dojo/query源码解析
dojo/query模块是dojo为开发者提供的dom查询接口。该模块的输出对象是一个使用css选择符来查询dom元素并返回NodeList对象的函数。同时,dojo/query模块也是一个插件,开发者可以使用自定义的查询引擎,query模块会负责将引擎的查询结果包装成dojo自己的NodeList对象。
require(["dojo/query!sizzle"], function(query){ query("div")...
要理解这个模块就要搞清楚两个问题:
- 如何查询,查询的原理?
- 查询结果是什么,如何处理查询结果?
这两个问题涉及到本文的两个主题:选择器引擎和NodeList。
选择器引擎
前端的工作必然涉及到与DOM节点打交道,我们经常需要对一个DOM节点进行一系列的操作。但我们如何找到这个DOM节点呢,为此我们需要一种语言来告诉浏览器我们想要就是这个语言描述的dom节点,这种语言就是CSS选择器。比如我们想浏览器描述一个dom节点:div > p + .bodhi input[type="checkbox"],它的意思是在div元素下的直接子元素p的下一个class特性中含有bodhi的兄弟节点下的type属性是checkbox的input元素。
选择符种类
- 元素选择符:通配符*、类型选择符E、类选择符E.class、ID选择符E#id
- 关系选择符:包含(E F)、子选择符(E>F)、相邻选择符(E+F)、兄弟选择符(E~F)
- 属性选择符: E[att]、E[att="val"]、E[att~="val"]、E[att^="val"]、E[att$="val"]、E[att*="val"]
- 伪类选择符
- 伪对象选择符:E:first-letter、E:first-line、E:before、E:after、E::placehoser、E::selection
通过选择器来查询DOM节点,最简单的方式是依靠浏览器提供的几个原生接口:getElementById、getElementsByTagName、getElementsByName、getElementsByClassName、querySelector、querySelectorAll。但因为低版本浏览器不完全支持这些接口,而我们实际工作中有需要这些某些高级接口,所以才会有各种各样的选择器引擎。所以选择器引擎就是帮我们查询DOM节点的代码类库。
选择器引擎很简单,但是一个高校的选择器引擎会涉及到词法分析和预编译。不懂编译原理的我表示心有余而力不足。
但需要知道的一点是:解析css选择器的时候,都是按照从右到左的顺序来的,目的就是为了提高效率。比如“div p span.bodhi”;如果按照正向查询,我们首先要找到div元素集合,从集合中拿出一个元素,再找其中的p集合,p集合中拿出一个元素找class属性是bodhi的span元素,如果没找到重新回到开头的div元素,继续查找。这样的效率是极低的。相反,如果按照逆向查询,我们首先找出class为bodhi的span元素集合,在一直向上回溯看看祖先元素中有没有选择符内的元素即可,孩子找父亲很容易,但父亲找孩子是困难的。
选择器引擎为了优化效率,每一个选择器都可以被分割为好多部分,每一部分都会涉及到标签名(tag)、特性(attr)、css类(class)、伪节点(persudo)等,分割的方法与选择器引擎有关。比如选择器 div > p + .bodhi input[type="checkbox"]如果按照空格来分割,那它会被分割成以下几部分:- div
- >
- p
- +
- .bodhi
- input[type="checkbox"]
对于每一部分选择器引擎都会使用一种数据结构来表达这些选择符,如dojo中acme使用的结构:
{ query: null, // the full text of the part's rule pseudos: [], // CSS supports multiple pseud-class matches in a single rule attrs: [], // CSS supports multi-attribute match, so we need an array classes: [], // class matches may be additive, e.g.: .thinger.blah.howdy tag: null, // only one tag... oper: null, // ...or operator per component. Note that these wind up being exclusive. id: null, // the id component of a rule getTag: function(){ return caseSensitive ? this.otag : this.tag; } }
从这里可以看到有专门的结构来管理不同的类型的选择符。分割出来的每一部分在acme中都会生成一个part,part中有tag、伪元素、属性、元素关系等。。;所有的part都被放到queryParts数组中。然后从右到左每次便利一个part,低版本浏览器虽然不支持高级接口,但是一些低级接口还是支持的,比如:getElementsBy*;对于一个part,先匹配tag,然后判断class、attr、id等。这是一种解决方案,但这种方案有很严重的效率问题。(后面这句是猜想)试想一下:我们可不可以把一个part中有效的几项的判断函数来组装成一个函数,对于一个part只执行一次即可。没错,acme就是这样来处理的(这里涉及到预编译问题,看不明白的自动忽略即可。。。)
1 define(["../has", "require"], 2 function(has, require){ 3 4 "use strict"; 5 var testDiv = document.createElement("div"); 6 has.add("dom-qsa2.1", !!testDiv.querySelectorAll); 7 has.add("dom-qsa3", function(){ 8 // test to see if we have a reasonable native selector engine available 9 try{ 10 testDiv.innerHTML = "<p class='TEST'></p>"; // test kind of from sizzle 11 // Safari can't handle uppercase or unicode characters when 12 // in quirks mode, IE8 can't handle pseudos like :empty 13 return testDiv.querySelectorAll(".TEST:empty").length == 1; 14 }catch(e){} 15 }); 16 var fullEngine; 17 var acme = "./acme", lite = "./lite"; 18 return { 19 // summary: 20 // This module handles loading the appropriate selector engine for the given browser 21 22 load: function(id, parentRequire, loaded, config){ 23 var req = require; 24 // here we implement the default logic for choosing a selector engine 25 id = id == "default" ? has("config-selectorEngine") || "css3" : id; 26 id = id == "css2" || id == "lite" ? lite : 27 id == "css2.1" ? has("dom-qsa2.1") ? lite : acme : 28 id == "css3" ? has("dom-qsa3") ? lite : acme : 29 id == "acme" ? acme : (req = parentRequire) && id; 30 if(id.charAt(id.length-1) == '?'){ 31 id = id.substring(0,id.length - 1); 32 var optionalLoad = true; 33 } 34 // the query engine is optional, only load it if a native one is not available or existing one has not been loaded 35 if(optionalLoad && (has("dom-compliant-qsa") || fullEngine)){ 36 return loaded(fullEngine); 37 } 38 // load the referenced selector engine 39 req([id], function(engine){ 40 if(id != "./lite"){ 41 fullEngine = engine; 42 } 43 loaded(engine); 44 }); 45 } 46 }; 47 });
选择器引擎的代码晦涩难懂,我们只需要关心最终暴露出来的接口的用法即可。
acme:
query = function(/*String*/ query, /*String|DOMNode?*/ root) ............ query.filter = function(/*Node[]*/ nodeList, /*String*/ filter, /*String|DOMNode?*/ root) ............ return query;
lite:
liteEngine = function(selector, root) ............... liteEngine.match = function(node, selector, root) .............. return liteEngine
NodeList
objects are collections of nodes such as those returned by Node.childNodes and the document.querySelectorAll method.
NodeList is a static collection, meaning any subsequent change in the DOM does not affect the content of the collection. document.querySelectorAll returns a static NodeList.
- dojo中的NodeList就是扩展了能力的Array实例。所以需要一个函数将原生array包装起来
- NodeList的任何方法返回的还是NodeList实例。就像Array的slice、splice还是返回一个array一样
has("array-extensible")的作用是判断数组是否可以被继承,如果原生的数组是可被继承的,那就将NodeList的原型指向一个数组实例,否则指向普通对象。
var nl = NodeList, nlp = nl.prototype = has("array-extensible") ? [] : {};// extend an array if it is extensible
下面这句话需要扎实的基本功,如果理解这句话,整个脉络就会变得清晰起来。
var NodeList = function(array){ var isNew = this instanceof nl && has("array-extensible"); // 是不是通过new运算符模式调用 。。。。。。。。。。 };
new的作用等于如下函数:
Function.prototype.new = function(){ // this指向的new运算符所作用的构造函数 var that = Object.create(this.prototype); var other = this.apply(that, arguments); return (other && typeof other === 'object') || that; }
放到NodeList身上是这样的:
var nl = new NodeList(array); //等于一下操作 var that = Object.create(NodeList.prototype); //这时候NodeList中的this关键字指向that,that是NodeList的实例 var other = NodeList.apply(that, array); nl = (other && typeof other === 'object') || that;
isNew为true,保证了NodeList实例是一个经过扩展的array对象。
NodeList函数的源码:
var NodeList = function(array){ var isNew = this instanceof nl && has("array-extensible"); // 是不是通过new运算符模式调用 if(typeof array == "number"){ array = Array(array); // 如果array是数字,就创建一个array数量的数组 } //如果array是一个数组或类数组对象,nodeArray等于array否者是arguments var nodeArray = (array && "length" in array) ? array : arguments; //如果this是nl的实例或者nodeArray是类数组对象,则进入if语句 if(isNew || !nodeArray.sort){ // make sure it's a real array before we pass it on to be wrapped //if语句的行为保证了经过该函数包装后的对象的是一个真正的数组对象。 var target = isNew ? this : [], l = target.length = nodeArray.length; for(var i = 0; i < l; i++){ target[i] = nodeArray[i]; } if(isNew){//这时候便不再需要扩展原生array了 return target; } nodeArray = target; } // called without new operator, use a real array and copy prototype properties, // this is slower and exists for back-compat. Should be removed in 2.0. lang._mixin(nodeArray, nlp); // _NodeListCtor指向一个将array包装成NodeList的函数 nodeArray._NodeListCtor = function(array){ // call without new operator to preserve back-compat behavior return nl(array); }; return nodeArray; };
可以看到如果isNew为false,那就对一个新的array对象进行扩展。
扩展的能力,便是直接在NodeList.prototype上增加的方法。大家直接看源码和我的注释即可。
1 // add array redirectors 2 forEach(["slice", "splice"], function(name){ 3 var f = ap[name]; 4 //Use a copy of the this array via this.slice() to allow .end() to work right in the splice case. 5 // CANNOT apply ._stash()/end() to splice since it currently modifies 6 // the existing this array -- it would break backward compatibility if we copy the array before 7 // the splice so that we can use .end(). So only doing the stash option to this._wrap for slice. 8 //类似于:this._wrap(this.slice(parameter), this); 9 nlp[name] = function(){ return this._wrap(f.apply(this, arguments), name == "slice" ? this : null); }; 10 }); 11 // concat should be here but some browsers with native NodeList have problems with it 12 13 // add array.js redirectors 14 forEach(["indexOf", "lastIndexOf", "every", "some"], function(name){ 15 var f = array[name]; 16 //类似于:dojo.indexOf(this, parameter) 17 nlp[name] = function(){ return f.apply(dojo, [this].concat(aps.call(arguments, 0))); }; 18 }); 19 20 lang.extend(NodeList, {//将属性扩展至原型链 21 // copy the constructors 22 constructor: nl, 23 _NodeListCtor: nl, 24 toString: function(){ 25 // Array.prototype.toString can't be applied to objects, so we use join 26 return this.join(","); 27 }, 28 _stash: function(parent){//保存parent,parent应当也是nl的一个实例 29 // summary: 30 // private function to hold to a parent NodeList. end() to return the parent NodeList. 31 // 32 // example: 33 // How to make a `dojo/NodeList` method that only returns the third node in 34 // the dojo/NodeList but allows access to the original NodeList by using this._stash: 35 // | require(["dojo/query", "dojo/_base/lang", "dojo/NodeList", "dojo/NodeList-dom" 36 // | ], function(query, lang){ 37 // | lang.extend(NodeList, { 38 // | third: function(){ 39 // | var newNodeList = NodeList(this[2]); 40 // | return newNodeList._stash(this); 41 // | } 42 // | }); 43 // | // then see how _stash applies a sub-list, to be .end()'ed out of 44 // | query(".foo") 45 // | .third() 46 // | .addClass("thirdFoo") 47 // | .end() 48 // | // access to the orig .foo list 49 // | .removeClass("foo") 50 // | }); 51 // 52 this._parent = parent; 53 return this; // dojo/NodeList 54 }, 55 56 on: function(eventName, listener){//绑定事件 57 // summary: 58 // Listen for events on the nodes in the NodeList. Basic usage is: 59 // 60 // example: 61 // | require(["dojo/query" 62 // | ], function(query){ 63 // | query(".my-class").on("click", listener); 64 // This supports event delegation by using selectors as the first argument with the event names as 65 // pseudo selectors. For example: 66 // | query("#my-list").on("li:click", listener); 67 // This will listen for click events within `<li>` elements that are inside the `#my-list` element. 68 // Because on supports CSS selector syntax, we can use comma-delimited events as well: 69 // | query("#my-list").on("li button:mouseover, li:click", listener); 70 // | }); 71 var handles = this.map(function(node){ 72 return on(node, eventName, listener); // TODO: apply to the NodeList so the same selector engine is used for matches 73 }); 74 handles.remove = function(){ 75 for(var i = 0; i < handles.length; i++){ 76 handles[i].remove(); 77 } 78 }; 79 return handles; 80 }, 81 82 end: function(){//由当前的nl返回父nl 83 // summary: 84 // Ends use of the current `NodeList` by returning the previous NodeList 85 // that generated the current NodeList. 86 // description: 87 // Returns the `NodeList` that generated the current `NodeList`. If there 88 // is no parent NodeList, an empty NodeList is returned. 89 // example: 90 // | require(["dojo/query", "dojo/NodeList-dom" 91 // | ], function(query){ 92 // | query("a") 93 // | .filter(".disabled") 94 // | // operate on the anchors that only have a disabled class 95 // | .style("color", "grey") 96 // | .end() 97 // | // jump back to the list of anchors 98 // | .style(...) 99 // | }); 100 // 101 if(this._parent){ 102 return this._parent; 103 }else{ 104 //Just return empty list. 105 return new this._NodeListCtor(0); 106 } 107 }, 108 109 110 concat: function(item){ 111 // summary: 112 // Returns a new NodeList comprised of items in this NodeList 113 // as well as items passed in as parameters 114 // description: 115 // This method behaves exactly like the Array.concat method 116 // with the caveat that it returns a `NodeList` and not a 117 // raw Array. For more details, see the [Array.concat 118 // docs](https://developer.mozilla.org/en/JavaScript/Reference/Global_Objects/Array/concat) 119 // item: Object? 120 // Any number of optional parameters may be passed in to be 121 // spliced into the NodeList 122 123 //return this._wrap(apc.apply(this, arguments)); 124 // the line above won't work for the native NodeList, or for Dojo NodeLists either :-( 125 126 // implementation notes: 127 // Array.concat() doesn't recognize native NodeLists or Dojo NodeLists 128 // as arrays, and so does not inline them into a unioned array, but 129 // appends them as single entities. Both the original NodeList and the 130 // items passed in as parameters must be converted to raw Arrays 131 // and then the concatenation result may be re-_wrap()ed as a Dojo NodeList. 132 133 var t = aps.call(this, 0), 134 m = array.map(arguments, function(a){//array.concat方法不会将原始的NodeList和dojo的NodeList作为数组来处理,所以在这之前将他们转化成普通的数组 135 return aps.call(a, 0); 136 }); 137 return this._wrap(apc.apply(t, m), this); // dojo/NodeList 138 }, 139 140 map: function(/*Function*/ func, /*Function?*/ obj){ 141 // summary: 142 // see `dojo/_base/array.map()`. The primary difference is that the acted-on 143 // array is implicitly this NodeList and the return is a 144 // NodeList (a subclass of Array) 145 return this._wrap(array.map(this, func, obj), this); // dojo/NodeList 146 }, 147 148 forEach: function(callback, thisObj){ 149 // summary: 150 // see `dojo/_base/array.forEach()`. The primary difference is that the acted-on 151 // array is implicitly this NodeList. If you want the option to break out 152 // of the forEach loop, use every() or some() instead. 153 forEach(this, callback, thisObj); 154 // non-standard return to allow easier chaining 155 return this; // dojo/NodeList 156 }, 157 filter: function(/*String|Function*/ filter){ 158 // summary: 159 // "masks" the built-in javascript filter() method (supported 160 // in Dojo via `dojo/_base/array.filter`) to support passing a simple 161 // string filter in addition to supporting filtering function 162 // objects. 163 // filter: 164 // If a string, a CSS rule like ".thinger" or "div > span". 165 // example: 166 // "regular" JS filter syntax as exposed in `dojo/_base/array.filter`: 167 // | require(["dojo/query", "dojo/NodeList-dom" 168 // | ], function(query){ 169 // | query("*").filter(function(item){ 170 // | // highlight every paragraph 171 // | return (item.nodeName == "p"); 172 // | }).style("backgroundColor", "yellow"); 173 // | }); 174 // example: 175 // the same filtering using a CSS selector 176 // | require(["dojo/query", "dojo/NodeList-dom" 177 // | ], function(query){ 178 // | query("*").filter("p").styles("backgroundColor", "yellow"); 179 // | }); 180 181 var a = arguments, items = this, start = 0; 182 if(typeof filter == "string"){ // inline'd type check 183 items = query._filterResult(this, a[0]);//如果filter是css选择器,调用query的filter方法从已有集合中选择合适的元素 184 if(a.length == 1){ 185 // if we only got a string query, pass back the filtered results 186 return items._stash(this); // dojo/NodeList 187 } 188 // if we got a callback, run it over the filtered items 189 start = 1; 190 } 191 //如果filter是函数,那就调用array的filter先过滤在包装。 192 return this._wrap(array.filter(items, a[start], a[start + 1]), this); // dojo/NodeList 193 }, 194 instantiate: function(/*String|Object*/ declaredClass, /*Object?*/ properties){ 195 // summary: 196 // Create a new instance of a specified class, using the 197 // specified properties and each node in the NodeList as a 198 // srcNodeRef. 199 // example: 200 // Grabs all buttons in the page and converts them to dijit/form/Button's. 201 // | var buttons = query("button").instantiate(Button, {showLabel: true}); 202 //这个方法主要用于将原生dom元素实例化成dojo的dijit 203 var c = lang.isFunction(declaredClass) ? declaredClass : lang.getObject(declaredClass); 204 properties = properties || {}; 205 return this.forEach(function(node){ 206 new c(properties, node); 207 }); // dojo/NodeList 208 }, 209 at: function(/*===== index =====*/){ 210 // summary: 211 // Returns a new NodeList comprised of items in this NodeList 212 // at the given index or indices. 213 // 214 // index: Integer... 215 // One or more 0-based indices of items in the current 216 // NodeList. A negative index will start at the end of the 217 // list and go backwards. 218 // 219 // example: 220 // Shorten the list to the first, second, and third elements 221 // | require(["dojo/query" 222 // | ], function(query){ 223 // | query("a").at(0, 1, 2).forEach(fn); 224 // | }); 225 // 226 // example: 227 // Retrieve the first and last elements of a unordered list: 228 // | require(["dojo/query" 229 // | ], function(query){ 230 // | query("ul > li").at(0, -1).forEach(cb); 231 // | }); 232 // 233 // example: 234 // Do something for the first element only, but end() out back to 235 // the original list and continue chaining: 236 // | require(["dojo/query" 237 // | ], function(query){ 238 // | query("a").at(0).onclick(fn).end().forEach(function(n){ 239 // | console.log(n); // all anchors on the page. 240 // | }) 241 // | }); 242 //与array中的位置选择器类似 243 244 var t = new this._NodeListCtor(0); 245 forEach(arguments, function(i){ 246 if(i < 0){ i = this.length + i; } 247 if(this[i]){ t.push(this[i]); } 248 }, this); 249 return t._stash(this); // dojo/NodeList 250 } 251 });
NodeList提供的很多操作,如:map、filter、concat等,都是借助原生的Array提供的相应方法,这些方法返回都是原生的array对象,所以需要对返回的array对象进行包装。有趣的是NodeList提供end()可以回到原始的NodeList中。整个结构如下:
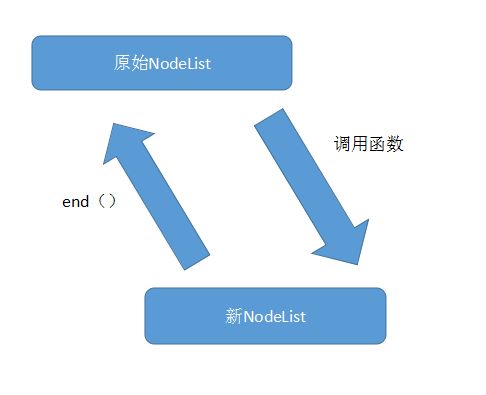
我们来看一下包装函数:
nl._wrap = nlp._wrap = tnl; var tnl = function(/*Array*/ a, /*dojo/NodeList?*/ parent, /*Function?*/ NodeListCtor){ //将a包装成NodeList var nodeList = new (NodeListCtor || this._NodeListCtor || nl)(a); //设置nodeList._parent = parent;方便在end函数中返回原始nodeList return parent ? nodeList._stash(parent) : nodeList; }; end: function(){//由最近的nl返回父nl if(this._parent){ return this._parent; }else{ return new this._NodeListCtor(0); } },
这就是dojo中NodeList的设计!
query模块暴露的方法无非就是对选择器引擎的调用,下面就比较简单了。
function queryForEngine(engine, NodeList){ var query = function(/*String*/ query, /*String|DOMNode?*/ root){ if(typeof root == "string"){ root = dom.byId(root); if(!root){ return new NodeList([]); } } //使用选择器引擎来查询dom节点 var results = typeof query == "string" ? engine(query, root) : query ? (query.end && query.on) ? query : [query] : []; if(results.end && results.on){//有end和on方法则认为query已经是一个NodeList对象 // already wrapped return results; } return new NodeList(results); }; query.matches = engine.match || function(node, selector, root){ // summary: // Test to see if a node matches a selector return query.filter([node], selector, root).length > 0; }; // the engine provides a filtering function, use it to for matching query.filter = engine.filter || function(nodes, selector, root){ // summary: // Filters an array of nodes. Note that this does not guarantee to return a NodeList, just an array. return query(selector, root).filter(function(node){ return array.indexOf(nodes, node) > -1; }); }; if(typeof engine != "function"){ var search = engine.search; engine = function(selector, root){ // Slick does it backwards (or everyone else does it backwards, probably the latter) return search(root || document, selector); }; } return query; } var query = queryForEngine(defaultEngine, NodeList);
如果您觉得这篇文章对您有帮助,请不吝点击推荐,您的鼓励是我分享的动力!!!