推荐系统之矩阵分解及C++实现
1.引言
矩阵分解(Matrix Factorization, MF)是传统推荐系统最为经典的算法,思想来源于数学中的奇异值分解(SVD), 但是与SVD 还是有些不同,形式就可以看出SVD将原始的评分矩阵分解为3个矩阵,而推荐本文要介绍的MF是直接将一个矩阵分解为两个矩阵,一个包含Users 的因子向量,另一个包含着Items 的因子向量。
2.原理简介
假如电影分为三类:动画片,武打片,纪录片,而某一部电影对应这三类的隶属度分别为 0, 0.2, 0.7,可以看出这是一部纪录片里面有些武打成分,现在给定某个用户对着三类电影的喜欢程度用0 到1 之间的值表示分别为 0.1,0.6,0.2, 可以看出该用户最喜欢武打片,而不怎么喜欢其他两种,于是可以预测用户对刚才的电影打分(喜欢程度)为:0*0.1+0.2*0.6+0.7*0.2 = 0.26
矩阵分解的动机来源于此,因为利用用户的历史评分矩阵(参考我的上一篇推荐系统之协同过滤的原理及C++实现),如果能够得到反映每一用户的对每个Item喜好的因子向量,同时得到每个Item 属于每一类的隶属度向量,利用上面的方法就很容易得出每个用户对每个Item的预测评分,利用这个评分的高低就可以进行推荐高分的Items给相应的用户了.
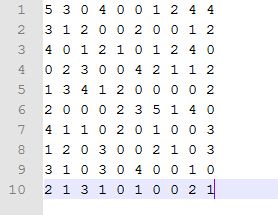
例如这个10*10的历史评分矩阵A, 可以分解为一个10 * 5 的矩阵 B 乘以一个5 * 10 的矩阵 C ,这样可以把 B 看做是用户偏好矩阵,里面包含着用户对每一类Items 的偏好程度的向量,B 的转置看作是包含着衡量每一个Item 属于5类的隶属度的向量,当然这个 5 可以是自己设定的任意值,但是原则上要求要比原来的矩阵A中的列数或者行数小 ,起到一个降维的作用。B 和 C的初始值可以随机初始化,然后B和C相乘得到评分,与历史真实评分对比,通过梯度下降算法不断调整B和C中的值,使得B和C相乘后得到的矩阵与真实的历史评分矩阵之间的差别越小越好,最终得到较好的B 和C 就可以用来预测用户对任意Item的评分了,更加详细的解释参考:Matrix_factorization_techniques_for_recommender_systems.pdf
3.实现
本次实现的是一个带偏置的矩阵分解,数据集是movielens.rar,已经处理成了矩阵形式
读取和保存txt数据的头文件
1 #ifndef READANDWRITEDATA_H 2 #define READANDWRITEDATA_H
3 #include <iostream>
4 #include <fstream>
5 #include <vector>
6 #include <string>
7
8 using namespace std; 9
10 template <typename T>
11 vector<vector<T> > txtRead(string FilePath,int row,int col) 12 { 13 ifstream input(FilePath); 14 if (!input.is_open()) 15 { 16 cerr << "File is not existing, check the path: \n" << FilePath << endl; 17 exit(1); 18 } 19 vector<vector<T> > data(row, vector<T>(col,0)); 20 for (int i = 0; i < row; ++i) 21 { 22 for (int j = 0; j < col; ++j) 23 { 24 input >> data[i][j]; 25 } 26 } 27 return data; 28 } 29
30 template<typename T>
31 void txtWrite(vector<vector<T> > Matrix, string dest) 32 { 33 ofstream output(dest); 34 vector<vector<T> >::size_type row = Matrix.size(); 35 vector<T>::size_type col = Matrix[0].size(); 36 for (vector<vector<T> >::size_type i = 0; i < row; ++i) 37 { 38 for (vector<T>::size_type j = 0; j < col; ++j) 39 { 40 output << Matrix[i][j]; 41 } 42 output << endl; 43 } 44 } 45 #endif
评价函数,这里还是采用RMSE来评价
1 #ifndef EVALUATE_H 2 #define EVALUATE_H
3 #include <cmath>
4 #include <vector>
5 using namespace std; 6 double ComputeRMSE(vector<vector<double> > predict, vector<vector<double> > test) 7 { 8 int Counter = 0; 9 double sum = 0; 10 for (vector<vector<double> >::size_type i = 0; i < test.size(); ++i) 11 { 12 for (vector<double>::size_type j = 0; j < test[0].size(); ++j) 13 { 14 if (predict[i][j] && test[i][j]) 15 { 16 ++Counter; 17 sum += pow((test[i][j] - predict[i][j]), 2); 18 } 19 } 20 } 21 return sqrt(sum / Counter); 22 } 23
24 #endif
最后是主程序
1 #include "Evaluate.h"
2 #include "ReadAndWriteData.h"
3
4 #include <cmath>
5 #include <algorithm>
6 #include <vector>
7 #include <iostream>
8
9 using namespace std; 10
11
12 double InnerProduct(vector<double> A, vector<double> B) //计算两个向量的内积 13 { 14 double res = 0; 15 for(vector<double>::size_type i = 0; i < A.size(); ++i) 16 { 17 res += A[i] * B[i]; 18 } 19 return res; 20 } 21
22 template<typename T> //对矩阵(二维数组)进行转置操作
23 vector<vector<T> > Transpose(vector<vector<T> > Matrix) 24 { 25 unsigned row = Matrix.size(); 26 unsigned col = Matrix[0].size(); 27 vector<vector<T> > Trans(col,vector<T>(row,0)); 28 for (unsigned i = 0; i < col; ++i) 29 { 30 for (unsigned j = 0; j < row; ++j) 31 { 32 Trans[i][j] = Matrix[j][i]; 33 } 34 } 35 return Trans; 36 } 37
38 vector<vector<double> > BiasedMF(vector<vector<double> > train, double lr, double penalty, 39 int maxItr) 40 { 41 unsigned row = train.size(); 42 unsigned col = train[0].size(); 43 //计算全局平均分
44 double avg = 0; 45 int Counter = 0; 46 for (unsigned i = 0; i < row; ++i) 47 { 48 for(unsigned j = 0; j < col; ++j) 49 { 50 if (train[i][j]) 51 { 52 avg += train[i][j]; 53 ++Counter; 54 } 55 } 56 } 57 avg /= Counter; 58 //初始化Items偏置
59 vector<double> ItemsBias(col,0); 60 vector<vector<double> > Transtrain = Transpose(train); 61 for (unsigned i = 0; i < col; ++i) 62 { 63 int Counter = 0; 64 double sum = 0; 65 for (unsigned j = 0; j < row; ++j) 66 { 67 if (Transtrain[i][j]) 68 { 69 sum += Transtrain[i][j] - avg; 70 ++Counter; 71 } 72
73 } 74 ItemsBias[i] = sum / (25 + Counter); 75 } 76
77 //初始化Users偏置
78 vector<double> UsersBias(row, 0); 79 for (unsigned i = 0; i < row; ++i) 80 { 81 int Counter = 0; 82 double sum = 0; 83 for (unsigned j = 0; j < col; ++j) 84 { 85 if (train[i][j]) 86 { 87 sum += train[i][j] - avg - ItemsBias[j]; 88 ++Counter; 89 } 90 } 91 UsersBias[i] = sum / (10 + Counter); 92 } 93
94 //初始化Users和Items对应的矩阵
95 unsigned k = 10; 96 vector<vector<double> > predict(row,vector<double>(col, 0)); 97 vector<vector<double> > Users(row, vector<double>(k, 0)); 98 vector<vector<double> > Items(col, vector<double>(k, 0)); 99
100
101 //梯度下降迭代
102 double rmse = 100; 103 int it = 0; 104 while(it < maxItr) 105 { 106 for (unsigned i = 0; i < row; ++i) 107 { 108 for (unsigned j = 0; j < col; ++j) 109 { 110 predict[i][j] = InnerProduct(Users[i],Items[j]) + UsersBias[i] 111 + ItemsBias[j]; 112 } 113 } 114 double new_rmse = ComputeRMSE(predict, train); 115 if (new_rmse < rmse) 116 rmse = new_rmse; 117 cout << "第 "<< it << "次迭代:" << endl; 118 cout << "rmse is: " << rmse << endl; 119 for (unsigned i = 0; i < row; ++i) 120 { 121 for (unsigned j = 0; j < col; ++j) 122 { 123 if (train[i][j]) 124 { 125 double err = train[i][j] - predict[i][j]; 126 //更新User i 和Item j 的因子向量
127 for (unsigned t = 0; t < k; ++t) 128 { 129 double tmp = Users[i][t]; 130 Users[i][t] += lr *(err * Items[j][t] - penalty * Users[i][t]); 131 Items[j][t] += lr * (err * tmp - penalty * Items[j][t]); 132 } 133 //更新User i和Item j的偏差
134 double tmp = UsersBias[i] + ItemsBias[j] - avg; 135 UsersBias[i] += lr * (err - penalty * tmp); 136 ItemsBias[j] += lr * (err - penalty * tmp); 137 } 138 } 139 } 140 ++it; 141 } 142 return predict; 143 } 144
145 int main() 146 { 147
148 string FilePath1("E:\\Matlab code\\recommendation system\\data\\movielens\\train.txt"); 149 string FilePath2("E:\\Matlab code\\recommendation system\\data\\movielens\\test.txt"); 150
151 int row = 943; 152 int col = 1682; 153 vector<vector<double> > train = txtRead<double>(FilePath1, row, col); 154 vector<vector<double> > predict = BiasedMF(train, 0.001, 0.003,100); 155 txtWrite(predict, "predict.txt"); 156 vector<vector<double> > test = txtRead<double>(FilePath2, 462, 1591); 157 double rmse = ComputeRMSE(predict,test); 158 cout << "ProbeRMSE is " << rmse <<endl; 159 return 0; 160 }
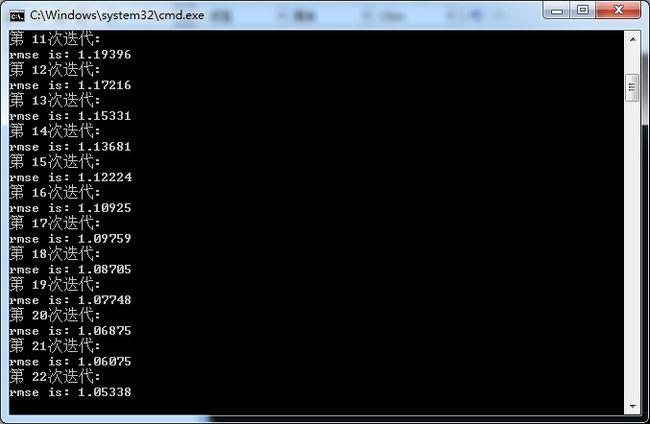
4.运行
下面是运行过程中的截图,可以看出运行过程中RMSE逐渐减小,表示与真实的历史评分矩阵差别在减小,由于时间关系没有运行完,根据以前在Matlab上的运行结果,最终的RMSE应该可以达到0.92左右,当然这只是在训练集上的RMSE,最终效果要测出在测试集上的RMSE, 要比上一篇讲到的基于用户的协同过滤好一些,关于用户和Items因子向量的初始化会对结果有一定影响,本文中只是全部初始化为0其实不太好,有兴趣的读者可以自己尝试其他分布函数来初始化,但是总体上不会有什么太大的影响,有什么问题可以联系我。