MariaDB集群Galera Cluster的探索
Galera Cluster是MariaDB的一个双活多主集群,其可以使得MariDB的所有节点保持同步,Galera为MariaDB提供了同步复制(相对于原生的异步复制),因此其可以保证HA,且其当前仅支持XtraDB/InnoDB存储引擎(扩展支持MyISAM),并且只可在Linux下使用。
Galera Cluster拥有以下特性:
· 真正的多主架构,任何节点都可以进行读写
· 同步复制,各节点间无延迟且节点宕机不会导致数据丢失
· 紧密耦合,所有节点均保持相同状态,节点间无不同数据
· 无需主从切换操作或使用VIP
· 热Standby,在Failover过程中无停机时间(由于不需要Failover)
· 自动节点配置,无需手工备份当前数据库并拷贝至新节点
· 支持InnoDB存储引擎
· 对应于透明,无需更改应用或是进行极小的更改
· 无需进行读写分离
Galera认证复制
Galera使用基于认证的复制,其流程如下:

其主要思想是在不出现冲突的背景下事务正常执行并持续到commit为止;当客户端发起commit命令时(此时仍然没有发生真正的commit),所有本事务内对数据库的改动与改动数据行的主键都会被搜集到一个写入集(writeset)中,该写入集随后会被复制到其他节点,该写入集会在每个节点上使用搜集到的主键进行确认性认证测试(包括被“提交”事务的当前节点)来判断该写入集是否可以被应用。如果认证测试失败,写入集会被丢弃并且原始事务会被回滚,如果认证成功,事务会被提交并且写入集会被在剩余节点进行应用。
以上的认证测试在Galera集群中的实现取决于全局事务顺序,每个事务在复制期间都会被指派一个全局顺序序列;当一个事务到达提交点时,该事务会知道当前与该事务不冲突的最新已提交事务的顺序序号,在这两个事务的全局顺序序列之间的间隔是不确定区域,在该区域间的事务相互是“看不到”对方的影响的,但所有在这间隔之间的唯物都会被进行主键冲突检测(如果发现冲突认证测试就会失败)。
Mariadb-galera-cluster最低要求是三台,也可以是两台但是必须有仲裁机,不然会出现脑裂清楚,以保证集群的正常运行最低三台服务器。
脑裂:
http://galeracluster.com/documentation-webpages/weightedquorum.html
几乎所有的candidate都告诉我们当“只有两个节点的时候,投piao算法就失效,会让2个节点去抢quorum,最先获得的节点将存活下来.” 姑且把这要理论叫做抢占论,抢占论的观点和如下描述大同小异:
在集群中,节点间通过某种机制(心跳)了解彼此的健康状态,以确保各个节点协调工作。假设只有心跳出现问题,各个节点还在正常运行,这时,每个节点都认为其他节点宕机,自己是整个机器环境中的“唯一健在者“,自己应该获得整个机器的”控制权“。在galera的集群环境中,存储设备不是共享的,这就意味着数据库的不一致,这种情况就是”脑裂“。
解决这个问题的痛楚方法就是只有投piao算法(quorum algorithm),它的算法机制如下:
1、 集群中各个节点要心跳机制来通报彼此的“健康状态“,假设每收到一个节点的”通报“则代表一piao。对于三个节点的集群,正常运行时,每个节点都会有三piao。当阶段A心跳出现故障但是节点A还在运行着,这是整个集群就会分裂成两个小的partition。节点A是一个,剩下的两个节点是一个,这就必须剔除一个partition才能保证集群的健康运行。对于三个节点的集群,A心跳出现问题后,B和C是一个partion,有两piao,A有一piao,按照投piao算法,B和C组成的集群获得控制权,A被剔除。
2、 如果有两个节点,投piao算法就失效,因为每个节点上都有一piao。这是就需要引入第三个设备:quorum Arbitrator。quorum Arbitrator通常采用一个独立的仲裁机,也可以叫仲裁人,这个仲裁机也代表一piao,单两个节点的心跳出现问题时,两个节点同时去争取仲裁人的这一piao,最早到达的请求被最先满足,故最先获得仲裁人的节点就得两piao,另一个节点被剔除。
心跳线:
galera集群需要一个法定选piao,每当一个节点不响应并且被怀疑不再是集群的一部分。您可以使用evs.suspect_timeout参数微调这种没有响应超时。默认设置为5秒。
如果你想监控的加莱拉集群节点状态的调查中wsrep_local_state状态变量或通过通知命令。
另请参见有关监控群集节点的状态的详细信息,请参阅监视集群的章节。
群集节点决定从连接收到一个网络数据包从节点是最后一次。您可以配置此使用evs.inactive_check_period参数多久集群检查。在检查过程中,如果群集认为自上一次接收到的网络数据包从节点的时间大于evs.keepalive_period参数的值时,它开始发射心跳信标。如果群集继续收到来自节点没有网络分组为evs.suspect_timeout参数的周期,节点被声明嫌疑。一旦主要成分的所有成员看到该节点作为犯罪嫌疑人,先声明不活跃,也就是失败。
如果从节点收到一段大于evs.inactive_timeout期间没有消息,该节点被宣布失败不管共识。失败的节点仍然非经营性,直到所有成员都同意在其会员资格。如果成员不能在一个节点的活跃度达成共识,网络太不稳定的群集操作。
这些选项值之间的关系是:
evs.keepalive_period≤evs.inactive_check_period
evs.inactive_check_period≤evs.suspect_timeout
evs.suspect_timeout≤evs.inactive_timeout
evs.inactive_timeout≤evs.consensus_timeout
需要注意的是未能按时 - 例如发送消息或心跳信标节点无响应,重的情况下交换,也可以读失败。这样可以防止它们从锁定集群的其余部分的操作。如果您发现这种行为不可取,增加超时参数。
集群状态和数据还原
[root@client137 ~]# /etc/init.d/mysql start
等所有服务器都加入集群,查询集群状态![]()

三、ebuick数据集群还原
1、从正式环境中拷贝备份文件(使用xtrabackup备份)
2、进行还原(使用xtrabackup备份和还原)
步骤(在每台服务器上都这样操作)
停止集群并还原数据库,首先注释掉集群参数,如下
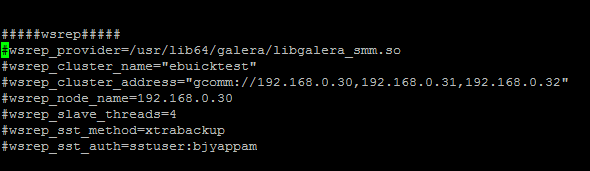
停止数据库实现单实例
#service mysql stop
使用innobackup还原数据库并停止数据库
#service mysql stop
#rm -rf /var/lib/mysql/*
#innobackup --apply-log /opt/base-2015-08-11-10-25-37
#innobackup --copy-back /opt/base-2015-08-11-10-25-37
#chown -R mysql:mysql /var/lib/mysql
#chmod -R 755 /var/lib/mysql
修改配置文件,取消点刚才添加的# 注释
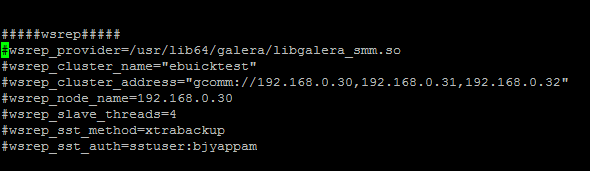
然后启动第一台时如下
#service mysql start --wsrep-cluster-address="gcomm://"
启动另外两台直接使用如下命令启动
#service mysql start
这是会有等待时间,稍等一段时间即可
然后查看每台服务器上的
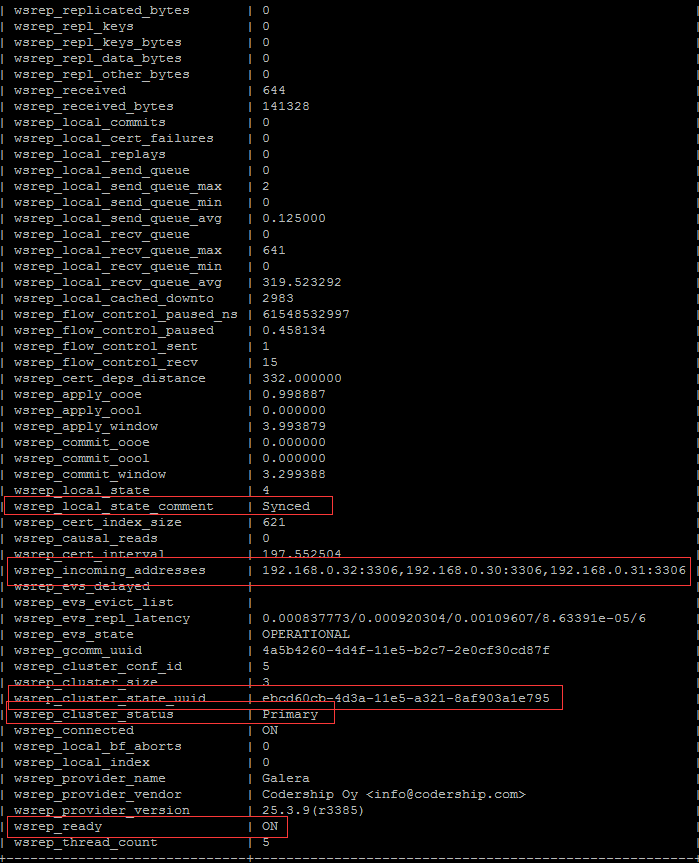
紧急处理
如果在三台服务器都断电的情况下,有可能表有page损坏,这个时候在启动的时候查看错误日志会发现有page损坏的记录,
这个时候就需要先启动单节点提供服务了,启动单节点就需要确定那台服务器是最近最少丢失数据的。
在每台服务器上查看grastate.dat文件中的seqno,启动seqno比较大的那台服务器即可。

直接启动服务器即可