这是一篇关于介绍jQuery Sizzle选择器的文章,由我和obility共同完成。在文中,我们试图用自己的语言配以适量的代码向读者展现出Sizzle在处理选择符时的流程原理,以及末了以少许文字给你展示出如何借用Sizzle之手实现自定义选择器(也许更标准的叫法叫做过滤符)和它与YUI 选择器的大致比较。
前序
jQuery相比1.2的版本,在内部代码的构造上已经出现了巨大的变化,其之一便是模块的分发.我记得09年在jquery 9月开的一次大会上 john放出的一张ppt上 也指出了当前的jquery下一步目标,不仅仅是除了sizzle选择器的分离,届时core,attribute,css以及manipulation,包括event也都会独立成单独的js文件.(1.4的文件结构,其实已经分成单独的16个模块的组成)
随着jQuery被用来构建web app的场合愈来愈多,它的性能自然受到了大部分开发者的高度关注,它的内部实现机理又是如何,比如选择器的实现。
Sizzle,作为一个独立全新的选择器引擎,出现在jQuery 1.3版本之后,并被John Resig作为一个开源的项目,可以用于其他框架:Mool, Dojo,YUI等。
好了,现在来看为什么Sizzle选择器如此受欢迎,使它能够在常用dom匹配上都快于其他选择器而让这些框架们都垂青于它。
概要
一般选择器的匹配模式(包括jq1.2之前),都是一个顺序的思维方式,在需要递进式匹配时,比如$(‘div span’) 这样的匹配时,执行的操作都是先匹配页面中div然后再匹配它的节点下的span标签,之后返回结果。
Sizzle则采取了相反Right To Left的实现方式,先搜寻页面中所有的span标签,再其后的操作中才去判断它的父节点(包括父节点以上)是否为div,是则压入数组,否则pass,进入下一判断,最后返回该操作序列。
另外,在很多细节上也进行了优化。
浅析源码
在探索 $ 符 和 Sizzle的协同工作原理前,先引用一张图片.
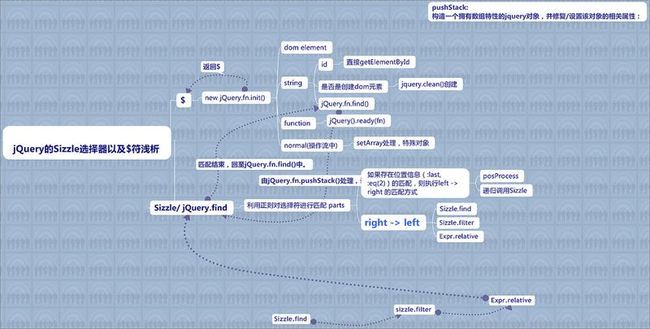
开始吧。($符在这里不作过多的介绍).
当我们给$符传递进一个参数(也可能是多个)时,此时它会根据参数的类型(domElement | string | fn | array)进入不同的流程,在此,重点看 string 类型的处理,因为只有它才可以触发Sizzle。首先调用正则匹配看是否为创建dom节点的操作,然后看是否为简单id匹配,这一步也由正则匹配完成,否则进入jQuery.fn.find()函数,由此进入Sizzle的天地。
当进入Sizzle时,一般情况下会配备三参:所要匹配的选择符,上下文,匹配的结果集。调用正则对传入的selector做一次”预匹配”.
var chunker = /((?:\((?:\([^()]+\)|[^()]+)+\)|\[(?:\[[^[\]]*\]|['"][^'"]*['"]|[^[\]'"]+)+\]|\\.|[^ >+~,(\[\\]+)+|[>+~])(\s*,\s*)?/g,
让我们看一下一个简单选择器的实现过程:比如 div > p。我们要先找出符合条件的div[div],再找出符合条件的p[p],最后在上下文里[div]过滤出符合条件”>”的p[p];抽象一点的说法就是:在已知的上下文里,根据关系找出相应的节点。他们靠关系联系起来。那么对于选择器的操作也就是根据关系来分组。一次次缩小上下文,直到找出符合条件的节点。
回到我们的话题,还是先看看这个令人费解的正则,相信你会有更好的分析方法,但是眼下,我还是一点点的拆分,让它表达的更清晰一点。先按照分组拆,即():
((?:\((?:\([^()]+\)|[^()]+)+\)|\[(?:\[[^\[\]]*\]|['"][^'"]*['"]|[^\[\]'"]+)+\]|\\.|[^ >+~,(\[\\]+)+|[>+~]) (\s*,\s*)? ((?:.|\r|\n)*)
第一行还是有点长,用’|'拆分它:
1. (?:\((?:\([^()]+\) 2.[^()]+)+\) 3. \[(?:\[[^[\]]*\] 4. [^[\]]+)+\]|\\. 5.[^ >+~,(\[]+)+ 6.[>+~]
对于如div > p。会得到数组结果['div','>','p']。
对于更复杂的选择器,如div.classname > p.classname。会得到结果['div.classname','>','p.classname']。
对于具有合并的‘,’,只是递归调用下获取结果再合并而已。过程开始变得简单起来。
对于普通的解析过程,我们遵循着从左到右的顺序即可完成我们的目标。
让我们总结下步骤:
1.先查找页面上所有的div 2.循环所有的div,查找每个div下的p 3.合并结果
Sizzle用了截然相反的步骤:
1.先查找页面上所有的p 2.循环所有的p,查找每个p的父元素 1.如果不是div,遍历上一层。 2.如果已经是顶层,排除此p。 3.如果是div,则保存此p元素。
由子元素来查找父元素,能得到更好的效率。看,打破常规思维后不仅步骤更简单了,而且效率上也得到了些许提升。
所有的选择器都可以这样解析吗?不是,采用right -> left的顺序是有前提条件的:没有位置关系的约束。
比如如下这段html:
<p id="p1">p1content
<p id="p2">p2content
</div>
<div>
<p id="p3">p3content
<p id="p4">p4content
</div>
对于选择器:$(“div p:first”)只会返回["#p1"]
而$(“div p:first-child”)则返回["#p1", "#p3"]
两者的区别在于位置filter的结果依赖于它前面的selector解析的结果,而其它 filter,只依赖于当前元素本身,就可以判断它是否满足filter。
那Sizzle是通过什么来判定进入哪一个流程呢,答案是origPOS的正则匹配,origPos指向了Expr中match对象的POS属性,而POS中存储了五花八门的位置类约束,如下:
/:(nth|eq|gt|lt|first|last|even|odd)(?:\((\d*)\))?(?=[^-]|$)/ //POS的值
这样一来,第一步的流程判断就已明朗。
当处于1的情况时:
首先根据需要对当前处理的A数组元素进行一系列修正操作(Expr.relative主刀)。然后调用posProcess函数对修复后的元素进行匹配.
其中,还需一层判断,如果有层级约束,eg ‘>,’:input’ 会转化为 ‘> :input’,因为在最初调用chunker进行预匹配的时候,这些是会被分割为单个数组元素的,但在这里需要将它们做一次合并,这是由posProcess所处理的数据格式所决定的
源码片段a: — posProcess函数匹配核心
// 这样一来,匹配对象便分离出来:selector(简单选择符存储器)和later(伪类选择符存储器)。
while ( (match = Expr. match. PSEUDO. exec ( selector ) ) ) {
later += match [0 ] ;
selector = selector. replace ( Expr. match. PSEUDO , "" ) ;
}
//构造selector,并调用Sizzle进行匹配,将结果存储在tmpSet中
selector = Expr. relative [selector ] ? selector + "*" : selector ;
for ( var i = 0 , l = root. length ; i < l ; i ++ ) {
Sizzle ( selector , root [i ] , tmpSet ) ;
}
// 最后便是filter的过滤
return Sizzle. filter ( later , tmpSet ) ;
源码片段b: — 对预匹配后的数组A中元素的处理
if ( parts. length === 2 & ;& ; Expr. relative [ parts [ 0 ] ] ) {
// 完成一次匹配, 由posProcess 内部调用 filter进行匹配
// 但在匹配前,完成了一次连接选择符的操作
// 存入set,注 set 当前还不是最终的结果,其这里的set和上面的tmpSet一样,都是一个"暂时性"的结果集
set = posProcess ( parts [0 ] + parts [1 ] , context ) ;
源码片段c: — 如果存在位置约束关系, 正向匹配。
[ context ] :
// 否则对队列首元素进行一次简单匹配操作
Sizzle ( parts. shift ( ) , context ) ;
分析Expr.relative,可以看出,它包含了4种dom元素间关系的判断,分别是 “+”, “>”, “”, “~”
每一轮的匹配,都会先判断A数组的首元素是不是代表tag间关系符(+,>等) ,而做后续处理.同时对A数组进行循环,依次做类似的处理
源码片段d — 对A数组(parts)的循环处理及后续
// 依次对 所匹配到的 数组中元素进行 递进匹配
selector = parts. shift ( ) ;
// '>' -> '>input' 的形式
if ( Expr. relative [ selector ] )
selector += parts. shift ( ) ;
set = posProcess ( selector , set ) ;
当处于2的情况时:
就有着不同之处,先看小片代码
源码片段e: — 根据当前流程设置ret(两种情况)
var ret = seed ? //seed 为上一次调用sizzle返回值, 即前文中提到的set|tmpset
//将预匹配后的A数组(parts)中的最后元素设置为ret的expr属性,set属性设为上一次匹配的结果集。
{ expr : parts. pop ( ) , set : makeArray (seed ) } :
//如果是第一次调用,则进行匹配操作,调用find函数
// 以parts数组最末元素为当前选择符,进行匹配操作,同时设置与之相关的context
Sizzle. find ( parts. pop ( ) , parts. length === 1 & ;& ; context. parentNode ? context. parentNode : context , isXML (context ) ) ;
2的情况为一般逻辑处理,从这小段代码便可得到Sizzle的匹配机制,每一次的调用都以数组末元素为基准,以上一次(或预设context)为上下文约束关系以右到左的匹配,最后返回匹配结果。结合了DOM结构的特性,性能上也得到了大幅的提升。
我们知道选择器的类型是有效率差别的,id选择器效率最高,其次是class、name、tag、最后是最差的*表达式。在Sizzle.find函数中,会按照这个效率的顺序查找元素,如果没有id就找class,依次下去。当然,class的支持需要方法getElementsByClassName。如果没有,就只好从id跳到name。
// ...
// 如果支持直接获取,则将获取class的方法 直接添加进 Expr.order中 ['ID', 'NAME', 'TAG']
Expr. order. splice ( 1 , 0 , "CLASS" ) ;
//同时在find中追加对class的获取
Expr. find. CLASS = function (match , context , isXML ) {
if ( typeof context. getElementsByClassName !== "undefined" & ;& ; !isXML ) {
return context. getElementsByClassName (match [1 ] ) ;
}
} ;
} ) ( ) ;
在Sizzle.find函数中,做了一系列的逻辑判断,来保证返回结果的正确性,首先在进入find时,保证了expr不为空的,然后根据表达式类型(id|name|tag|class?)来选择与之对应的匹配分支进行实现,最后再做适当的收尾工作,将返回结果定义为对象,来移交给filter,完成整个流程。
源码片段f: — find 函数核心
// 当然,如果浏览器支持对class的直接获取时,order中就会出现class的相关匹配规则
for ( var i = 0 , l = Expr. order. length ; i < l ; i ++ ) {
var type = Expr. order [i ] , match ;
// 根据 type 对所传进来的expr 进行正则匹配
// match中通过正则限制了这三类匹配方式的条件。
// 1. ID: /#((?:[\w\u00c0-\uFFFF_-]|\\.)+)/,
// 2. NAME: /\[name=['"]*((?:[\w\u00c0-\uFFFF_-]|\\.)+)['"]*\]/,
// 3. TAG: /^((?:[\w\u00c0-\uFFFF\*_-]|\\.)+)/,
if ( (match = Expr. match [ type ]. exec ( expr ) ) ) {
var left = RegExp. leftContext ;
//保证返回结果的正确性,如果存在\,则删除
if ( left. substr ( left. length - 1 ) !== "\\" ) {
match [1 ] = (match [1 ] || "" ). replace ( /\\/g , "" ) ;
// 根据type调用 sizzle.selector.find方法获取结果集。
set = Expr. find [ type ] ( match , context , isXML ) ;
if ( set != null ) {
//如果匹配成功,删除已经匹配的expr
expr = expr. replace ( Expr. match [ type ] , "" ) ;
break ;
}
}
}
}
return {set : set , expr : expr } ;
} ;
在所返回的对象中,expr的作用便是为了辅佐filter这把大器所需要完成任务的工具,到此就可以调用Sizzle.filter对ret.set再做一次精确匹配(匹配规则即ret.expr),以及tag间的位置约束关系的匹配(这部分同1中类似).
源码片段g: — 和源码片段d有类似之处。不作详述
var cur = parts. pop ( ) , pop = cur ;
// 是否存在 类似这样的匹配 eg: '+', '>'等
if ( !Expr. relative [ cur ] ) {
cur = "" ;
} else {
//如果存在层间关系的约束 则修复 cur 和pop的指向
// eg ['div', '+', 'span'] => pop = div; cur = '+'; 并进入 relative的匹配。
pop = parts. pop ( ) ;
}
// 确保拥有上下文 代码略过
Expr. relative [ cur ] ( checkSet , pop , isXML (context ) ) ;
}
之后便接近sizzle尾声:结果集的处理(将所匹配的结果set 追加进 result中)。当然,如果有多表达式,便会再一次调用。
实例
以’div > span p span:last’这个选择符为例,看看它的调用链是如何顺次完成的。
根据对源码的剖析,理解如下:
- jquery.init -> jquery.prototype.find
- 进入Sizzle(对xml的判断) -> 设置parts数组等在匹配中所需要的元素 -> 根据数组长度以及调用origPos进行判断,来决定进入哪个分支,在这个实例下进入分支1
- 循环调用Sizzle进行匹配,将结果存入set中(因为在这一过程中是循环调用,所以对Sizzle的判断也是需要多次,进入哪一分支当然也会是不一样的,比如第二轮循环判断则进入分支2中进行处理) ,对于>号的处理,也会将它合并在其后的span中,构成新的选择符 ‘>span’,然后进入Expr.relative进行匹配,同时调用posProcess。
- 调用Sizzle.find 匹配除伪类以外的部分(即这里的选择器不包含:last),首先会调用Expr.find的find方法来判断是否为哪一类匹配,在这一实例中,为TAG匹配。
- 对从4步中生成的对象进行过滤,匹配’>'(这一步的匹配是由Sizzle.filter触发,由Expr.relative完成),而在匹配’span:last’时则由posProcess来触发,设置later值(:first)以及selector(span),对span的匹配和4步骤一样,重复匹配,而对:first的匹配则是第5步的重头戏,也就是调用Sizzle.filter来完成, 由此便生成了最后的匹配结果。
对于有‘,’这样需要合并的选择器,Sizzle在获取结果后会按照文档流进行排序。所以,你可能会遇到这样的问题:把一个结果集append到新的节点后,新的节点可能不会按照你书写的选择器的顺序出现。
以上,可以得出以下结论:大致通过如下步骤来完成:
1.对表达式分组。 2.选择合适的处理顺序。 3.在当前的上下文里过滤要找的节点。并更新上下文。重复这一过程,直到结尾。 4.对结果排序,如果需要的话。 5.返回结果数组。
前向兼容
querySelectorAll
其实不止这一处,在Sizzle的API手册中Internal部分的find 函数(与filter构成了Sizzle的两把宝剑),在传递进该方法的参数可以用 querySelectorAll() (依赖于当前的浏览器执行环境) 直接获取时,它则直接调用该方法,既拥有了向前兼容的特性,又达到了速度的提升。
虽然有些环境实现了方法querySelectorAll,但是会有bug。
if ( document. querySelectorAll ) ( function ( ) {
var oldSizzle = Sizzle ;
// 解决Safari bug 略过 ...
Sizzle = function (query , context , extra , seed ) {
context = context || document ;
// 因为querySelectorAll 在domElement 节点上操作时,存在bug 所以多了这样的判断
// bug info: http://ejohn.org/blog/thoughts-on-queryselectorall/
if ( !seed & ;& ; context. nodeType === 9 & ;& ; !isXML (context ) ) {
return makeArray ( context. querySelectorAll (query ) , extra ) ;
}
// querySelectorAll 可用则直接返回结果,否则才调用 sizzle
return oldSizzle (query , context , extra , seed ) ;
} ;
// oldSizzle 方法追加进 新的 Sizzle 中
} ) ( ) ;
对于任何一个开发者,我想,若浏览器原生已提供了实现方法,他都不会去高效而求繁琐吧。这一点在Sizzle中得到了充分的体现,总是尽可能的使用相应环境下已实现的原生方法。所以在IE的低版本中(比如IE6)Sizzle的表现更加出众,在高级的浏览器中的对比却没有那么大的差别。
扩展
如何定义自己的选择器呢.如果项目中频繁使用某些过滤规则,是不是把它作为一个选择器更有效呢。
既然javascript的对象可以任意扩充,只要我们访问得到,那么我们就可以很轻松得创建出自己的选择器
在jQuery.expr.filter对象中,有很多内置的选择器,比如 ‘disabled’,'text’,那我们就扩充它,比如,想寻找包含span的div元素
jQuery. expr [ ":" ] = jQuery. expr. filters ;
$. extend ($. expr [ ':' ] , {
hasSpan : function (e ) {
return $ (e ). find ( 'span' ). length > 0 ;
}
} ) ;
这样,我们就拥有了 ‘:hasSpan’ 的选择器,使用当然和默认的一样。
$ ( 'div:hasSpan' )....
比较
再拾YUI3,在经过大幅度变化,以全新姿态出现,从选择器上的执行上效率不逊色于Sizzle几毫,初看YUI时就一直对它的模块细粒度化赞不绝口,但是从如我这样的实用主义者的角度来看,选择器就应该是一个单独的模块,就如同jQuery分离而出的Sizzle。但在YUI term眼里,为了让代码的组织结构看上去更加的理想化,更加具有”YUI3“的特色,将之在代码结构上又细分出一二三,比起Sizzle的简洁,它显得太过学院派。
除此,在选择器的扩展上,sizzle表现胜于YUI3 selector,在实现css1~css3选择器的基础上,又对常用的功能进行了扩展。比如对表单元素快捷操作。据我所知,开发者对这类型选择器的使用频率并不是想象中那么低。既然有了模块的细分,为什么不将这部分作为一个可扩充性的功能点模块融入框架中呢。Sizzle于开发者就如同一块可口味佳的点心,满足我们各式各样的胃口,简洁,不失其功能的强劲,这点非常值得称道。
总得来看,Sizzle与YUI就好象一个面向实际与理想主义的比较。这里没有对错之分,从不同角度来看,都能略窥其各自的禅意。前者从如何为开发者带来便利的角度考虑,让开发者实时觉得它的简单可信赖。后者,也寄托了自己对web的构想,如果浏览器原生全部支持css3-selector,那岂不是完全不用引入该模块了,不过我想,真到那时候,各框架也都会有很大的变化了,只是我对这一天的到来抱有比较消极的态度,这是后话。
总结
本文从总体上讨论了jQuery之Sizzle选择器的实现原理,通过一个初步的流程分析,让各位读者对此有一个大致印象,毫无疑问,更深层次的匹配,也只是它的递归调用,再匹配而已。
这里,没有做与其他框架在效率上的比较,如果你还对它的效率还有所怀疑的话,你可以自行比较。
如果你感兴趣,更推荐你继续去探索在1.4中着重优化的api源码,或许,会给你更多的启示
思考
从jQuery的角度来讲,Sizzle的出现随之也带来了web上的一些新的局面,在追求效率的同时,即使是这类单种子模式的库也是需要将之分离开来,来设计成能够独立使用,独立维护的引擎。
从选择器的角度来讲,Sizzle这次算法的提升,我初步的结论是它结合了DOM这一特定的数据结构,使其每次的匹配能够更精准,以此获得引擎效率上的提升。
我们可否多想想,在思维的开拓上能给我们留下多少财富。很多问题的解决,在换一种新的思维方式后,是不是常常会有柳暗花明的感觉呢。
相关参考:
W3C css selector:CSS1,CSS2,CSS3
CSS Support History -Brian Wilson
CSS Selectors and Pseudo Selectors and browser support – kimblim.dk
Javascript CSS Selector Engine Timeline – Paul Irish
http://www.baiduux.com/blog/2010/07/15/the_sizzle_in_jquery/