设计并实现超媒体API
本文(这一系列的第二篇文章)的主题是超媒体服务器的实现。本文用到的消息设计和问题领域描述已经在之前的文章中介绍过。在本文中,我们首先会简要介绍超媒体服务器的角色(路由、评估和执行),然后会讨论它的基础实现,包括组件层、展现层和连接层。最后,我们将简要介绍一个超媒体API的客户端浏览器;特别是常见的Web浏览器和命令行工具的限制以及“媒体类型浏览器”的优点。
本文详细介绍了使用Node.js构建一个完整功能的服务器所需的高层细节信息。为了让事情相对简单一些,本文中的示例实现并没有使用其他自定义Node模块或者框架,甚至连简单的磁盘文件的存储处理都没有使用。因为本文的实现只有骨架和基础实现,所以它并不具有真实的产品级服务器所具有的所有特性和安全,但是你依然能够从中了解实现的主要技术点。同时,虽然这个服务器是使用Node.js构建的,但是将本文所介绍的思想转换成你喜欢的其他编程语言、框架和/或者平台也没有问题。
注意:
可以从GitHub上获取这个服务器实现的所有源代码。
超媒体API服务器
超媒体API服务器在基本Web服务器的基础上添加了很多功能。和常见的Web服务器一样,超媒体API服务器会接收请求、处理请求并返回响应。但是,超媒体API服务器还会执行一些其他的工作。它们就像翻译家,按照预定义的消息格式发送每一个请求,将其翻译成服务器组件(存储、数据库和业务逻辑)能够理解的内容进行处理,然后重新翻译回预定义的格式,翻译后的格式中可能包含发送请求的客户端做下一步操作所需的信息。典型的RPC类型的API服务器并不会包含这些信息。
这些额外的信息可能会包含这个客户端是否能够看到相关的资源,是否能够执行一个搜索操作,是否能够修改存储在服务器上的数据等内容。所有这一切都是基于发送请求的客户端所能理解的媒体类型设计,通过增加超媒体控制(链接和表单)通信的。客户端请求可能会和用户身份绑定到一起;该身份可能会(也可能不会)包含一些额外的特权,同时也会影响下一个请求进行时哪些内容是有效的。对响应做出的修正是上下文驱动的,这也是对超媒体类型的实现所添加的关键价值增值元素之一。
路由
在Web环境中,一个API服务器的首要任务是接收、解析并路由传入的请求。在设计Web API服务器时,通常会将URI作为首选方式路由到达服务器的请求。这个过程是这样的,首先将URI解析成路径片段和查询字符串等内容,然后使用这些信息将请求的详细内容(包括可能的请求体数据)发送到正确的内部组件进行处理。
例如下面的HTTP请求:
GET/users/?search=pending Host: http://www.example.org Accept: application/vnd.collection+json Authorization: q1w2e3r4t5=
这个请求的第一部分告诉服务器一个客户端想要执行一个“读”操作,它要搜索www.example.org服务器上被挂起的用户。客户端请求的第二部分表明响应的数据应该是collection+json格式的(一种已注册的超媒体类型)。请求的最后一部分表示该请求是由一个经过授权的用户发出的,可以通过授权头中的加密值鉴别该用户。
服务器通常会将URI分解为不同的部分:
- users
- search=pending
然后会生成一个有效的请求发送给对应的内部组件处理:
results = Users.Search('pending');
处理结果会被转换成被请求的格式并发送回客户端:
http.Response = Representation(results, 'collection+json');
上面的例子使用的是伪代码,但是你能从中体会到基础思路。API服务器接收、路由并处理请求,然后创建符合格式的结果返回给客户端。
评估和执行
请求处理包括评估请求(不仅仅是URI,还包括协议的详细内容,例如方法、额外的头以及任何有效负载)和决定为了完成该请求需要执行哪一个内部程序。在之前的示例中,服务器“明确了”/users/?search=pending 表示服务器应当将“pending“查询字符串参数传递给User 模块的 Search函数。同时服务器还根据客户端请求中的Accept 头信息明确了要将响应格式转化成collection+json格式。
服务器实际上是外部世界(也就是HTTP)和自身内部组件(也就是任何源码或者正在使用的本地网络语言)之间沟通的桥梁。服务器的角色是评估请求,将其转换成“组件能懂的语言”,然后将响应转化成合适的格式。这让服务器扮演了外部世界和内部组件之间 “连接器”的角色。
注意:
Roy Fielding在描述REST风格的Web架构时引用了这个“组件——连接器”模型。
在很多实现中,组件(内部的)和连接器(外部的)的任务会混合在一起。长期来看,这种关注点的混合会让服务器难以维护和演化。因此,本文所展示的实现模式将会强调组件和连接器之间的区别。另外,你还将看到另一个被识别的责任作为单独的关注点,那就是为响应生成内部数据的展现。
组件层
组件层就是解决领域问题的地方,以前并没有人按照同样的方式做过这些事情。这里的工作通常也与HTTP或者Web没有关系。例如,读取并将数据写入存储,计算与业务相关的公式,强制执行业务规则等等。这些都是组件的基本活动。
领域特定的独立实现
这一系列的前一篇文章所处理的领域问题是排课系统。该系统管理学生、老师和课程,同时将这三者联合起来形成排课表。这些都是存在于组件层的领域特定细节。为了实现相关功能,我们实现了一个模块(称为component.js)处理这些工作。同时,为了处理相关的读写操作,我们还使用了一个简单的基于文件的存储模块(称为storage.js)。
这两个模块(storage.js和component.js)的实现中并不会有任何有关于连接器(例如HTTP、WebSockets等)细节的内容。我们的例子虽小,但即使在大系统中也应该是组件层包含目标领域(本示例中是课程表领域)特定的细节。该层通常是你的实现中的增值点,确实没有人会以完全相同的方式实现这一部分。
在组件层和系统剩余部分之间实现关注点分离(SoC)还能够提升将来以最低的成本添加新连接器(FTP、SMTP等)的机会。此外,这样做还能够在不影响组件的情况下实现连接器层(缓存、服务器数量的横向扩展能力等)的优化。
Storage.js
在本示例中,数据存储是以一个简单文件系统的方式实现的。而在产品实现时则很有可能会使用结构化存储实现,例如文档型数据库(MongoDB、CouchDB等),关系型数据库(MySQL、Oracle、SQL Server等),或者一些其他的存储系统。甚至有可能会使用HTTP连接器通过一个远程的存储模型实现。
下面是一个代码片段,它展示了在我们的示例应用中存储是如何实现的:
var fs = require('fs');
var folder = process.cwd()+'/data/';
module.exports = main;
function main(object, action, arg1, arg2) {
var rtn;
switch (action) {
case 'list':
rtn = getList(object);
break;
case 'filter':
rtn = getList(object, arg1);
break;
case 'item':
rtn = getItem(object, arg1);
break;
case 'add':
rtn = addItem(object, arg1);
break;
case 'update':
rtn = updateItem(object, arg1, arg2);
break;
case 'remove':
rtn = removeItem(object, arg1);
break;
default:
rtn = null;
break;
}
return rtn;
}
注意:
可以从GitHub上获取这个服务器实现的完整源码。
下面是 addItem 方法的详细内容:
function addItem(object, item) {
item.id = makeId();
item.dateCreated = new Date();
fs.writeFileSync(folder+object+'/'+item.id, JSON.stringify(item));
return getItem(object, item.id);
}
下面是一个将一条真实的student记录存储到磁盘上的示例:
{
studentName: "Mark Bunce",
standing: "sophomore",
id: "121drdhk3xh",
dateCreated: "2013-01-26T01:47:01.057Z"
}
总的来说,JSON对象会使用由makeId()程序创建的唯一名称被存储到磁盘上。接下来我们将回顾component.js模块,并将介绍它如何调用存储模块。
Component.js
在这个示例应用中,component.js模块会处理所有的领域层细节。该模块清楚自己如何与存储沟通,如何转换“Add Student”和“Assign Student to a class”这样的服务请求。在一个较大的系统中,组件层可能会包含一些模块,但是它们依然会做同样的基础类型的工作。
除了存储处理之外,组件层还负责解决方案的业务逻辑处理。在我们的示例中,源代码位于一个单独的模块(component.js),但是在更大更完整的系统中,你很有可能会有多个组件,每一个组件处理业务逻辑的不同方面。
下面是一段实现排课信息处理业务逻辑的高层代码:
exports.schedule = function(action, args1, args2) {
var object, rtn;
object = 'schedule';
rtn = null;
switch(action) {
case 'list':
rtn = loadList(storage(object, 'list'), object);
rtn = addEditing(rtn, object, args1);
break;
case 'read':
rtn = loadList(storage(object, 'item', args1), object);
rtn = addEditing(rtn, object, args1);
break;
case 'add':
rtn = loadList(storage(object, 'add', args1), object);
rtn = addEditing(rtn, object, args1);
break;
case 'update':
rtn = loadList(storage(object, 'update', args1, args2), object);
rtn = addEditing(rtn, object, args1);
break;
case 'remove':
rtn = loadList(storage(object, 'remove', args1), object);
rtn = addEditing(rtn, object, args1);
break;
case 'assign':
appendStudent(args1, args2);
rtn = loadList(storage(object, 'item', args1), object);
rtn = addEditing(rtn, object, args1);
break;
case 'unassign':
dropStudent(args1, args2);
rtn = loadList(storage(object, 'item', args1), object);
rtn = addediting(rtn, object, args1);
break;
default:
rtn = null;
}
return rtn;
}
注意:
可以从GitHub上获取该服务器实现的完整源码。
下面是appendStudent 函数的实现:
function appendStudent(skid, stid) {
var schedule, student, coll, i, x, flg;
schedule = storage('schedule', 'item', skid);
student = storage('student', 'item', stid);
flg = false;
// make sure there's a collection
if(!schedule.students) {
schedule.students = [];
}
// see if this student already exists
coll = schedule.students;
for(i=0, x=coll.length; i<x; i++) {
if(coll[i].id===student.id) {
flg = true;
}
}
// add it if needed
if(flg===false) {
coll.push(student);
schedule.students = coll;
}
// save results
storage('schedule', 'update', skid, schedule);
}
最后,下面这段程序能够将来自于存储的一条或者多条记录的列表处理成一个内部对象图。该系统中所有组件级别的程序都能够理解这种格式。
function loadList(elm, name) {
var coll, list, data, item, i, x;
if(Array.isArray(elm)===false) {
coll = [];
coll.push(elm);
}
else {
coll = elm;
}
item = [];
data = [];
for(i=0, x=coll.length; i<x; i++) {
for(prop in coll[i]) {
d = {};
d.name = prop;
d.value = coll[i][prop];
d.prompt = prop;
data.push(d);
}
item[i] = {};
item[i].name = name;
item[i].display = {};
item[i].display.data = data;
data = [];
}
list = {};
list.name = name;
list.item = item;
return list;
}
注意,组件层并没有“谈到”HTTP或者XML,因为它们是被分开处理的。组件层仅需要能够实现内部的业务需求,并且能够与存储服务(本地的或者远程的)沟通即可。但是,在合适的时候组件层也可能会包含一些链接。在我们的实现中,它们将如何渲染的工作交给了下一个元素:表现层。
表现层
HTTP是一个与众不同的协议,因为它被设计为能够允许同样的数据按照不同的格式进行展现,称为媒体类型。这些媒体类型意义明确,并且(通常)会在一个标准机构(IANA,互联网数字分配机构)中注册。客户端和服务器都清楚数据和事务详细信息是如何表示的,因此对客户端(例如一个感知HTML的Web浏览器)而言,它能成功地与新发现的服务进行通信。
聚焦媒体类型
客户端和服务器之间共享的不仅仅是协议语义,还有消息语义。例如,HTML中的A、LINK、FORM和INPUT元素都表明了转换细节。在本系列的前一篇文章中,我们设计了一个自定义的超媒体类型(application/TK)。在那个设计中有LINK、ACTION和DATA元素需要转换。展现层的责任就是将来自于内部存储的信息和私有组件层的操作转换成公共展现,客户端和服务器都理解的展现。
这需要聚焦于消息本身——在客户端和服务器之间使用媒体类型作为主要“共识”是超媒体系统的重要特性之一。借助于媒体类型,客户端和服务器之间进行交流时不需要知道编程语言(Ruby、Python、PHP、Node等),编码风格(面向对象的、函数式的、过程式的),甚至不需要知道各部分使用的操作系统。
领域特定信息的转换
展现层的工作非常重要。它们接收来自于公共连接器的请求(相关内容将会在下一部分介绍),然后将其分配给私有组件层,它们是这两个世界之间的翻译官。
Representation.js
在这个示例实现中,我们在一个单独的模块中封装了展现层,称为representation.js。该模块能够“讲”application/TK。
下面是一段高层代码,该代码会“处理”由组件层提供的内部对象模型,将其转换成公共排课超媒体类型。
function processCSDoc(object) {
var doc, i, x, tmp, coll;
doc += '<root>';
// handle action element
if(object && object.action) {
doc += actionElement(object.action);
}
// handle lists
if(object && object.list) {
for(i=0,x=object.list.length; i<x;i++) {
doc += listElement(object.list[i]);
}
}
// handle error
if(object && object.error) {
doc += '<error>';
coll = object.error.data;
for(i=0, x=coll.length; i<x; i++) {
doc += dataElement(coll[i]);
}
doc += '</error>';
}
doc += '</root>';
return doc;
}
注意:
可以从GitHub上获取该服务器实现的完整源码。
该程序“知道”object参数所表示的对象的数据结构,它还“清楚”一个有效排课消息的结构。这段程序会将一个私有的对象图转换成一个公有的超媒体消息。
下面是dataElement程序;该程序会将私有图中的所有数据点转换成为消息中的有效数据元素。
function dataElement(data) {
var rtn;
rtn = '<data ';
if(data.name) {
rtn += 'name="'+data.name+'" ';
}
if(data.prompt) {
rtn += 'prompt="'+data.prompt+'" ';
}
if(data.value) {
rtn += 'value="'+data.value+'" ';
}
if(data.embed) {
rtn += 'embed="'+data.embed+"' ";
}
rtn += '/>';
return rtn;
}
最后,下面是一个遵循如下超媒体格式
application/vnd.apiacademy-scheduling+xml
的内部对象图的示例。
// internal object graph
{
"action":
{
"link": [
{
"name":"home",
"href":"http://localhost:1337/",
"action":"read",
"prompt":"Home"
},
{
"name":"student",
"href":"http://localhost:1337/student/",
"action":"list",
"prompt":"Students"
},
{
"name":"teacher",
"href":"http://localhost:1337/teacher/",
"action":"list",
"prompt":"Teachers"
},
{
"name":"course",
"href":"http://localhost:1337/course/",
"action":"list",
"prompt":"Courses"
},
{
"name":"schedule",
"href":"http://localhost:1337/schedule/",
"action":"list",
"prompt":"Schedules"
}
]
}
}
}
// public hypermedia message
<root>
<actions>
<link name="home"
href="http://localhost:1337/"
action="read"
prompt="Home" />
<link name="student"
href="http://localhost:1337/student/"
action="list"
prompt="Students" />
<link name="teacher"
href="http://localhost:1337/teacher/"
action="list"
prompt="Teachers" />
<link name="course"
href="http://localhost:1337/course/"
action="list"
prompt="Courses" />
<link name="schedule"
href="http://localhost:1337/schedule/"
action="list"
prompt="Schedules" />
</actions>
</root>
你可能已经注意到了,在示例中内部数据和公共数据的结构非常相似。虽然私有对象图和公共媒体类型之间的转换并不是必须的,但这样做有时确实能够让事情变得容易。无论如何,这并不是一个通用的案例;特别是在支持多种公共消息格式的系统中。此处这样做的目的是为了简化转换过程,在比较时更加容易查看和分析。
现在,展现层已经就位了,最后一步便是实现连接器层,将进入的协议请求(本例中是HTTP)转换成组件能够理解的内容,然后将展现层的工作结果返回给调用者。
连接器层
连接器层是暴露在公网上的层。它在与外界通信时使用HTTP和DNS等协议或系统,连接器作为网关,请求流和响应返回流都需要经过它。Web服务器引擎(Apache、IIS、Nginx等)是最著名的连接器类型。它们中的大部分所具有的功能不仅仅是一味地接收请求并返回响应。它们还支持一些级别的路由和脚本。这使得用户能够编写代码检查进入的请求,将其传送给合适的组件处理,并在组件处理完成后提供合适的响应。
协议层交互
连接器关注于协议层的交互。一个HTTP连接器能够理解HTTP协议的细节信息,能够让外部程序检查并操作这些信息。连接器的工作是检查进入请求的URL,验证请求头信息从而决定响应所应采用的格式,并将请求(以及所有参数)路由给合适的组件进行处理。
对于这一系列文章而言,连接器是Node.js。使用Node.js启动一个HTTP连接器是非常简单的,同时使用它提供路由,操作HTTP消息也是非常容易的。
内部世界和外部世界之间的中介
因为面对外部世界的是连接器,所以连接器的脚本处理意味着决定要接收哪些请求,哪些URL是有效的,每一个请求执行后要返回什么。这也是将问题领域(排课系统)中的内部操作映射到外部的HTTP限制。相关的大部分内容已经在该系列之前的文章中介绍过。媒体类型文档的协议映射部分将领域操作映射到HTTP方法。问题域文档设置了HTTP请求产生时应该提供哪些数据元素。这些材料提供了为我们的服务器实现连接器脚本所需的基础知识。
App.js
在本示例中,连接器代码存在于app.js模块中。这是接收HTTP请求并产生HTTP响应的地方。为了容易阅读,该示例并没有安装使用外部模块或框架。这也导致了有些代码有点“啰嗦”,但是这也意味着没有“隐藏”的特性,要理解这些示例你并不需要了解太多的Node外部模块。
该模块使用简单的正则表达式识别请求路由规则:
// routing rules
var reHome = new RegExp('^\/$','i');
var reCourse = new RegExp('^\/course\/.*','i');
var reSchedule = new RegExp('^\/schedule\/.*','i');
var reStudent = new RegExp('^\/student\/.*','i');
var reTeacher = new RegExp('^\/teacher\/.*','i');
下面的代码使用了一个上面的规则评估进入的请求,并将请求路由到合适的连接器组件。
// schedule
if(flg===false && reSchedule.test(req.url)) {
flg = true;
doc = schedule(req, res, parts, root)
}
注意:
可以从GitHub上获取该服务器实现的完整源码。
每一个路由表达式在app.js模块中都有相似的代码。
下面是排课连接器内的一段代码,它检查请求的详细信息,将其转换成一个内部的表示,然后传递给合适的组件。
function schedule(req, res, parts, base) {
var code, doc;
root = base;
switch(req.method) {
case 'GET':
if(parts[1]) {
doc = {code:200, doc:sendItem(req, res, parts[1])};
}
else {
doc = {code:200, doc:sendList(req, res)};
}
break;
case 'POST':
if(parts[1]) {
doc = errorDoc(req, res, 'Method Not Allowed', 405);
}
else {
switch(parts[0].toLowerCase()) {
case 'assign' :
doc = {code:200, doc:assignStudent(req, res)};
break;
case 'unassign' :
doc = {code:200, doc:dropStudent(req, res)};
break;
case 'schedule' :
doc = {code:200, doc:addItem(req, res)};
break;
default :
doc = errorDoc(req, res, 'Method Not Allowed', 405);
break;
}
}
break;
case 'PUT':
if(parts[1]) {
doc = {code:200,doc:updateItem(req, res, parts[1])};
}
else {
doc = utils.errorDoc(req, res, 'Method Not Allowed',405);
}
break;
case 'DELETE':
if(parts[1]) {
doc = {code:204,doc:removeItem(req, res, parts[1])};
}
else {
doc = utils.errorDoc(req, res, 'Method Not Allowed', 405);
}
default:
doc = utils.errorDoc(req, res, 'Method Not Allowed', 405);
}
return doc;
}
你能够看到,连接器检查URL,检查HTTP方法,然后将工作转交给一个能够处理传入请求的本地程序,再将结果传入组件层。
下面是一段连接器代码,它调用组件模块将一个学生分配到一个现有的班级:
function assignStudent(req, res) {
var body, doc, msg, item;
body = '';
req.on('data', function(chunk) {
body += chunk;
});
req.on('end', function() {
try {
msg = qs.parse(body);
item = component.schedule('assign', msg.scheduleId, msg.studentId);
doc = sendItem(req, res, msg.scheduleId);
}
catch(ex) {
doc = utils.errorDoc(req, res, 'Server Error', 500);
}
});
return doc;
}
最后,一旦组件完成了相关的工作便会为调用者返回一个内部的图对象,该对象必须以公共排课超媒体类型表示。
下面的代码同样来自于app.js,用于调用表示层并将结果通过HTTP返回给调用者:
// send out response
if(doc!==null) {
rtn = representation(doc.doc);
sendResponse(req, res, rtn, doc.code, doc.headers);
}
else {
sendResponse(req, res, '
', 500);
}
这就是连接器的全部代码。连接器层路由并解析请求,将其传递给合适的组件,在内部响应返回时把响应传递给展现层,最后再返回给调用者。
浏览API
在服务器启动并运行之后,你会想浏览这些API,验证各种操作,做一点探索。对于典型的Web应用程序而言,这可以通过一个常见的Web浏览器实现。之所以可以这样做是因为几乎所有的Web应用程序都将自己限定为一种单一的超媒体类型(HTML)和一些其他的标准媒体格式(CSS、JavaScript、二进制图像等)。
常见的Web浏览器是令人难以置信的精密应用。通过紧密遵循一些标准,浏览器能够成功地与任何遵循同样标准的Web服务器连接和交互。这使得发现和互操作能够同时工作。
常见Web浏览器的限制
如果服务器使用了不常见的注册媒体类型(例如Atom、HAL、Collection+JSON、Siren等),那么不能保证常见的Web浏览器能够理解它们并与服务器成功地交互。浏览器之间不会共享它们对消息中出现的超媒体控制(转换)的理解。浏览器可能“不知道”不同的转换(GET、POST、PUT、DELETE等)应该采用哪个HTTP方法。同时浏览器可能也不清楚哪种数据元素应该在本地呈现(例如图片),哪种元素应该当作导航(例如链接)。
对于我们这个仅为本系列文章而创建的基于XML的超媒体类型而言,浏览器实际上能够部分理解我们的意图。因为采用的是xml格式,所有常见的浏览器都能清晰地显示响应。甚至有些Web浏览器插件不仅能够很好地呈现XML,还能够解析它们,并且允许用户单击链接导航API。下面是一个Google Chrome浏览器的截图,在查看来自于排课服务器的响应时它就加载并运行了这样一个插件。
(单击放大图片)
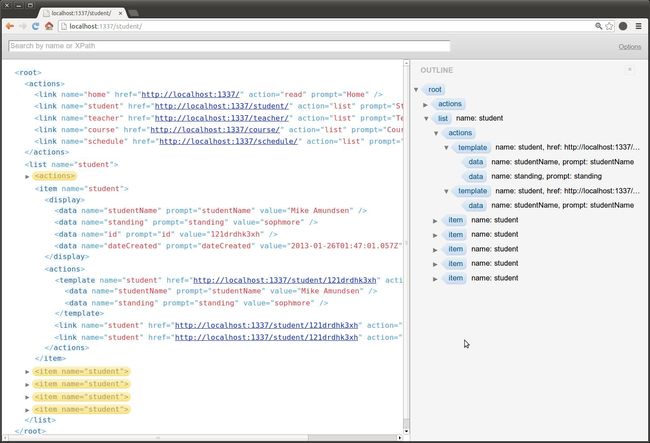
这个插件非常有用,因为我们能够通过单击响应中的链接从一个状态移动到下一个状态。但是,这并不能执行支持数据参数的转换。简单点说,就是插件不清楚如何识别和处理我们自定义媒体类型中的<template/>元素。
如果我们想要执行包含传递变量的状态转换,需要依赖于其他工具。
命令行的限制
在Web上执行参数化交互的最常见方式是命令行工具,例如CURL和WGET。实际上,API作者声称他们有一个高质量接口是很平常的,因为“你能够CURL!”。例如,下面是使用CURL为我们的服务器实现创建一条新学生记录所使用的命令。
首先是一个包含了要发送到服务器上的内容的小文件(post-student.txt):
studentName=Marius%20Wingbat&standing=junior
然后是使用CURL将这些内容发送到运行服务器上的实际命令行工具:
curl -X POST -d @post-student.txt http://localhost:1337/student/
当然,你也可以使用命令行工具从服务器端检索数据:
curl http://localhost:1337/course/
但是响应结果非常没有用(看下面的屏幕截图):
(单击放大图片)

为了让响应能够以更加容易理解的方式进行展现,可以使用命令行脚本工具将这些结果传递给解析工具处理,现有的客户端工具支持交互式超媒体体验还不是很容易。
我们需要的是混合了只读浏览器工具的交互性价值和命令行风格“可写”交互能力的东西。
媒体类型浏览器的优势
使用自定义媒体类型实现一个功能更加完整、具有浏览器风格交互式体验的一种方式是创建一个“浏览器”界面。这个界面通过一个超媒体风格的UI引导用户,这和现在常见的Web浏览器相似,同时它也提供了执行参数化转换的能力。实际上,所有超媒体风格的媒体类型都支持这种类型的体验。例如,超文本应用语言(HAL)——一种在IANA注册过的媒体类型,现在能通过它的HalTalk浏览器提供这样的体验(见下面的屏幕截图):
(单击放大图片)
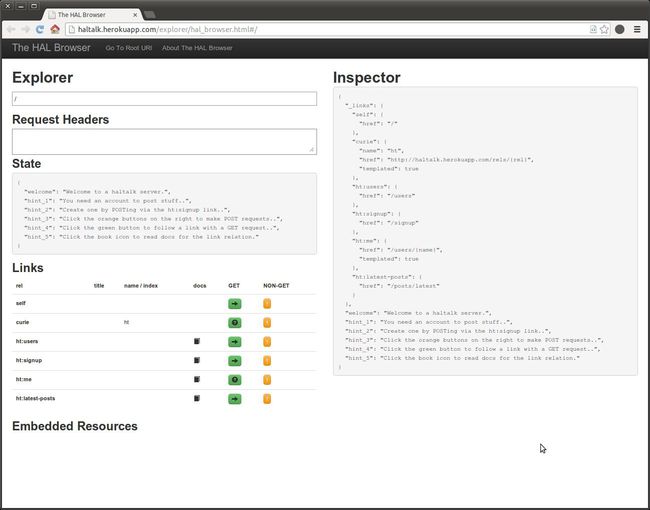
有了浏览器,人们才能够浏览“说”同样语言的任何超媒体服务器并与之交互。这可能没有达到针对这种媒体类型实现独立定制应用程序平台的层次,但是为了让这些超媒体类型可用,为了验证功能并检查新发现的服务器和API,它确实做了很多工作。
在本系列的下一篇文章中,我们将会为我们的排课媒体类型构建一个浏览器,以及其他更加常见的客户端,包括一个在运行时不需要人工干预就能够执行任务的自动机器人。
总结
在本文中我们详细介绍了如何构建一个以自定义超媒体格式为主要接口(超媒体API)的服务器。伴随着介绍的进行,我们勾勒了一个针对超媒体服务器实现的通用模型。该模型分离了私有组件和公共连接器的关注点。组件处理存储和业务逻辑。连接器负责将私有数据转换成公共格式(在本示例中是排课媒体类型),同时将请求路由到合适的内部组件。我们引入了展现层的概念,让它作为系统私有部分和公共部分之间的桥梁,这样将来在需要的时候也能够支持多种表现格式。通过将领域特定的组件和领域无关的连接器结合起来,我们为超媒体风格的服务器提供了一个稳定的、可扩展的基础。
本系列的下一篇文章将会详细介绍如何编码各种类型的超媒体客户端。这些客户端有的能够“忠实地呈现”服务器响应,有的为了建立他们自己的应用接口而维护服务器响应的“自定义视图”,有的和自动机器人一样能够在运行时没有人工干预的情况下解决特定问题。
关于作者
 Mike Amundsen是Layer 7 Technologies公司的首席API架构师,他帮助人们构建优秀的Web API。作为一名国际知名的作者和讲师,Mike穿梭于美国和欧洲之间,为分布式网络架构、Web应用开发、云计算以及其他主题提供咨询和演讲。同时他还著有十几本书。
Mike Amundsen是Layer 7 Technologies公司的首席API架构师,他帮助人们构建优秀的Web API。作为一名国际知名的作者和讲师,Mike穿梭于美国和欧洲之间,为分布式网络架构、Web应用开发、云计算以及其他主题提供咨询和演讲。同时他还著有十几本书。
提醒:
本系列文章中所讨论的服务器实现的所有源码都可以从GitHub 仓库中获取。我们鼓励读者下载这些源码并向公共仓库做出贡献或者提交评论。
查看英文原文:Designing and Implementing Hypermedia APIs