = topicPartitionsList(partitionIndex)
// postpone the failure until the send operation, so that requests for other brokers are handled correctly
val leaderBrokerId = brokerPartition.leaderBrokerIdOpt.getOrElse(-1)
var dataPerBroker: HashMap[TopicAndPartition, Seq[KeyedMessage[K,Message]]] = null
ret.get(leaderBrokerId) match {
case Some(element) =>
dataPerBroker = element.asInstanceOf[HashMap[TopicAndPartition, Seq[KeyedMessage[K,Message]]]]
case None =>
dataPerBroker = new HashMap[TopicAndPartition, Seq[KeyedMessage[K,Message]]]
ret.put(leaderBrokerId, dataPerBroker)
}
val topicAndPartition = TopicAndPartition(message.topic, brokerPartition.partitionId)
var dataPerTopicPartition: ArrayBuffer[KeyedMessage[K,Message]] = null
dataPerBroker.get(topicAndPartition) match {
case Some(element) =>
dataPerTopicPartition = element.asInstanceOf[ArrayBuffer[KeyedMessage[K,Message]]]
case None =>
dataPerTopicPartition = new ArrayBuffer[KeyedMessage[K,Message]]
dataPerBroker.put(topicAndPartition, dataPerTopicPartition)
}
dataPerTopicPartition.append(message)
}
Some(ret)
}catch { // Swallow recoverable exceptions and return None so that they can be retried.
case ute: UnknownTopicOrPartitionException => warn("Failed to collate messages by topic,partition due to: " + ute.getMessage); None
case lnae: LeaderNotAvailableException => warn("Failed to collate messages by topic,partition due to: " + lnae.getMessage); None
case oe: Throwable => error("Failed to collate messages by topic, partition due to: " + oe.getMessage); None
}
}
说明:
调用partitionAndCollate根据topics的messages进行分组操作,messages分配给dataPerBroker(多个不同的Broker的Map),根据不同Broker调用不同的SyncProducer.send批量发送消息数据,SyncProducer包装了nio网络操作信息。
partitionAndCollate这个方法的主要作用是:获取所有partitions的leader所在leaderBrokerId(就是在该partiionid的leader分布在哪个broker上),创建一个HashMap>>>,把messages按照brokerId分组组装数据,然后为SyncProducer分别发送消息作准备工作,在确定一个消息应该发给哪个broker之前,要先确定它发给哪个partition,这样才能根据paritionId去找到对应的leader所在的broker。
我们进入getPartitionListForTopic这个方法看一下,这个方法主要是干什么的。
private def getPartitionListForTopic(m: KeyedMessage[K,Message]): Seq[PartitionAndLeader] = {
val topicPartitionsList = brokerPartitionInfo.getBrokerPartitionInfo(m.topic, correlationId.getAndIncrement)
debug("Broker partitions registered for topic: %s are %s"
.format(m.topic, topicPartitionsList.map(p => p.partitionId).mkString(",")))
val totalNumPartitions = topicPartitionsList.length
if(totalNumPartitions == 0)
throw new NoBrokersForPartitionException("Partition key = " + m.key)
topicPartitionsList
} 说明:这个方法看上去没什么,主要是getBrokerPartitionInfo这个方法,其中KeyedMessage这个就是我们要发送的消息,返回值是Seq[PartitionAndLeader]。
