ORACLE分析函数(1)
1. oracle中日期转换为yyyy年mm月dd日的形式
select to_char(sysdate,'"年"mm"月"dd"日"') from dual;
2. oracle分析函数语法
2.1 ORDER BY
select e.last_name, e.manager_id, e.salary, avg(e.salary) over() as emp_count --等同于(select avg(*) from employees) from employees e;
select e.last_name, e.manager_id, e.salary, avg(e.salary) over(order by e.salary asc) as emp_count --按照阶梯取平均数 from employees e;
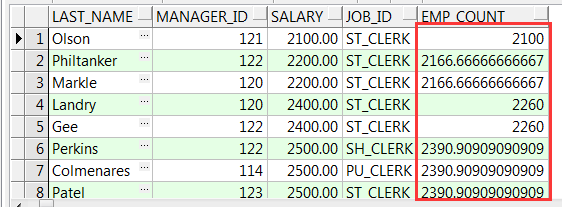
select e.last_name, e.manager_id, e.salary, e.job_id, avg(e.salary) over(partition by e.job_id) as emp_count --取每个工作的工资平均数 from employees e;
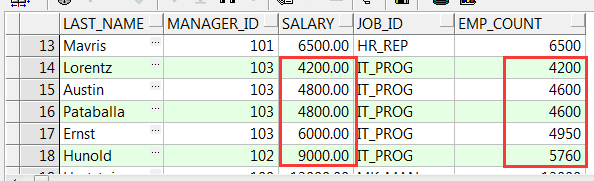
select e.last_name, e.manager_id, e.salary, e.job_id, avg(e.salary) over(partition by e.job_id order by e.salary asc) as emp_count --部门内按照阶梯取工资平均数 from employees e;
2.2 UNBOUNDED PRECEDING
窗口数据从第一行数据开始
2.3 UNBOUNDED FOLLOWING
窗口数据直到最后一行数据
2.4 RANGE
逻辑窗口
count(*) over(order by salary asc range between 1 preceding and 11 following)
假设当前行salary为1000,则当前行的count(*)为满足salary在(1000-1)和(1000+11)之间的数据行
count(*) over(order by salary desc range between 1 preceding and 11 following)
假设当前行salary为1000,则当前行的count(*)为满足salary在(1000-11)和(1000+1)之间的数据行
2.5 ROW
物理窗口
count(*) over(order by salary range between 1 preceding and 11 following)
假设当前行排名为N,则当前行的count(*)为满足排名在(N-1)和(N+11)之间的数据行
2.6 CURRENT ROW
从当前行开始或者以当前行结束
3.常用分析函数
3.1 AVG 平均数
select e.employee_id, e.last_name, e.salary, e.manager_id, avg(e.salary) over(partition by e.manager_id) --相同主管的平均工资 from employees e;
3.2 CORR 求线性关系
select e.last_name, e.hire_date, (sysdate - e.hire_date) hire_days, e.salary, e.job_id, corr(sysdate - e.hire_date, e.salary) over(partition by e.job_id) correlation from employees e order by e.job_id asc;
如果存在线性关系的话correlation不为空,且salary线性等于hire_days * (1 + correlation)
3.3 count
3.4 covar_pop,COVAR_SAMP 协方差
3.5 cume_dist 相对位置
--假设有一个人工资为15500,如下SQL可以查询15500比多少员工的工资高 select cume_dist(15500) within group(order by salary) from employees e; --作为分析函数使用 --查询每个人的工资在相同主管下的大概位置 select e.last_name, e.salary, e.manager_id, cume_dist() over(partition by e.manager_id order by e.salary) from employees e;
3.6 dense_rank 排名可以重复,且不会跳跃。假设数据为10,9,9,8,8;从高到低排名为:1,2,2,3,3
--作为聚合函数使用 --假设有一个人工资为15500,如下SQL可以查询15500的工资排名 select dense_rank(15500) within group(order by salary) from employees e; --作为分析函数使用 --查询每个人的工资在相同主管下的工资排名 select e.last_name, e.salary, e.manager_id, dense_rank() over(partition by e.manager_id order by e.salary) from employees e;
3.7 rank 排名可以重复,会跳跃排序。假设数据为10,9,9,8,8;从高到低排名为:1,2,2,4,4
--作为聚合函数使用 --假设有一个人工资为15500,如下SQL可以查询15500的工资排名 select rank(15500) within group(order by salary) from employees e; --作为分析函数使用 --查询每个人的工资以及工资排名 select e.last_name, e.salary, e.manager_id, rank() over(order by e.salary) from employees e;
3.8 row_number 只能做为分析函数使用
--查询每种工作排名前三的人的姓名及工资 select * from (select e.last_name, e.salary, e.job_id, row_number() over(partition by e.job_id order by e.salary desc) rn from employees e) v where v.rn < 4