java基础【多线程】
一。进程,线程介绍
1.1 进程的由来
在以前,计算机的发明是为了计算数学问题,当时计算机只能接受一些特定的指令,用户输入一个指令,计算机就做一个操作,当用户思考或输入数据的时候,计算机处于等待状态,显然这样子效率很低下。为了解决这一问题,首先出现了批处理,把需要操作的指令提前写下来,然后交给计算器去执行,计算器只需要读取指令就可以进行相应的操作,但这样子还有一个问题:
假如有A,B两个任务,任务A在执行到一半的时候,需要读取大量的数据输入,此时cpu处于等待A输入的待机状态,这样还是浪费了cpu资源,于是人们思考是否可以在A任务输入数据的时候,cpu去执行B任务。当A任务输入完毕以后,B任务暂停,cpu继续处理A任务。
思路已经出现,但还面临一个问题,就是原本计算机内存中只有一个运行程序。而如果既处理任务A,又要处理任务B,必然内存中要装多个数据,那么如何让内存中有多个任务程序呢,任务程序该怎么切换呢?等一系列问题就出现了。
解决方案就是进程,每个进程对应一个程序,每个进程对应一定的内存地址空间,并且进程之间只能使用自己的内存中,各个进程之间互不干扰。进程需要保存了程序每个时刻的运行状态,有了状态这个东西,进程之间的切换才有了可能,比如当进程暂停,相应进程会保存当前进程的状态(进程标识,进程使用的资源)。暂停结束后能回到暂停前的状态
1.2 进程的概念
当一个程序被运行起来之后,这个程序会被加载到内存中,而把内存中这个程序运行期间所占有的内存空间,被称为进程。值得注意,就如同上面所讲,进程为了解决不浪费cpu资源。而可以切换进程去执行,最主要的是因为有了进程状态这个东西。
1.3 线程的由来
进程的出现,解决了操作系统的并发问题,但显然不能满足人们的需求,一个进程在一个时段只能做一件事,如果一个进程有多个任务,只能依次取处理这些任务。比如监控系统,为了呈现监控图像,不仅要与服务器通信去获取图像数据,还有处理与监控者的交互操作。现在监控系统正在获取从服务器传过来的图像数据,还有获取用户在监控系统上的操作。那么监控系统只能等待先接受完数据,后处理操作的策略。一旦服务器传过来很大的图像数据,那么延迟性就很大。显然,这就是弊端
面对这个问题,我们的解决是把获取服务器图像数据,与实施交互操作 分为两个子任务,在获取图像数据时,执行相应子任务。一旦监控者实施了交互,立刻暂停获取图像数据,去处理交互操作。操作完成之后,继续获取图像数据。这就是线程,每个线程对应一个子任务。一个进程(监控系统),有多个线程(获取数据,交互操作)。由进程来分配让哪些线程来得到cpu资源。
1.4 线程的概念
在进程中负责执行某一任务(任务代表一个独立代码单元)
1.5 多线程
在一个进程中可以有多个线程,多个线程同时运行,同时执行任务。并且这些线程共享进程空间与资源。具体执行要交给cpu来处理。讨论多线程的时候,讨论的前提是对单核cpu,双核cpu等 的划分。
单核cpu:
真正一个程序在运行的过程中,某一时刻,某个时间点上,cpu只能处理一个线程任务
cpu在这些独立的运行单元(线程)之间,做着高速切换,快到我们感觉不到(纳秒为单位),所以我们认为是在同时进行。
多线程的缺点:
在合理的cpu使用范围内,可以提高效率,如果线程开的过多,就会降低效率
【小结】
1。进程让操作系统的并发性成为可能,而线程让进程内部的并发成为可能。
2。java采用单线程编程模型,意味着如果我们不主动创建线程,那么始终只有一个线程,该线程也叫做主线程
【注意】:这里所谓的只有一个线程是说jvm本身是一个进程,为main方法开启一个线程,所以main方法始终只有一个线程,除非你开启了线程,并不是说jvm只创建了main一个线程,因为还有垃圾回收线程,等等其他线程。
二。创建线程
线程是要和操作系统交互的,而我们的java程序运行在虚拟机中。当我们需要使用多线程技术时,要运行的多线程代码交给jvm,如何jvm知道哪些代码是多线程呢?有以下两种方式告知jvm
方式一:继承Thread类
Thread类定义:
public class Thread implements Runnable { private Runnable target; @Override public void run() { if (target != null) { target.run(); } } }
方式二:实现Runnable接口
Runnable接口定义:
public interface Runnable { public abstract void run(); }
无论哪种方式,只有start()方法会开启线程
if (threadStatus != 0) throw new IllegalThreadStateException(); /* Notify the group that this thread is about to be started * so that it can be added to the group's list of threads * and the group's unstarted count can be decremented. */ group.add(this); boolean started = false; try { start0(); //调用了native方法,显然开启线程是与操作系统进行交互, started = true; } finally { try { if (!started) { group.threadStartFailed(this); } } catch (Throwable ignore) { /* do nothing. If start0 threw a Throwable then it will be passed up the call stack */ } }
start()与run()的解释
当我们启动jvm之前,jvm会首先给我们程序中的线程在栈中分配各自独立的内存空间,当我们调用main方法的时候,首先方法栈会把class对象加载进内存,然后为main方法开启运行栈区域,把main方法中调用的方法进行压栈,当这个主线程执行到了start()方法时,就开启线程,把具体run方法中的代码也交给cpu执行,具体执行什么,由cpu自己选择。当然主线程执行完毕后,并不会影响其他线程的运行。而直接调用run(),实际是把run压入主线程栈。主线程会执行run方法,执行完毕后把run方法弹出,并不会开启线程,而是由主线程自己执行run方法。
两种创建线程方式的讨论
我听到过一种概念,描述的很好,Runnbale可以理解为"任务",Thread可以理解"线程对象"。我们所创建的是线程对象,线程对象不仅包括了线程要执行的任务,也包括了线程的状态(名称,标识符,等一些东西,很好的体现了面向对象的思想),只有“任务”,没有任何用,你需要把"任务"交给线程对象,由线程对象专业的native方法去与操作系统打交道。告诉操作系统,我开启了一个线程,给我有机会执行下。
三。创建进程
方式一:Runtime.exec()
方式二:ProcessBuilder的start方法
目前没有涉及到,不做详细解释,以后会补充,先了解就好
四。详解Thread类
在讨论Thread类之前,看下线程的五种状态
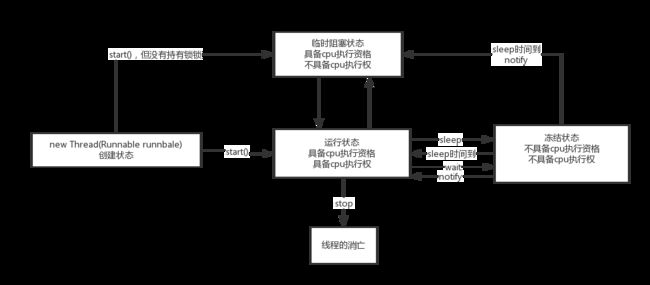
Thread类中的方法
(1)sleep方法
调用sleep让运行状态线程变成冻结状态,注意,sleep方法不会释放锁,如果当前线程持有对象锁,其他对象无法访问这个对象
(2)yield方法
调用yield方法会让运行状态线程交出cpu权限变成阻塞状态,让cpu去执行其他的线程,他跟sleep方法类似,同样不会释放锁,
(3)join方法
调用join方法会让当前调用方法的线程执行,该方法有三种重载形式,参数可以输入时间,意思是调用方法的线程执行多少毫秒。
(4)interrupt方法
调用interrupt方法可是使处于阻塞状态的线程抛出一个异常,中断一个处于阻塞状态的线程,与isInterrupted()方法组合,可以中断运行中的线程
五。ThreadLocal
ThreadLocal为变量在每个线程中都创建了一个副本,每个线程可以访问自己内部的副本变量
5.1 为什么要使用ThreadLocal?
这个问题很关键,Struts2中的数据中心,Hibernate中的Session,他们底层原理都是使用了线程局部变量,这个问题放到最后来思考,先看看线程局部变量是什么?
5.2 什么是ThreadLocal?
ThreadLocal译为线程局部变量,我们都知道多个线程共享进程的空间,线程之间是独立的单元,所谓的多线程安全问题就是多线程操作共享数据时出现的问题,这个问题先不谈,既然有共享,那么肯定也有属于自己的数据。这就是ThreadLocal(线程局部变量)。
5.3 ThreadLocal与Thread之间的关系
ThreadLocal是线程局部变量,Thread类是描述线程的信息。那么肯定Thread类中应该有ThreadLocal的引用,于是我在Thread类中找到了如下的代码。
/* ThreadLocal values pertaining to this thread. This map is maintained * by the ThreadLocal class. 翻译:线程局部变量的值依附于一个线程,这个线程局部变量的值(Map)被保持在ThreadLocal.class中。
由此注释可知:
1.线程局部变量是一个Map
2.线程局部变量在ThreadLocal中
*/ ThreadLocal.ThreadLocalMap threadLocals = null;
5.4 ThreadLocal类定义
public class ThreadLocal<T> {
static class ThreadLocalMap { static class Entry extends WeakReference<ThreadLocal> { /** The value associated with this ThreadLocal. */ Object value; Entry(ThreadLocal k, Object v) { super(k); value = v; } } }
可以看到,在ThreadLocal中,有一个叫做ThreadLocalMap的内部类,它就是存储线程局部变量的地方。Map的key是ThreadLocal,Map的value就是线程局部变量值的副本。为什么key是ThreadLocal变量?因为一个线程可以有多个线程局部变量.
WeakReference表示弱引用,表示当垃圾回收器线程扫描它所管辖的内存区域时,一旦发现了弱引用对象,不管内存空间够不够,都会回收。但垃圾回收器的优先级很低。因此不一定会很快发现那些弱引用对象。
WeakReference只有两个构造方法,其中都是把原本的引用变为弱引用。那么显然,ThreadLocalMap的Key就是一个弱引用。
由此引发了一个传言,ThreadLocal会引发内存泄露,问题描述是这样:如果一个ThreadLocal没有外部强引用引用它,那么系统gc(垃圾回收)的时候,这个ThreadLocal会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value了,如果当前线程迟迟不结束,这些key为null的Entry的value就会一直存在一个强引用链
实际上,在JDK的ThreadLocalMap的设计中已经考虑这个问题了,在ThreadLocalMap的getEntry函数中,首先从ThreadLocal的直接索引位置获取Entry entry对象,如果entry不为null,并且key相同,那么就返回entry。如果entry为null,或者key不一致则向下一个位置查询,如果下一个位置的key和当前需要查询的key相等,则返回相应的entry。在这个过程中遇到的key为null的Entry都会被擦除,所以不必担心内存泄露的问题。
5.5 对ThreadLocal类的操作
public class ThreadLocal<T>{ static class ThreadLocalMap{} public T get() { Thread t = Thread.currentThread(); //获取当前线程 ThreadLocalMap map = getMap(t); if (map != null) { //如果map有值,把当前调用该方法的ThreadLocal实例传进去 ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) return (T)e.value; } //如果map没有值,就进行初始化 return setInitialValue(); } /* 获取线程中的线程局部变量中的Map */ ThreadLocalMap getMap(Thread t) { return t.threadLocals; } /* 对线程局部变量进行初始化 */ private T setInitialValue() { T value = initialValue(); //返回值为null Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); return value; } /* 对线程局部变量进行赋值 */ public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); } protected T initialValue() { return null; }
上述ThreadLocal中的方法,就是对内部ThreadLocalMap(真正的线程局部变量)的操作。
其中最后一个initialValue()方法,返回一个null。该方法调用ThreadLocal对象的get()方法时,如果没有线程局部对象的value值,才会执行。值得注意的是该函数用了protected类型。显然建议子类重写该函数。所以通常该函数都会以匿名内部类的形式被重载,如下所用:
ThreadLocal<String> value=new ThreadLocal<String>(){ @Override protected String initialValue(){ return "默认值" } };
5.6 线程局部变量操作流程
1.在当前线程new ThreadLocal().set(value)的时候,会先获取当前线程,从当前线程(Thread)中拿到属性threadLocals,该属性的类型是ThreadLocal的内部类ThreadLocalMap类型,也就是线程局部变量真正的地址
2.判断线程局部变量存不存在,如果不存在,就创建一个Map,key为当前调用set()方法的ThreadLocal,value就是线程局部变量的副本。如果存在则直接赋值
3.创建Map的原理就是new ThreadLocalMap(ThreadLocal tl,Object value).