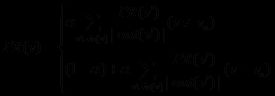推荐系统读书笔记(二)利用用户行为数据
2.1 用户行为数据简介
显性反馈行为:用户明确表示对物品喜好的行为。评分、喜欢、不喜欢。
隐性反馈行为:不能明确反应用户喜好的行为。比如页面浏览。
| 显性反馈数据 | 隐性反馈数据 | |
| 用户兴趣 | 明确 | 不明确 |
| 数量 | 较少 | 庞大 |
| 存储 | 数据库 | 分布式文件系统 |
| 实时读取 | 实时 | 有延迟 |
| 正负反馈 | 都有 | 只有正反馈 |
正反馈:用户的行为倾向于指用户喜欢的物品。
负反馈:用户的行为货币于用户不喜欢的物品。
用户行为的统一表示:
| user_id | 产生行为的用户的唯一标识 |
| item_id | 产生行为的对象的唯一标识 |
| behavior_type | 行为的种类(购买/浏览) |
| context | 产生行为的上下文,包括时间和地点等 |
| behavior weight | 行为的权重 |
| behavior content | 行为的内容 |
无上下文信息的隐性反馈数据集:每一条行为记录仅仅包含用户ID和物品ID,如Book-Crossing数据集
无上下文信息的显性反馈数据集:每一条记录包含用户ID、物品ID和用户对物品的评分
有上下文信息的隐性反馈数据集:每一条记录包含用户ID、物品ID和用户对物品产生行为的时间戳,如Last.fm数据集
有上下文信息的显性反馈数据集:每一条记录包含用户ID、物品ID、用户对物品的评分和评分行为发生的时间戳,如Netflix。
2.2 用户行为分析
2.2.1 用户活跃度和物品流度的分布
长尾分布:Power Law
令fu(k)为对k个物品产生过行为的用户数,令fi(k)为被k个用户产生过行为的物品数,那么fu(k)和fi(k)都满足长尾分布。
fi(k)=αikβi
fu(k)=αukβu
2.2.2 用户活跃度与物品流行度的关系
新用户倾向于浏览热门的物品,因为他们对网站还不熟悉,只能点击首页的热门物品。
仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法,有基于邻域的方法、隐语义模型、基于图的随机游走算法等。基于邻域的方法主要包含下面两种算法:
基于用户的协同过滤算法:这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。
基于物品的协同过滤算法:这种算法给用户推荐和他之前喜欢的物品相似的物品。
2.3 实验设计和算法评测
2.3.1 数据集
2.3.2 实验设计
首先,将用户行为数据集按照均匀分布随机分成M份,挑选一份作为测试集,将剩下的M-1份作为训练集。然后在训练集上建立用户兴趣模型,并在测试集上对用户行为进行预测,统计出相应的评测指标。为了保证评测指标并不是过拟合的结果,需要进行M次实验,并且每次都使用不同的测试集。然后将M次实验测出的评测指标的平均值作为最终的评测指标。
2.3.3 评测指标
对用户u推荐N个物品,令用户在测试集上喜欢的物品集合为T(u),然后可以通过准确率/召回率评测推荐算法的精度:
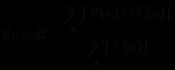
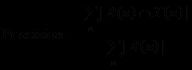
召回率描述有多少比例的用户-物品评分记录包含在最终的推荐列表中,而准确率描述最终的推荐列表中有多少比例是发生过的用户-物品评分记录。
覆盖率:反映了推荐算法发掘长尾的能力,覆盖率越高,说明推荐算法越能够将长尾中的物品推荐给用户。
![]()
该覆盖率表示最终的推荐列表中包含多大比例的物品。如果所有的物品都被推荐给至少一个用户,那么覆盖率就是100%。
新颖度:用推荐列表中物品的平均流行度度量推荐结果的新颖度。如果推荐出的物品都很热门,说明推荐的新颖度较低,否则说明推荐结果比较新颖。
此时,在计算平均流行度时对每个物品的流行度取对数,这是因为物品的流行度分布满足长尾分布,在取对数后,流行度的平均值更加稳定。
2.4 基于邻域的算法
2.4.1 基于用户的协同过滤算法
1.基础算法
基于用户的协同过滤算法主要包括两个步骤:
(1)找到和目标用户兴趣相似的用户集合
(2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
计算两个用户的兴趣相似度:给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的物品集合,令N(v)为用户曾经有过正反馈的物品集合。那么可以通过如下的Jaccard公式/余弦相似度简单地计算u和v的兴趣相似度:
![]()
![]()
例:
用户A a b d
用户B a c
用户C b e
用户D c d e
我们可以计算出用户A和用户C、D的相似度
WAC=1/sqrt(6)
WAD=1/3
这种方法很耗时,因为很多用户之间并没有对同样的物品产生过行为,可先找出与同样物品有过行为的用户对,再来计算。
为此,可以首先建立物品到用户的倒排表,对于每个物品都保存对该物品产生过行为的用户列表。
a 用户A 用户B
b 用户A 用户C
c 用户B 用户D
d 用户A 用户D
e 用户C 用户D
然后建立4*4的用户相似度矩阵W,对于物品a,将W[A][B]和W[B][A]加1。这里的W是余弦相似度的分子部分,然后将W除以分母可以得到最终的用户兴趣相似度
| A | B | C | D | |
| A | 0 | 1 | 1 | 1 |
| B | 1 | 0 | 0 | 1 |
| C | 1 | 0 | 0 | 1 |
| D | 1 | 1 | 1 | 0 |
得到用户之间的兴趣相似度后,UserCF算法会给用户推荐和他兴趣最相似的K个用户喜欢的物品。如下公式度量了算法中用户u对物品i的感兴趣程度。
![]()
其中,S(u,K)包含和用户u兴趣最接近的K个用户,N(i)是对物品i有过行为的用户集合,wuv是用户u和用户v的兴趣相似度,rvi代表用户v对物品i的兴趣,因为使用的是单一行为的隐反馈数据,所以所有的rvi=1
UserCF只有一个重要参数K,即为每个用户选出K个和他兴趣最相似的用户,然后推荐K个用户感兴趣的物品。K的调整对推荐算法的各种指标都会产生一定的影响。
准确率和召回率:精度指标(准确率和召回率)并不和参数K成线性关系。在该数据集中,通过离线实验得知K=80有较高的准确率和召回率。因此选择合适的K对于获得高的推荐系统精度比较重要。推荐结果的精度对K也不是特别敏感,只要在一定的区域内,就可以获得不错的精度。
流行度:K越大则推荐结果就越热门,K决定了做推荐时参考多少和你兴趣相似的其他用户的兴趣,如果K越大,参考的人越多,结果就越来越趋近于全局热门的物品。
覆盖率:K越大更倾向于热门,覆盖率自然就低。
2.用户相似度计算的改进
例:如果两个用户都曾经买过《新华字典》那么不能说明他们兴趣相似,因为绝大多数中国人小时候都买过《新华字典》,但如果两个用户都买过《数据挖掘导论》,那么可以认为他们的兴趣比较相似。
两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度。

该公式log惩罚了用户u和用户v共同兴趣列表中热门物品对他们相似度的影响。
3.实际在线系统使用UserCF的例子
并不多,有Digg。效果如下:
(1)用户反馈增加:40%
(2)平均每个用户将从34个具有相似兴趣的好友那儿获得200条推荐结果
(3)用户和好友的交互活跃度增加了24%
(4)用户评论增加了11%
2.4.2 基于物品的协同过滤算法
是目前业界应用最多的算法,亚马逊、Netflix、Hulu、YouTube的推荐算法基础都是该算法。
1.基础算法
UserCF算法有一些缺点:
(1)随着用户数目增大,计算用户相似兴趣矩阵将越来越困难,其运算时间复杂度和空间复杂度的增长和用户数的增长近似于平方关系。
(2)基于用户的协同过滤很难对推荐结果作出解释。
ItemCF给用户推荐那些和他们之前喜欢的物品相似的物品。不过ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。
基于物品的协同过滤算法主要分为两步:
(1)计算物品之间的相似度
(2)根据物品的相似度和用户的历史行为给用户生成推荐列表
![]()
|N(i)|是喜欢物品i的用户数,分子是同时喜欢物品i和j的用户数。上述公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢物品j。
上述公式存在问题:如果物品j热门,很多人都喜欢,那么wij会接近于1,该公式会造成任何物品都会和热门物品有很大的相似度,这对于致力于挖掘长尾信息的推荐系统来说显然不是一个好的特性。为了避免推荐热门物品,改为以下公式:
![]()
该公式惩罚了物品j的权重,因此减轻了热门物品会和很多物品相似的可能性。
上面定义可以看出,两个物品产生相似度是因为它们共同被很多用户喜欢,也就是说每个用户都可以通过他们的历史兴趣列表给物品“贡献”相似度。这里面蕴涵着一个假设,就是每个用户的兴趣都局限在某几个方面,因此如果两个物品属于一个用户的兴趣列表,那么这两个物品可能就属于有限的几个领域,而如果两个物品属于很多用户的兴趣列表,那么它们就可能属于同一个领域,因此有很大的相似度。
例:
a,b,d
b,c,e
c,d
b,c,d
a,d
| a | b | c | d | e | |
| a | 1 | 2 | |||
| b | 1 | 2 | 2 | 1 | |
| c | 2 | 2 | 1 | ||
| d | 2 | 2 | 2 | ||
| e | 1 | 1 |
以上矩阵记录了同时喜欢物品i和物品j的用户数,最后将它归一化可以得到物品之间的余弦相似度矩阵W。
得到物品之间的相似度后,ItemCF使用如下公式计算用户u对一个物品j的兴趣:
![]()
这里N(u)是用户喜欢的物品的集合,S(j,K)是和物品最相似的K个物品的集合,wji是物品j和i的相似度,rui是用户u对物品i的兴趣。
该公式的含义是,和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
实验结果解读:
(1)精度(召回率和准确率):精度与K不是正相关也不是负相关,选择合适的K对获得最高的精度是重要的。
(2)流行度:K对流行度的影响也不是完全正相关的。随着K增加,流行度会逐渐提高,但当K增加到一定程度,流行度就不会再有明显变化。
(3)覆盖率:K增加会降低系统的覆盖率。
2.用户活跃度对物品相似度的影响
IUF:用户活跃度对数的倒数的参数,他也认为活跃用户对物品相似度的贡献应该小于不活跃的用户,他提出应该增加IUF的参数来修正物品相似度的计算公式。

ItemCF-IUF比起ItemCF,精度提高,覆盖率提高,流行度降低。
3.物品相似度的归一化
如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率、还可以提高推荐的覆盖率和多样性。
假设物品有两类:A和B,A类物品之间的相似度为0.5,B类物品之间的相似度为0.6,A类与B类的相似度为0.2。在这种情况下,如果一个用户喜欢5个A类和5个B类物品,用ItemCF给他进行推荐,推荐的就都是B类,因为B类物品之间的相似度大。如果归一化后,A类的物品之间的相似度为1,B类物品之间的相似度也为1,在这种情况下,用户的推荐列表中A类和B类物品的数目大致是相等的。从这个例子可以看同,相似度的归一化可以提高推荐的多样性。
一般来说,热门的类其类内物品相似度一般比较大,如果不进行归一化,就会推荐比较热门的类里面的物品,而这些物品也是比较热门的。因此,推荐的覆盖率就比较低。相反,如果进行相似度的归一化,则可以提高推荐系统的覆盖率。
2.4.3 UserCF和ItemCF的综合比较
UserCF:GroupLens,Digg
ItemCF:亚马逊,Netflix
UserCF:给用户推荐和他有共同兴趣爱好的用户喜欢的物品,推荐结果着重于反映和用户兴趣相似的小群体的热点。更社会化,反映用户所在的小型兴趣群体中物品的热门程度。
ItemCF:给用户推荐那些和他之前喜欢的物品类似的商品,推荐结果着重于维系用户的历史兴趣。更加个性化,反映了用户自己的兴趣传承。
| UserCF | ItemCF | |
| 性能 | 适用于用户较少的场合,如果用户很多,计算用户相似度矩阵代价很大 | 适用于物品数明显小于用户数的场合,如果物品很多(网页),计算物品相似度矩阵代价很大 |
| 领域 | 时效性较强,用户个性化兴趣不太明显的领域 | 长尾物品丰富,用户个性化需求强烈的领域 |
| 实时性 | 用户有新行为,不一定造成推荐结果的立即变化 | 用户有新行为,一定会导致推荐结果的实时变化 |
| 冷启动 | 在新用户对很少的物品产生行为后,不能立即对他进行个性化推荐,因为用户相似度表是每隔一段时间离线计算的。 新物品上线后一段时间,一旦有用户对物品产生行为,就可以将新物品推荐给和对它产生行为的用户兴趣相似的其他用户。 |
新用户只要对一个物品产生行为,就可以给他推荐和该物品相关的其他物品 但没有办法在不离线更新物品相似度的情况下将新物品推荐给用户 |
| 推荐理由 | 很难提供令用户信服的推荐解释 | 利用用户的历史行为给用户做推荐解释,可以令用户比较信服 |
ItemCF和UserCF覆盖率和新颖度都不高,可以采用如下公式:
![]()
a的取值在0.5到1间,通过提高a,可以惩罚热门的j。
a为0.5才会导致最高的准确率和召回率,a越大,覆盖率越高,结果的平均热门程度会降低。通过这种方法可以在适当牺牲准确率和召回率的情况下显著提升结果的覆盖率和新颖性(降低流行度即提高了新颖性)。
2.5 隐语义模型
2.5.1 基础算法
隐语义模型的核心思想是通过隐含特征联系用户兴趣和物品。
隐含语义分析技术因为采取基于用户行为统计的自动聚类,较好的解决了5个问题:
(1)隐含语义分析技术的分类来自于对用户行为的统计,代表了用户对物品分类的看法。隐含语义分析技术和ItemCF在物品分类方面的思想类似,如果两个物品被很多用户同时喜欢,那么这两个物品就很有可能属于同一个类。
(2)隐含语义分析技术允许我们指定最终有多少个分类,这个数字越大,分类的粒度就越细,反之分类粒度就越粗。
(3)隐含语义分析技术会计算出物品属于每个类的权重,因此每个物品都不是硬性地分到某一个类中。
(4)隐含语义分析技术给出的每个分类都不是同一个维度的、它是基于用户的共同兴趣计算出来的,如果用户的共同兴趣是某一个维度,那么LFM给出的类也是相同的维度。
(5)隐含语义分析技术可以通过统计用户行为决定物品在每个类中的权重,如果喜欢某个类的用户都会喜欢某个物品,那么这个物品在这个类中的权重就可能比较高。
隐含语义分析技术有很多著名的模型和方法,有pLSA、LDA、隐含类别模型、隐含主题模型、矩阵分解。
LFM通过以下公式计算用户u对物品i的兴趣:
![]()
pu,k度量了用户u的兴趣和第k个隐类的关系,而qi,k度量了第k个隐类和物品i之间的关系。
推荐系统有显性反馈和隐性反馈。LFM在显性反馈数据(评分数据)上解决评分预测问题并达到了很好的精度。本章讨论隐性反馈数据集,只有正样本,没有负样本。
因此,在隐性反馈数据集上应用LFM解决TopN推荐的第一个关键问题就是如何给每个用户生成负样本。
Rong Pan有如下几种方法:
(1)对于一个用户,用他所有没有过行为的物品作为负样本
(2)对于一个用户,从他没有过行为的物品中均匀采样出一些物品作为负样本
(3)对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,保证每个用户的正负样本数目相当。
(4)对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,偏重采样不热门的物品。
3>2>4>1
2011年的Yahoo推荐系统比赛,我们发现对负样本采样时应该遵循以下原则:
(1)对每个用户,要保证正负样本的平衡
(2)对每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品
采样完后,需要优化如下的损失函数来找到最合适的参数p和q

最右两个表达式用于防止过拟合的正则化项。λ通过实验获得,要最小化上面的损失函数,可以利用一种称为随机梯度下降法的算法。该算法是最优化理论里最基础的优化算法,它首 先通过求参数的偏导数找到最速下降方向,然后通过迭代法不断地优化参数。
推导过程略,得出如下递推公式:
![]()
![]()
其中,α是学习速率,需要通过反复实验获得。
其次,通过实验对比了LFM在TopN推荐中的性能,重要参数有4个:
(1)隐特征的个数F
(2)学习速率alpha
(3)正则化参数lambda
(4)负样本/正样本比例ratio
LFM在所有指标上都优于UserCF与ItemCF,当数据集非常稀疏时,LFM性能会明显下降,甚至不如UserCF和ItemCF。
2.5.2 基于LFM的实际系统的例子
雅虎的研究人员以CTR作为优化目标,利用LFM来预测用户是否会单击一个链接。为此,他们将用户历史上对首页上链接的行为记录作为训练集。如果用户u单击过链接i,那么定义为正样本,如果展示给用户u,但用户u从来没有单击过,就定为负样本。
LFM很难实现实时的推荐。每次训练时都需要扫描所有用户行为记录,才能计算出用户隐类向量和物品隐类向量。而且LFM的训练需要在用户行为记录上反复迭代才能获得比较好的性能。
LFM每次训练很耗时,一般在实际应用中只能每天训练一次,并且计算出所有用户的推荐结果。
LFM模型不能因为用户行为的变化实时调整推荐结果来满足用户最近的行为。
为了解决传统LFM不能实时化,而产品需要实时性的矛盾,雅虎的研究生员提出了一个解决方案。
首先,利用新闻链接的内容属性(关键词、类别等)得到链接i的内容特征向量yi。
其次,它们会实时收集用户对链接的行为,并且用这些数据得到链接i的隐特征向量qi,然后利用以下公式预测用户是否会单击链接
![]()
其中,yi是根据物品的内容属性直接生成的,xuk是用户u对内容特征k的兴趣程度,用户向量xu可以根据历史行为记录获得,而且每天只需要计算一次。而pu、qi是根据实时拿到的用户最近几小时的行为训练 LFM获得的。因此,对于一个新加入的物品i,可以通过前一个表达式估计用户u对物品i的兴趣,然后经过几小时后,可以通过后一个表达式得到更加准确的预测值。
2.5.3 LFM和基于领域的方法的比较
理论基础:LFM有学习方法,通过优化一个设定的指标建立最优的模型。基于领域的方法是一种基于统计的方法,没有学习过程。
离线计算的空间复杂度:基于邻域的方法需要维护一张离线的相关表。LFM在建模过程中,当M和N很大时可以节省离线计算的内存。如果用户数很庞大,很少有人用UserCF,LFM由于节省内存,成为Netflix Prize中最流行的算法。
离线计算的时间复杂度:一般情况下,LFM的时间复杂度要稍微高于UserCF和ItemCF,主要是因为算法需要很多次迭代。
在线实时推荐:UserCF和ItemCF可以实时预测。LFM不太适合用于物品数据非常庞大的系统,如果要用,也需要一个比较快的算法给用户先主垍 个比较小的候选列表,然后再重新排名。LFM不能进行实时推荐。
推荐解释:ItemCF可解释,LFM无法提供解释。
2.6 基于图的模型
2.6.1 用户行为数据的二分图表示
令G(V,E)表示用户物品二分图,其中VU用户顶点集合,VI物品顶点集合。
2.6.2 基于图的推荐算法
给用户u推荐物品的任务就可以转化为度量用户顶点与没有直接相连的物品节点在图上的相关性。
度量顶点相关性的方法:
(1)两个顶点之间的路径数
(2)两个顶点之间路径的长度
(3)两个顶点之间的路径经过的顶点
而相关性高的一对顶点一般具有如下特征:
(1)两个顶点之间有很多路径相连
(2)连接两个顶点之间的路径长度都比较短
(3)连接两个顶点之间的路径不会经过出度比较大的顶点
PersonalRank:假设要给用户u进行个性化推荐,可以从用户u对应的节点vu开始在用户物品二分图上进行随机游走。游走到任何一个节点时,首先按照概率alpha决定是继续游走,还是停止这次游走并从vu节点开始重新游走。如果决定继续游走,那么就从当前节点指向的节点中按照均匀分布随机选择一个节点作为游走下次经过的节点。这样,经过很多次随机游走后,每个物品节点被访问到的概率会收敛到一个数。最终的推荐列表中物品的权重就是物品节点的访问概率。