在windows上建立hadoop+eclipse开发环境
2013-03-07
版本要求:jdk1.6(及以上),hadoop0.20.2(此后的版本会出现datanode无法启动的问题),eclipse3.3(此后的版本可能与插件不兼容)
1、安装Cygwin(参考“在Windows上安装Hadoop教程”)
从http://www.cygwin.com/setup.exe下载安装文件,运行安装。
弹出Cygwin Net Release Setup Program,在download source页面选择Install from Internet
下一步选择Cygwin的安装目录为“E:\cygwin”,Install For选择“All Users”,Default Text File Type选择“Unix/binary”
下一步设置Cygwin安装包的存放目录
下一步设置“Internet Connection”的方式,选“Direct Connection”
下一步选“Download site”,选163的即可(网上很多http://www.cygwin.cn/pub/,本人不推荐,经常出错)
在“Select Package”对话框中,必须保证“Net Category”下的“OpenSSL”被安装

如果打算在eclipse上编译Hadoop,必须安装“Base Category”下的“sed”:
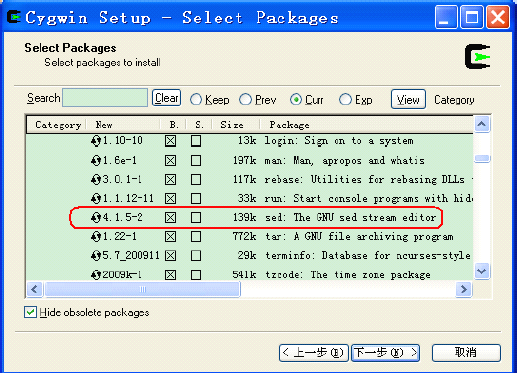
另外建议将“Editor Category”下的vim安装;“Devel Category”下的subversion。
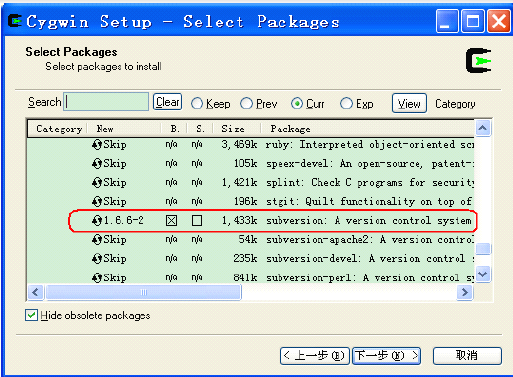
当完成上述操作后,点击“Select Packages”对话框中“下一步”,进入Cygwin 安装包
下载过程。
等待安装包下载完毕,当下载完后。
2、安装JDK
最好1.6版本,配置环境变量。
3、配置环境变量
需要配置的环境变量包括classpath,JAVA_HOME和PATH:JAVA_HOME 指向JRE 安装目录;JDK的bin 目录,Cygwin 的bin 目录,以及Cygwin 的bin 目录都必须添加到PATH 环境变量中,如下图所示:
![]() 图1 (配置classpath: .;C:\Java\jdk1.6.0_11\lib)
图1 (配置classpath: .;C:\Java\jdk1.6.0_11\lib)
 图二
图二
配置JAVA_HOME:C:\Java\jre6
配置PATH:C:\Java\jdk1.6.0_11\bin;E:\cygwin\bin;
4、安装sshd服务(图片均见“在Windows上安装Hadoop教程”)
启动Cygwin,执行ssh-host-config命令,在出现
“Should privilege separation be used?<yes/no>”时输入no。
如果出现“Have fun”时,一般表示sshd服务安装成功。(见下图)
在本机服务管理器中启动GYGWIN sshd
5、配置ssh登录
执行ssh-keygen命令生成密钥文件,一路回车即可。然后生成authorized_keys文件:
cd ~/.ssh/
cp id_rsa.pub authorized_keys
exit
退出cygwin窗口,重新打开,执行ssh localhost,在出现“Are you sure you wangt to continue connecting <yes/no>? 时输入yes
检测是否配置成功:
6、安装hadoop
将安装包hadoop-0.20.2.tar.gz解压到d:\hadoop目录下,修改conf目录下的配置文件:
修改hadoop-env.sh:export JAVA_HOME=/cygdrive/c/Java/jre6
修改core-site.xml:将src\core目录下的core-default.xml的内容全部复制到core-site.xml中代替原先内容,修改fs.default.name的值为:hdfs://localhost:9000
( <name>fs.default.name</name>
<value>hdfs://localhost:9000</value>)
修改hdfs-site.xml:将src\hdfs下的hdfs-default.xml文件内容全部复制到hdfs-site.xml中
修改mapred-site.xml配置,将src\mapred目录下的mapred-default.xml文件内容复制到mapred-site.xml中,修改mapred.job.tracker值为:localhost:9001
( <name>mapred.job.tracker</name>
<value>localhost:9001</value>)
7、启动hadoop:
$ cd /cygdrive/e/hadoop1
注意;如果出现Bad connection to FS. command aborted.
解决方法:
先删除tmp文件夹
格式化namenode:hadoop namenode -format
重新启动start-all.sh,输入jps
$ jps
5384 JobTracker
3052 NameNode
4432 Jps
如果NameNode没有启动,需要停掉hadoop(bin/stop-all.sh),重新格式化NameNode。
停止所有服务stop-all.sh
在Cygwin 中,进入hadoop 的bin 目录,运行./start-all.sh 启动hadoop,在启动成功之后,
可以执行./hadoop fs -ls /命令,查看hadoop 的根目录,
8、安装eclipse插件
hadoop0.20.2版本自带的hadoop-0.20.2-eclipse-plugin.jar包不行,换成下面的:下载地址:https://issues.apache.org/jira/secure/attachment/12460491/hadoop-eclipse-plugin-0.20.3-SNAPSHOT.jar,拷贝到eclipse的plugins目录下,重启eclipse,在在Window-》Open Perspective-》other,弹出的窗口中应该有一项Map/Reduce项,代表安装成功了。

9、eclipse配置环境
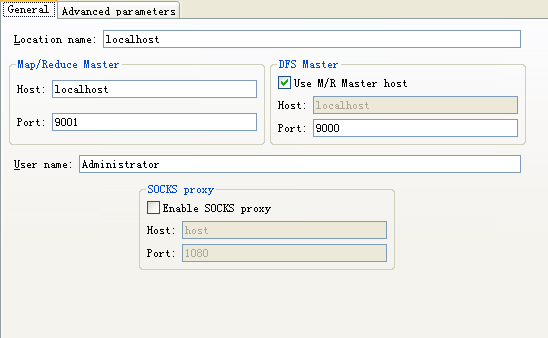
启动eclipse,转到Map/Reduce Perspective,在上图的Map/Reduce Locations里,新建一个Location,填入以下值
10、上传文件到HDFS
打开一个cygwin,执行
cd hadoop-0.20.2
bin/hadoop fs -mkdir In
bin/hadoop fs -put README.txt In
这时,在eclipse的Project explorer的DFS location中,应该能反应变化,没有的话,reconnect一下

11、测试mapreduce项目
新建一个mapreduce项目,将D:\hadoop\hadoop-0.20.2\src\examples下的org文件夹拖到项目的src下。

在WordCount.java上右键——Run as——Run Configurations,添加一个Java Application,编辑Arguments,添加源文件目录及目标目录(可不存在)

运行
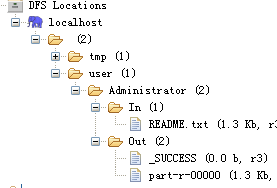
产生结果存放在Out目录下。
如果出现下面错误:
wordcount java.lang.OutOfMemoryError: Java heap space
是因为文件太大造成JVM内存溢出,可以在Run Configurations的Arguments中VM arguments中设置为-Xmx800m。如果还是不行,只能删掉部分处理的文件或换成小文件
下次运行时会出现Out目录已存在的错误,删掉Out目录或者修改参数中的输出目录。
运行时出错(纠结了好久呢……)
windows hadoop HDFS Failed to set permissions of path
security.UserGroupInformation: PriviledgedActionException as:Administrator cause:java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator343777043\.staging to 0700 02.java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator343777043\.staging to 0700 03. at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:682) 04. at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:655) 05. at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:509) 06. at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:344) 07. at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:189) 08. at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:116) 09. at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:856) 10. at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:850) 11. at java.security.AccessController.doPrivileged(Native Method) 12. at javax.security.auth.Subject.doAs(Unknown Source) 13. at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1093) 14. at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:850) 15. at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:824) 16. at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1261)
解决方法:
修改/hadoop-1.0.2/src/core/org/apache/hadoop/fs/FileUtil.java里面的checkReturnValue,注释掉即可(有些粗暴,在linux下,可以不用检查):
......private static void checkReturnValue(booleanrv,Filep,FsPermissionpermission)throwsIOException{/** if (!rv) { throw new IOException("Failed to set permissions of path: " + p + " to " + String.format("%04o", permission.toShort())); } **/}......
重新编译打包hadoop-core-1.0.3.jar,替换掉hadoop-1.0.3根目录下的hadoop-core-1.0.3.jar即可。
这里提供一份修改版的hadoop-core-1.0.3-modified.jar文件,替换原hadoop-core-1.0.3.jar即可。(注文件放在hadoop软件下了)
替换之后,刷新项目,设置好正确的jar包依赖,现在再运行WordCountTest,即可。
成功之后,在Eclipse下刷新HDFS目录,可以看到生成了out目录:
参考:
http://stackoverflow.com/questions/10509427/haddop-in-windows
运行结果

参考《hadoop开发者》第一期的“在Windows上安装Hadoop教程”(注:百度文库里有)