Lucene入门
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
以下模拟一个简单的Lucene入门案例
接下来为Lucene开发步骤:
1、新建一个java工程,导入Lucene所需jar,如下图

目录结构
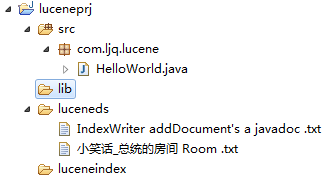
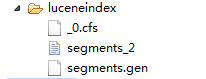
其中:luceneds为数据源存储位置,luceneindex存放索引文件的位置,即索引库。如果索引库已被创建,那么luceneindex目录下会有索引文件,如下图:
代码
package
com.ljq.lucene;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.NumberTools;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.junit.Test;
/**
* 开发lucene步骤:先创建索引,再搜索
*
* @author jiqinlin
*
*/
public class HelloWorld {
// 数据源路径
String dspath = " F:\\android\\luceneprj\\luceneds\\IndexWriter addDocument's a javadoc .txt " ;
// 存放索引文件的位置,即索引库
String indexpath = " F:\\android\\luceneprj\\luceneindex " ;
// 分词器
Analyzer analyzer = new StandardAnalyzer();
/**
* 创建索引
*
* IndexWriter 用来操作(增、删、改)索引库的
*/
@Test
public void createIndex() throws Exception {
File file = new File(dspath);
// Document存放经过组织后的数据源,只有转换为Document对象才可以被索引和搜索到
Document doc = new Document();
// 文件名称
doc.add( new Field( " name " , file.getName(), Store.YES, Index.ANALYZED));
// 检索到的内容
doc.add( new Field( " content " , readFileContent(file), Store.YES, Index.ANALYZED));
// 文件大小
doc.add( new Field( " size " , NumberTools.longToString(file.length()),
Store.YES, Index.NOT_ANALYZED));
// 检索到的文件位置
doc.add( new Field( " path " , file.getAbsolutePath(), Store.YES, Index.NOT_ANALYZED));
// 建立索引
IndexWriter indexWriter = new IndexWriter(indexpath, analyzer, true ,
MaxFieldLength.LIMITED);
indexWriter.addDocument(doc);
indexWriter.close();
}
/**
* 搜索
*
* IndexSearcher 用来在索引库中进行查询
*/
@Test
public void search() throws Exception {
// 请求字段
// String queryString = "document";
String queryString = " adddocument " ;
// 1,把要搜索的文本解析为 Query
String[] fields = { " name " , " content " };
QueryParser queryParser = new MultiFieldQueryParser(fields, analyzer);
Query query = queryParser.parse(queryString);
// 2,进行查询,从索引库中查找
IndexSearcher indexSearcher = new IndexSearcher(indexpath);
Filter filter = null ;
TopDocs topDocs = indexSearcher.search(query, filter, 10000 );
System.out.println( " 总共有【 " + topDocs.totalHits + " 】条匹配结果 " );
// 3,打印结果
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 文档内部编号
int index = scoreDoc.doc;
// 根据编号取出相应的文档
Document doc = indexSearcher.doc(index);
System.out.println( " ------------------------------ " );
System.out.println( " name = " + doc.get( " name " ));
System.out.println( " content = " + doc.get( " content " ));
System.out.println( " size = " + NumberTools.stringToLong(doc.get( " size " )));
System.out.println( " path = " + doc.get( " path " ));
}
}
/**
* 读取文件内容
*/
public static String readFileContent(File file) {
try {
BufferedReader reader = new BufferedReader( new InputStreamReader( new FileInputStream(file)));
StringBuffer content = new StringBuffer();
for (String line = null ; (line = reader.readLine()) != null ;) {
content.append(line).append( " \n " );
}
reader.close();
return content.toString();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.NumberTools;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.junit.Test;
/**
* 开发lucene步骤:先创建索引,再搜索
*
* @author jiqinlin
*
*/
public class HelloWorld {
// 数据源路径
String dspath = " F:\\android\\luceneprj\\luceneds\\IndexWriter addDocument's a javadoc .txt " ;
// 存放索引文件的位置,即索引库
String indexpath = " F:\\android\\luceneprj\\luceneindex " ;
// 分词器
Analyzer analyzer = new StandardAnalyzer();
/**
* 创建索引
*
* IndexWriter 用来操作(增、删、改)索引库的
*/
@Test
public void createIndex() throws Exception {
File file = new File(dspath);
// Document存放经过组织后的数据源,只有转换为Document对象才可以被索引和搜索到
Document doc = new Document();
// 文件名称
doc.add( new Field( " name " , file.getName(), Store.YES, Index.ANALYZED));
// 检索到的内容
doc.add( new Field( " content " , readFileContent(file), Store.YES, Index.ANALYZED));
// 文件大小
doc.add( new Field( " size " , NumberTools.longToString(file.length()),
Store.YES, Index.NOT_ANALYZED));
// 检索到的文件位置
doc.add( new Field( " path " , file.getAbsolutePath(), Store.YES, Index.NOT_ANALYZED));
// 建立索引
IndexWriter indexWriter = new IndexWriter(indexpath, analyzer, true ,
MaxFieldLength.LIMITED);
indexWriter.addDocument(doc);
indexWriter.close();
}
/**
* 搜索
*
* IndexSearcher 用来在索引库中进行查询
*/
@Test
public void search() throws Exception {
// 请求字段
// String queryString = "document";
String queryString = " adddocument " ;
// 1,把要搜索的文本解析为 Query
String[] fields = { " name " , " content " };
QueryParser queryParser = new MultiFieldQueryParser(fields, analyzer);
Query query = queryParser.parse(queryString);
// 2,进行查询,从索引库中查找
IndexSearcher indexSearcher = new IndexSearcher(indexpath);
Filter filter = null ;
TopDocs topDocs = indexSearcher.search(query, filter, 10000 );
System.out.println( " 总共有【 " + topDocs.totalHits + " 】条匹配结果 " );
// 3,打印结果
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 文档内部编号
int index = scoreDoc.doc;
// 根据编号取出相应的文档
Document doc = indexSearcher.doc(index);
System.out.println( " ------------------------------ " );
System.out.println( " name = " + doc.get( " name " ));
System.out.println( " content = " + doc.get( " content " ));
System.out.println( " size = " + NumberTools.stringToLong(doc.get( " size " )));
System.out.println( " path = " + doc.get( " path " ));
}
}
/**
* 读取文件内容
*/
public static String readFileContent(File file) {
try {
BufferedReader reader = new BufferedReader( new InputStreamReader( new FileInputStream(file)));
StringBuffer content = new StringBuffer();
for (String line = null ; (line = reader.readLine()) != null ;) {
content.append(line).append( " \n " );
}
reader.close();
return content.toString();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
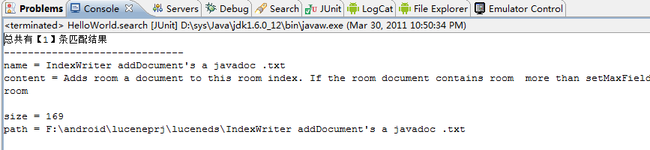
运行结果如下:
分类: Lucene